Prima di tutto, preparerò il set di dati per la classificazione binaria.
Selezionerò esempi solo da due classi per comporre una classificazione binaria. Gli esempi verranno da classi “bus” e “Saab”. La classe “Saab” sarà sostituita dalla classe 0 e la classe “bus” sarà sostituita dalla classe 1. Il passo successivo consiste nel separare il set di dati in set di dati di formazione e test con il 60% e il 40% degli esempi di classe totali, rispettivamente.
Dopo la precedente preparazione del dataset, modelliamo una rete neurale usando tutte le funzionalità contemporaneamente e poi applichiamo il set di dati di test.
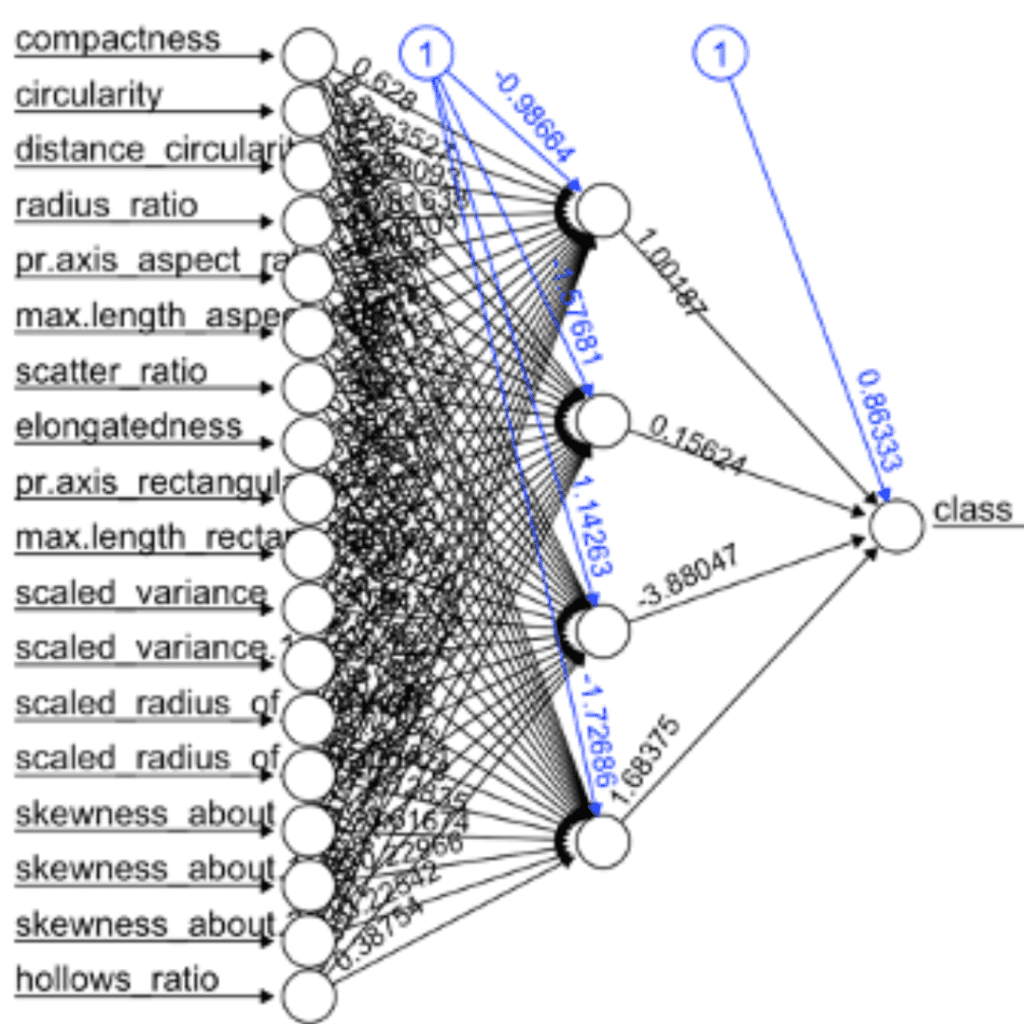
# Load library library( dplyr ) # Load dataset data = read.csv( "../dataset/vehicle.csv", stringsAsFactor = FALSE ) # Transform dataset dataset = data %>% filter( class == "bus" | class == "saab" ) %>% transform( class = ifelse( class == "saab", 0, 1 ) ) dataset = as.data.frame( sapply( dataset, as.numeric ) ) # Spliting training and testing dataset index = sample( 1:nrow( dataset ), nrow( dataset ) * 0.6, replace = FALSE ) trainset = dataset[ index, ] test = dataset[ -index, ] testset = test %>% select( -class ) # Building a neural network (NN) library( neuralnet ) n = names( trainset ) f = as.formula( paste( "class ~", paste( n[!n %in% "class"], collapse = "+" ) ) ) nn = neuralnet( f, trainset, hidden = 4, linear.output = FALSE, threshold = 0.01 ) plot( nn, rep = "best" )
# Testing the result output nn.results = compute( nn, testset ) results = data.frame( actual = test$class, prediction = round( nn.results$net.result ) ) # Confusion matrix library( caret ) t = table( results ) print( confusionMatrix( t ) )## Confusion Matrix and Statistics ## ## prediction ## actual 0 1 ## 0 79 0 ## 1 79 16 ## ## Accuracy : 0.545977 ## 95% CI : (0.4688867, 0.6214742) ## No Information Rate : 0.908046 ## P-Value [Acc > NIR] : 1 ## ## Kappa : 0.1553398 ## Mcnemar's Test P-Value : <0.0000000000000002 ## ## Sensitivity : 0.5000000 ## Specificity : 1.0000000 ## Pos Pred Value : 1.0000000 ## Neg Pred Value : 0.1684211 ## Prevalence : 0.9080460 ## Detection Rate : 0.4540230 ## Detection Prevalence : 0.4540230 ## Balanced Accuracy : 0.7500000 ## ## 'Positive' Class : 0 ##
Ora, eseguiamo l’analisi dei componenti principali sul set di dati e otteniamo gli autovalori e gli autovettori. In modo pratico, vedrete che la funzione PCA del pacchetto R fornisce un insieme di autovalori già ordinati in ordine decrescente, significa che il primo componente è quello con la più alta varianza, il secondo componente è l’autovettore con la seconda varianza più alta e così via. Il codice qui sotto mostra come scegliere gli autovettori guardando gli autovalori.
