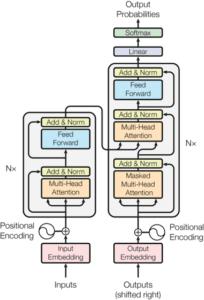
Lo schema sopra mostra la panoramica del modello Transformer. Gli ingressi al codificatore sarà la frase inglese, e il ‘Uscite’ entrare nel decodificatore sarà la frase francese.
In effetti, ci sono cinque processi che dobbiamo capire per implementare questo modello:
- Integrazione degli ingressi
- Le codifiche posizionali
- Creazione di maschere
- Lo strato di attenzione multi-testa
- Il livello di avanzamento
Affinché il modello abbia senso di una frase, ha bisogno di sapere due cose su ogni parola: cosa significa la parola? E qual è la sua posizione nella frase?
Il vettore di incorporamento per ogni parola imparerà il significato, quindi ora dobbiamo inserire qualcosa che dica alla rete la posizione della parola.
Vasmari et al hanno risposto a questo problema usando queste funzioni per creare una costante dei valori posizione-specifici:
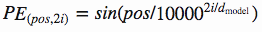
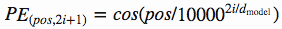
Questa costante è una matrice 2d. Pos si riferisce all’ordine nella frase, e indica la posizione lungo la dimensione vettoriale di incorporazione. Ogni valore nella matrice pos/i viene poi elaborato utilizzando le equazioni sopra riportate.
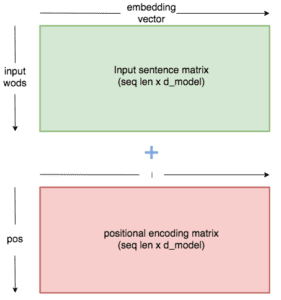
***La matrice di codifica posizionale è una costante i cui valori sono definiti dalle equazioni di cui sopra. Quando viene aggiunto alla matrice di inclusione, ogni parola viene modificata in un modo specifico per la sua posizione.
Un modo intuitivo di codificare il nostro encoder posizionale è il seguente:
class PositionalEncoder(nn.Module):
def __init__(self, d_model, max_seq_len = 80):
super().__init__()
self.d_model = d_model
# create constant 'pe' matrix with values dependant on
# pos and i
pe = torch.zeros(max_seq_len, d_model)
for pos in range(max_seq_len):
for i in range(0, d_model, 2):
pe[pos, i] = \
math.sin(pos / (10000 ** ((2 * i)/d_model)))
pe[pos, i + 1] = \
math.cos(pos / (10000 ** ((2 * (i + 1))/d_model)))
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
# make embeddings relatively larger
x = x * math.sqrt(self.d_model)
#add constant to embedding
seq_len = x.size(1)
x = x + Variable(self.pe[:,:seq_len], \
requires_grad=False).cuda()
return x
Il modulo precedente ci consente di aggiungere la codifica posizionale al vettore di incorporamento, fornendo informazioni sulla struttura del modello.
Il motivo per cui aumentiamo i valori di incorporazione prima dell’aggiunta è per rendere la codifica posizionale relativamente più piccola. Questo significa che il significato originale nel vettore di incorporazione non sarà perso quando li aggiungiamo insieme.
Il mascheramento svolge un ruolo importante nel trasformatore. Ha due scopi:
- Nel codificatore e decodificatore: A zero uscite attenzione ovunque ci sia solo padding nelle frasi di input.
Nel decodificatore: Per evitare che il decoder ‘picco’ avanti al resto della frase tradotta quando predire la parola successiva.
Creare la maschera per l’input è semplice:
batch = next(iter(train_iter)) input_seq = batch.English.transpose(0,1) input_pad = EN_TEXT.vocab.stoi['<pad>']# creates mask with 0s wherever there is padding in the input input_msk = (input_seq != input_pad).unsqueeze(1)
Per l’obiettivo facciamo lo stesso, ma poi creiamo un passo aggiuntivo:
# create mask as beforetarget_seq = batch.French.transpose(0,1)
target_pad = FR_TEXT.vocab.stoi['<pad>']
target_msk = (target_seq != target_pad).unsqueeze(1)size = target_seq.size(1) # get seq_len for matrixnopeak_mask = np.triu(np.ones(1, size, size),
k=1).astype('uint8')
nopeak_mask = Variable(torch.from_numpy(nopeak_mask) == 0)target_msk = target_msk & nopeak_mask
L’input iniziale nel decoder sarà la sequenza di destinazione (la traduzione francese). Il modo in cui il decodificatore predice ogni parola di output è facendo uso di tutte le uscite encoder e la frase francese solo fino al punto di ogni parola la sua previsione.
