
I dati non strutturati sotto forma di testo: chat, e-mail, social media, risposte a sondaggi sono presenti ovunque oggi. Il testo può essere una ricca fonte di informazioni, ma a causa della sua natura non strutturata può essere difficile estrarre informazioni da esso.
La classificazione del testo è uno dei compiti più importanti dell’apprendimento automatico supervisionato (ML). Si tratta di un processo di assegnazione di tag/categorie ai documenti che ci aiuta a strutturare e analizzare il testo in modo automatico e rapido e conveniente. È uno dei compiti fondamentali dell’elaborazione del linguaggio naturale, con ampie applicazioni come l’analisi dei sentimenti, l’individuazione dello spam, l’etichettatura dei temi, l’individuazione delle intenzioni, ecc.
In questo articolo, vorrei illustrarvi passo per passo come effettuare la classificazione del testo utilizzando Python. Ho caricato il codice completo su GitHub: https://github.com/vijayaiitk/NLP-text-classification-model
Dividiamo il problema della classificazione nei seguenti passi:
- Impostazione: Importazione delle librerie
- Caricamento del set di dati e analisi esplorativa dei dati
- Pre-elaborazione del testo
- Estrazione di vettori dal testo (vettorizzazione)
- Esecuzione di algoritmi di ML
- Conclusione
Il set di dati che utilizzeremo per questo articolo è il famoso set di dati “Natural Language Processing with Disaster Tweets”, in cui dovremo prevedere se un determinato tweet riguarda un vero disastro (target=1) o meno (target=0).
In questa gara, dovrete costruire un modello di apprendimento automatico che preveda quali tweet parlano di disastri reali e quali no. Avrete accesso a un set di dati di 10.000 tweet classificati a mano.
Caricamento del set di dati in Kaggle Notebook:
Abbiamo 7.613 tweet nel dataset di allenamento (etichettato) e 3.263 nel dataset di test (non etichettato). Ecco un’istantanea del dataset di addestramento/etichettato che utilizzeremo per costruire il nostro modello

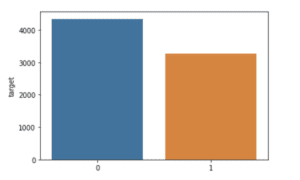
1. Distribuzione delle classi: Ci sono più tweet di classe 0 (nessun disastro) che di classe 1 (tweet di disastro). Possiamo dire che il dataset è relativamente bilanciato con 4342 tweet non catastrofici (57%) e 3271 tweet catastrofici (43%). Poiché i dati sono bilanciati, non applicheremo tecniche di bilanciamento dei dati come SMOTE durante la costruzione del modello.
2. Valori mancanti: Abbiamo ~2,5k valori mancanti nel campo della località e 61 valori mancanti nella colonna delle parole chiave.df_train.isna().sum()

3. Numero di parole in un tweet: I tweet relativi alle catastrofi sono più prolissi di quelli non relativi alle catastrofi.
Il numero medio di parole in un tweet di una catastrofe è di 15,17 rispetto a una media di 14,7 parole in un tweet non di una catastrofe.
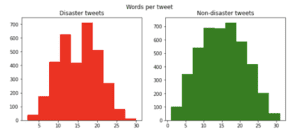
4. Numero di caratteri in un tweet: I tweet relativi alle catastrofi sono più lunghi di quelli non relativi alle catastrofi.
La media dei caratteri di un tweet in caso di catastrofe è di 108,1 caratteri rispetto alla media di 95,7 caratteri di un tweet senza catastrofe.
Prima di passare alla costruzione del modello, dobbiamo preprocessare il nostro set di dati rimuovendo punteggiature e caratteri speciali, pulendo i testi, rimuovendo le stop words e applicando la lemmatizzazione.
Semplici processi di pulizia del testo: Alcuni dei più comuni processi di pulizia del testo prevedono:
– rimozione di punteggiatura, caratteri speciali, URL e hashtag
– Rimozione di spazi bianchi e tabulati in testa e in coda.
– Correzione degli errori di battitura e degli slang, scrittura delle abbreviazioni nella loro forma lunga.
Rimozione delle stop-word: Con nltk possiamo rimuovere dal vocabolario inglese un elenco di stop words generiche. Alcune di queste parole sono ‘i’, ‘you’, ‘a’, ‘the’, ‘he’, ‘which’ ecc.
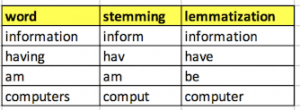
Stemmatizzazione: Si riferisce al processo di taglio della fine o dell’inizio delle parole con l’intento di rimuovere gli affissi (prefisso/suffisso).
Lemmatizzazione: È il processo di riduzione della parola alla sua forma base.
Ecco il codice per la pre-elaborazione del testo:

