No, questo articolo non riguarda la serie americana di film d’azione fantascientifici – non c’è nessun Optimus Prime qui. Non si tratta nemmeno del dispositivo elettrico utilizzato per trasferire energia da un circuito elettrico a un altro. Di cosa si tratta allora, vi chiederete?
Si tratta di uno dei campi più fantascientifici di tutti i tempi, l’Intelligenza Artificiale – in particolare l’Elaborazione del Linguaggio Naturale, che è piuttosto ottimale per il trasferimento di informazioni e viene utilizzato in modo primario. (Vedete cosa ho fatto. :P)
Questo post si basa sul documento: Attention is All You Need. P.S. Gli autori non scherzavano quando hanno scelto questo titolo, perché per questo lavoro avrete bisogno di tutta l’attenzione a vostra disposizione. Ma non lasciatevi spaventare, ne vale davvero la pena!!!
Che cos’è un trasformatore?
Il Transformer in NLP è un’architettura innovativa che mira a risolvere compiti di sequenza-sequenza gestendo con facilità le dipendenze a lungo raggio. Si basa interamente sull’autoattenzione per calcolare le rappresentazioni dei suoi input e output SENZA utilizzare RNN allineate alla sequenza o la convoluzione. 🤯
Sto parlando arabo? Allora vi consiglio il nostro corso di introduzione al NLP in cui potrete chiarire le idee e imparare nuove cose.
Se ricordate il mio post precedente, “Capire l’attenzione nel deep learning”, abbiamo discusso come e perché molti modelli non riescono a gestire le dipendenze a lungo raggio. Il concetto di attenzione ci ha permesso in qualche modo di superare questo problema e ora in Transformers ci baseremo sull’attenzione per liberare tutto il suo potenziale.
Poche cose da sapere prima di immergersi in Transformers
Le tre parole a caso che ho appena lanciato in questo titolo sono vettori creati come astrazioni utili per calcolare l’autoattenzione; maggiori dettagli su ciascuno di essi sono riportati di seguito. Vengono calcolati moltiplicando il vettore di input (X) con le matrici di peso che vengono apprese durante l’allenamento.
– Vettore Query: q= X * Wq. È la parola corrente.
– Vettore chiave: k= X * Wk. È un meccanismo di indicizzazione per il vettore Value. Simile al modo in cui abbiamo le coppie chiave-valore nelle mappe hash, dove le chiavi sono usate per indicizzare in modo univoco i valori.
– Vettore valore: v= X * Wv. Consideratelo come l’informazione contenuta nella parola in ingresso.
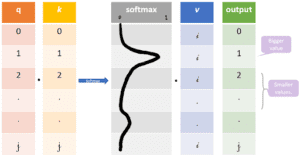
Vogliamo prendere la query q e trovare la chiave k più simile, facendo un prodotto di punti per q e k. Il prodotto query-chiave più vicino avrà il valore più alto, seguito da un softmax che porterà i q.k con valori più piccoli vicino a 0 e i q.k con valori più grandi verso 1. Questa distribuzione softmax viene moltiplicata per v. I vettori di valore moltiplicati per ~1 riceveranno più attenzione, mentre quelli ~0 ne riceveranno meno. Le dimensioni di questi vettori q, k e v sono indicate come “dimensione nascosta” da varie implementazioni.
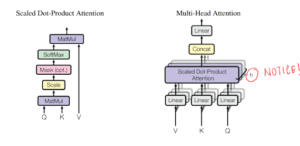
Tutte queste matrici Wq, Wk e Wv vengono apprese durante l’addestramento del modello.
Calcolo dell’autoattenzione da q, k e v:
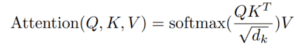
Se stiamo calcolando l’autoattenzione per #i parole in ingresso,
– Passo 1: moltiplicare qᵢ per il vettore chiave kⱼ della parola.
– Fase 2: dividere il prodotto per la radice quadrata della dimensione del vettore chiave.
Questo passaggio viene eseguito per migliorare il flusso del gradiente, che è particolarmente importante nei casi in cui il valore del prodotto del punto nel passaggio precedente è troppo grande. L’uso diretto di questi valori potrebbe spingere il softmax in regioni con un flusso di gradiente molto ridotto.
– Fase 3: Una volta ottenuti i punteggi per tutti i j, li passiamo attraverso un softmax. Otteniamo un valore normalizzato per ogni j.
– Fase 4: moltiplicare i punteggi softmax per ogni j con il vettore vᵢ.
L’idea/scopo qui è, con un’attenzione molto simile, di mantenere solo i valori v delle parole in ingresso su cui vogliamo concentrarci moltiplicandoli con i punteggi ad alta probabilità di softmax ~1, e di rimuovere il resto portandoli verso 0, cioè rendendoli molto piccoli moltiplicandoli con i punteggi a bassa probabilità ~0 di softmax.

⚠️ Una parola di cautela: il contenuto di questa immagine può sembrare esponenzialmente più complicato di quanto non sia. Scomporremo questa bestia spaventosa in piccole bestiole e tutto avrà un senso. (Promesso #2)
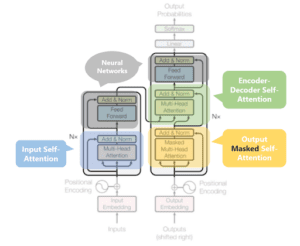
Abbiamo appena notato che l’output di ogni sottolivello deve avere la stessa dimensione, che nel nostro documento è di 512 dimensioni.
=> zᵢ deve essere di 512 dimensioni.
=> vᵢ deve avere 512 dimensioni, poiché zᵢ è una sorta di somma pesata di vᵢ.
Inoltre, vogliamo permettere al modello di concentrarsi su posizioni diverse calcolando l’autoattenzione più volte con diverse serie di vettori q, k e v, per poi fare una media di tutti questi risultati e ottenere lo z finale.
Quindi, invece di gestire questi vettori enormi e di fare la media di più risultati, riduciamo la dimensione dei nostri vettori k, q e v a una dimensione più piccola – riducendo anche la dimensione delle matrici Wq, Wk e Wv. Manteniamo gli insiemi multipli (h) di k, q e v e ci riferiamo a ciascun insieme come a una “testa di attenzione”, da cui il nome di attenzione a più teste. Infine, invece di fare la media per ottenere lo z finale, li concateniamo.
La dimensione del vettore concatenato sarà troppo grande per essere inviata al sottolivello successivo, quindi la ridimensioniamo moltiplicandola con un’altra matrice appresa Wo.