Quindi dobbiamo evitare che le prime previsioni di output possano vedere più avanti nella frase. Per questo usiamo la maschera nopeak_mask:
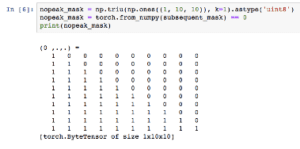
***Quando la maschera viene applicata nella nostra funzione di attenzione, ogni previsione sarà in grado di utilizzare la frase solo fino a quando la parola che sta predicendo.
Se in seguito applichiamo questa maschera ai punteggi di attenzione, i valori ovunque l’input sia avanti non saranno in grado di contribuire al calcolo degli output.
Una volta che abbiamo i nostri valori incorporati (con le codifiche posizionali) e le nostre maschere, possiamo iniziare a costruire gli strati del nostro modello.
Ecco una panoramica dello strato di attenzione a più teste:
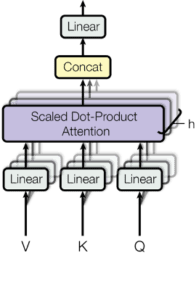
***Livello di attenzione multi-teste, ogni ingresso è diviso in più teste che permette alla rete di partecipare contemporaneamente a diverse sottosezioni di ogni incorporamento.
V, K e Q stanno per 'chiave', 'valore' e 'query'. Questi sono termini usati nelle funzioni di attenzione, ma onestamente, non credo che spiegare questa terminologia sia particolarmente importante per capire il modello. Nel caso dell'Encoder, V, K e G saranno semplicemente copie identiche del vettore di inclusione (più codifica posizionale). Avranno le dimensioni Batch_size * seq_len * d_model. Nell'attenzione multi-testa dividiamo il vettore di incorporamento in teste N, in modo che abbiano le dimensioni batch_size * N * seq_len * (d_model / N). Questa dimensione finale (d_model / N ) ci riferiremo a d_k. Vediamo il codice per il modulo decoder: class MultiHeadAttention(nn.Module): def __init__(self, heads, d_model, dropout = 0.1): super().__init__() self.d_model = d_model self.d_k = d_model // heads self.h = heads self.q_linear = nn.Linear(d_model, d_model) self.v_linear = nn.Linear(d_model, d_model) self.k_linear = nn.Linear(d_model, d_model) self.dropout = nn.Dropout(dropout) self.out = nn.Linear(d_model, d_model) def forward(self, q, k, v, mask=None): bs = q.size(0) # perform linear operation and split into h heads k = self.k_linear(k).view(bs, -1, self.h, self.d_k) q = self.q_linear(q).view(bs, -1, self.h, self.d_k) v = self.v_linear(v).view(bs, -1, self.h, self.d_k) # transpose to get dimensions bs * h * sl * d_model k = k.transpose(1,2) q = q.transpose(1,2) v = v.transpose(1,2)# calculate attention using function we will define next scores = attention(q, k, v, self.d_k, mask, self.dropout) # concatenate heads and put through final linear layer concat = scores.transpose(1,2).contiguous()\ .view(bs, -1, self.d_model) output = self.out(concat) return output
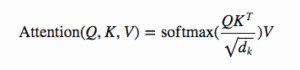
***Equazione per calcolare l’attenzione
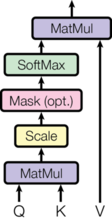
***Diagramma da carta illustrando passi equazione
Questa è l’unica altra equazione che prenderemo in considerazione oggi, e questo diagramma dal documento fa un lavoro di dio a spiegare ogni passo.
Ogni freccia nel diagramma riflette una parte dell’equazione.
Inizialmente dobbiamo moltiplicare Q per il transpose di K. Questo viene poi ‘scalato’ dividendo l’output per la radice quadrata di d_k.
Un passo che non è mostrato nell’equazione è l’operazione di mascheramento. Prima di eseguire Softmax, applichiamo la nostra maschera e quindi riduciamo i valori dove l’input è padding (o nel decoder, anche dove l’input è davanti alla parola corrente).
Un altro passo non mostrato è l’abbandono, che applicheremo dopo Softmax.
Infine, l’ultimo passo è fare un punto prodotto tra il risultato finora e V.
Ecco il codice per la funzione attenzione:
def attention(q, k, v, d_k, mask=None, dropout=None): scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)if mask is not None: mask = mask.unsqueeze(1) scores = scores.masked_fill(mask == 0, -1e9)scores = F.softmax(scores, dim=-1) if dropout is not None: scores = dropout(scores) output = torch.matmul(scores, v) return output
La normalizzazione è molto importante nelle reti neurali profonde. Impedisce che l’intervallo di valori negli strati cambi troppo, il che significa che il modello si allena più velocemente e ha una migliore capacità di generalizzare.