È difficile lavorare con i dati di testo quando si costruiscono modelli di apprendimento automatico, poiché questi modelli hanno bisogno di dati numerici ben definiti. Il processo di conversione dei dati testuali in dati numerici/vettoriali è chiamato vettorizzazione o, nel mondo della PNL, word embedding. Bag-of-Words (BoW) e Word Embedding (con Word2Vec) sono due metodi ben noti per convertire i dati di testo in dati numerici.
Esistono diverse versioni di Bag of Words, che corrispondono a diversi metodi di scoring delle parole. Utilizziamo la libreria Sklearn per calcolare i valori numerici di BoW utilizzando questi approcci:
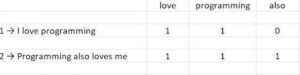
1. Vettori di conteggio: Costruisce un vocabolario a partire da un corpus di documenti e conta quante volte le parole appaiono in ogni documento.
2. Frequenza dei termini – Frequenze inverse dei documenti (tf-Idf): I vettori di conteggio potrebbero non essere la rappresentazione migliore per convertire i dati di testo in dati numerici. Quindi, invece del semplice conteggio, possiamo usare una variante avanzata del Bag-of-Words che utilizza la frequenza di termine inversa alla frequenza del documento (o Tf-Idf). In pratica, il valore di una parola aumenta proporzionalmente al conteggio nel documento, ma è inversamente proporzionale alla frequenza della parola nel corpus.
Word2Vec: Uno dei principali svantaggi dell’uso delle tecniche Bag-of-words è che non è in grado di catturare il significato o la relazione delle parole dai vettori. Word2Vec è una delle tecniche più diffuse per apprendere gli incorporamenti di parole utilizzando una rete neurale superficiale che è in grado di catturare il contesto di una parola in un documento, la somiglianza semantica e sintattica, la relazione con altre parole, ecc.
Possiamo utilizzare uno qualsiasi di questi approcci per convertire i nostri dati testuali in forma numerica che verrà utilizzata per costruire il modello di classificazione. Tenendo conto di ciò, per prima cosa suddividerò il set di dati in un set di allenamento (80%) e in un set di test (20%) utilizzando il codice seguente
È il momento di addestrare un modello di apprendimento automatico sul set di dati vettoriali e di testarlo. Ora che abbiamo convertito i dati testuali in dati numerici, possiamo eseguire modelli di ML su X_train_vector_tfidf e y_train. Testiamo questo modello su X_test_vectors_tfidf per ottenere y_predict e valutare ulteriormente le prestazioni del modello.
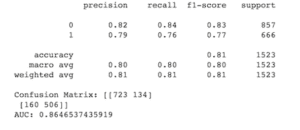
1. Regressione logistica: Inizieremo con il modello più semplice, la Regressione logistica. È possibile costruire facilmente una Regressione logistica in scikit utilizzando le seguenti righe di codice
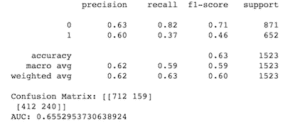
2. Naive Bayes: è un classificatore probabilistico che fa uso del Teorema di Bayes, una regola che utilizza la probabilità per fare previsioni basate sulla conoscenza preventiva di condizioni che potrebbero essere collegate
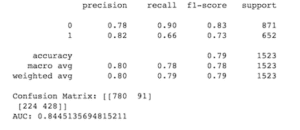
È ora possibile selezionare il modello migliore (lr_tfidf nel nostro caso) per stimare i valori “target” per il set di dati non etichettati (df_test). Ecco il codice per farlo

Predicted target value for unlabelled dataset