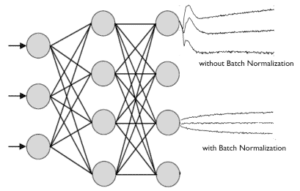
Normalizzeremo i nostri risultati tra ogni livello nell’encoder/decoder, quindi prima di costruire il nostro modello definiamo quella funzione:
class Norm(nn.Module): def __init__(self, d_model, eps = 1e-6): super().__init__() self.size = d_model # create two learnable parameters to calibrate normalisation self.alpha = nn.Parameter(torch.ones(self.size)) self.bias = nn.Parameter(torch.zeros(self.size)) self.eps = eps def forward(self, x): norm = self.alpha * (x - x.mean(dim=-1, keepdim=True)) \ / (x.std(dim=-1, keepdim=True) + self.eps) + self.bias return norm
Se capisci i dettagli di cui sopra, ora capisci il modello. Il resto è semplicemente mettere tutto a posto.
Diamo un’altra occhiata all’architettura generale e iniziamo a costruire:
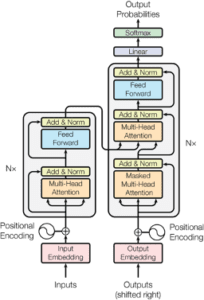
Un’ultima variabile: Se si guarda il diagramma da vicino si può vedere un’Nx’ accanto alle architetture encoder e decoder. In realtà, l’encoder e il decoder nel diagramma sopra rappresentano uno strato di un encoder e uno del decoder. N è la variabile per il numero di livelli che ci sarà. Ad esempio. se N=6, i dati passano attraverso sei livelli di encoder (con l’architettura vista sopra), quindi questi output vengono passati al decoder che consiste anche di sei livelli di decoder ripetitivi.
Ora costruiremo i moduli EncoderLayer e DecoderLayer con l’architettura mostrata nel modello precedente. Poi quando costruiamo l’encoder e il decoder possiamo definire quanti di questi livelli avere.
# build an encoder layer with one multi-head attention layer and one # feed-forward layerclass EncoderLayer(nn.Module): def __init__(self, d_model, heads, dropout = 0.1): super().__init__() self.norm_1 = Norm(d_model) self.norm_2 = Norm(d_model) self.attn = MultiHeadAttention(heads, d_model) self.ff = FeedForward(d_model) self.dropout_1 = nn.Dropout(dropout) self.dropout_2 = nn.Dropout(dropout) def forward(self, x, mask): x2 = self.norm_1(x) x = x + self.dropout_1(self.attn(x2,x2,x2,mask)) x2 = self.norm_2(x) x = x + self.dropout_2(self.ff(x2)) return x # build a decoder layer with two multi-head attention layers and # one feed-forward layerclass DecoderLayer(nn.Module): def __init__(self, d_model, heads, dropout=0.1): super().__init__() self.norm_1 = Norm(d_model) self.norm_2 = Norm(d_model) self.norm_3 = Norm(d_model) self.dropout_1 = nn.Dropout(dropout) self.dropout_2 = nn.Dropout(dropout) self.dropout_3 = nn.Dropout(dropout) self.attn_1 = MultiHeadAttention(heads, d_model) self.attn_2 = MultiHeadAttention(heads, d_model) self.ff = FeedForward(d_model).cuda()def forward(self, x, e_outputs, src_mask, trg_mask): x2 = self.norm_1(x) x = x + self.dropout_1(self.attn_1(x2, x2, x2, trg_mask)) x2 = self.norm_2(x) x = x + self.dropout_2(self.attn_2(x2, e_outputs, e_outputs, src_mask)) x2 = self.norm_3(x) x = x + self.dropout_3(self.ff(x2)) return x# We can then build a convenient cloning function that can generate multiple layers:def get_clones(module, N): return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
Ora siamo pronti per costruire il codificatore e decoder:
class Encoder(nn.Module): def __init__(self, vocab_size, d_model, N, heads): super().__init__() self.N = N self.embed = Embedder(vocab_size, d_model) self.pe = PositionalEncoder(d_model) self.layers = get_clones(EncoderLayer(d_model, heads), N) self.norm = Norm(d_model) def forward(self, src, mask): x = self.embed(src) x = self.pe(x) for i in range(N): x = self.layers[i](x, mask) return self.norm(x) class Decoder(nn.Module): def __init__(self, vocab_size, d_model, N, heads): super().__init__() self.N = N self.embed = Embedder(vocab_size, d_model) self.pe = PositionalEncoder(d_model) self.layers = get_clones(DecoderLayer(d_model, heads), N) self.norm = Norm(d_model) def forward(self, trg, e_outputs, src_mask, trg_mask): x = self.embed(trg) x = self.pe(x) for i in range(self.N): x = self.layers[i](x, e_outputs, src_mask, trg_mask) return self.norm(x)
E infine… Il trasformatore!
class Transformer(nn.Module): def __init__(self, src_vocab, trg_vocab, d_model, N, heads): super().__init__() self.encoder = Encoder(src_vocab, d_model, N, heads) self.decoder = Decoder(trg_vocab, d_model, N, heads) self.out = nn.Linear(d_model, trg_vocab) def forward(self, src, trg, src_mask, trg_mask): e_outputs = self.encoder(src, src_mask) d_output = self.decoder(trg, e_outputs, src_mask, trg_mask) output = self.out(d_output) return output# we don't perform softmax on the output as this will be handled # automatically by our loss function
Formazione del modello
Con il trasformatore costruito, non resta che allenare quel babbeo sul set di dati dell’Europarl. La parte di codifica è abbastanza indolore, ma essere pronti ad aspettare per circa 2 giorni per questo modello per iniziare convergente!
Definiamo prima alcuni parametri:
d_model = 512 heads = 8 N = 6 src_vocab = len(EN_TEXT.vocab) trg_vocab = len(FR_TEXT.vocab)model = Transformer(src_vocab, trg_vocab, d_model, N, heads)for p in model.parameters(): if p.dim() > 1: nn.init.xavier_uniform_(p)# this code is very important! It initialises the parameters with a # range of values that stops the signal fading or getting too big. # See this blog for a mathematical explanation.optim = torch.optim.Adam(model.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
E ora possiamo allenarci:
def train_model(epochs, print_every=100):
model.train()
start = time.time()
temp = start
total_loss = 0
for epoch in range(epochs):
for i, batch in enumerate(train_iter): src = batch.English.transpose(0,1)
trg = batch.French.transpose(0,1) # the French sentence we input has all words except
# the last, as it is using each word to predict the next
trg_input = trg[:, :-1]
# the words we are trying to predict
targets = trg[:, 1:].contiguous().view(-1)
# create function to make masks using mask code above
src_mask, trg_mask = create_masks(src, trg_input)
preds = model(src, trg_input, src_mask, trg_mask)
optim.zero_grad()
loss = F.cross_entropy(preds.view(-1, preds.size(-1)),
results, ignore_index=target_pad) loss.backward()
optim.step()
total_loss += loss.data[0]
if (i + 1) % print_every == 0:
loss_avg = total_loss / print_every
print("time = %dm, epoch %d, iter = %d, loss = %.3f,
%ds per %d iters" % ((time.time() - start) // 60,
epoch + 1, i + 1, loss_avg, time.time() - temp,
print_every))
total_loss = 0
temp = time.time()
![]()
Esempio di formazione uscita: Dopo alcuni giorni di formazione mi sembrava di convergere intorno a una perdita di circa 1,3
Prova del modello
Possiamo usare la funzione sottostante per tradurre le frasi. Possiamo alimentarle direttamente dai nostri lotti, o inserire stringhe personalizzate.
Il traduttore lavora eseguendo un ciclo. Iniziamo codificando la frase inglese. Quindi alimentiamo il decodificatore l’indice del token <sos> e le uscite dell’encoder. Il decodificatore fa una previsione per la prima parola, e lo aggiungiamo al nostro input decoder con il token sos. Rifacciamo il ciclo, otteniamo la previsione successiva e la aggiungiamo all’input del decoder, finché non raggiungiamo il token <Eos> facendoci sapere che ha finito di tradurre.
def translate(model, src, max_len = 80, custom_string=False):
model.eval()if custom_sentence == True:
src = tokenize_en(src)
sentence=\
Variable(torch.LongTensor([[EN_TEXT.vocab.stoi[tok] for tok
in sentence]])).cuda()src_mask = (src != input_pad).unsqueeze(-2)
e_outputs = model.encoder(src, src_mask)
outputs = torch.zeros(max_len).type_as(src.data)
outputs[0] = torch.LongTensor([FR_TEXT.vocab.stoi['<sos>']])for i in range(1, max_len):
trg_mask = np.triu(np.ones((1, i, i),
k=1).astype('uint8')
trg_mask= Variable(torch.from_numpy(trg_mask) == 0).cuda()
out = model.out(model.decoder(outputs[:i].unsqueeze(0),
e_outputs, src_mask, trg_mask))
out = F.softmax(out, dim=-1)
val, ix = out[:, -1].data.topk(1)
outputs[i] = ix[0][0]
if ix[0][0] == FR_TEXT.vocab.stoi['<eos>']:
breakreturn ' '.join(
[FR_TEXT.vocab.itos[ix] for ix in outputs[:i]]
)
E questo è tutto. Vedere il mio Github qui dove ho scritto questo codice come un programma che prenderà in due testi paralleli come parametri e addestrare questo modello su di loro. O praticare la conoscenza e implementarla da soli!
Articoli su Towards Data Science: https://medium.com/@samuellynnevans
Profilo Linkedin: https://www.linkedin.com/in/samuel-lynn-evans-23939946/