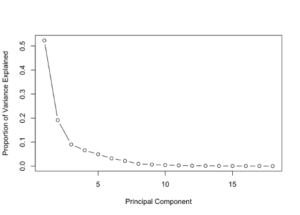
# PCA pca_trainset = trainset %>% select( -class ) pca_testset = testset pca = prcomp( pca_trainset, scale = T ) # variance pr_var = ( pca$sdev )^2 # % of variance prop_varex = pr_var / sum( pr_var ) # Plot plot( prop_varex, xlab = "Principal Component", ylab = "Proportion of Variance Explained", type = "b" )
# Scree Plot plot( cumsum( prop_varex ), xlab = "Principal Component", ylab = "Cumulative Proportion of Variance Explained", type = "b" )
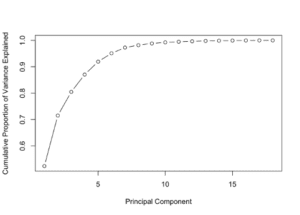
La funzione nativa R “prcomp” dai pacchetti di default stats esegue PCA, restituisce tutti gli autovalori e gli autovettori necessari. Il primo grafico mostra la percentuale di varianza di ogni caratteristica. Potete vedere che il primo componente ha la varianza più alta, un valore intorno al 50% mentre l’ottavo componente è intorno allo 0% della varianza. Quindi indica che dovremmo prendere i primi otto componenti. La seconda figura mostra un’altra prospettiva della varianza, sebbene la somma cumulativa su tutta la varianza, si può vedere che i primi otto autovalori corrispondono a circa il 98% della varianza complessiva. In effetti, è un numero abbastanza buono, significa che c’è solo il 2% delle informazioni perse. Il più grande vantaggio è che ci stiamo muovendo da uno spazio con diciotto caratteristiche ad un altro con solo otto caratteristica perdendo solo il 2% delle informazioni. Questo è il potere della riduzione dimensionale, definitivamente.
Ora che conosciamo il numero delle caratteristiche che comporranno il nuovo spazio, creiamo il nuovo set di dati e poi modelliamo di nuovo la rete neurale e controlliamo se otteniamo nuovi risultati migliori.
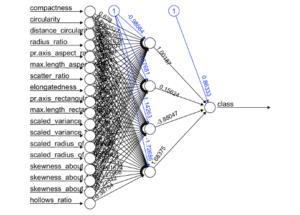
# Creating a new dataset train = data.frame( class = trainset$class, pca$x ) t = as.data.frame( predict( pca, newdata = pca_testset ) ) new_trainset = train[, 1:9] new_testset = t[, 1:8] # Build the neural network (NN) library( neuralnet ) n = names( new_trainset ) f = as.formula( paste( "class ~", paste( n[!n %in% "class" ], collapse = "+" ) ) ) nn = neuralnet( f, new_trainset, hidden = 4, linear.output = FALSE, threshold=0.01 ) # Plot the NN plot( nn, rep = "best" )
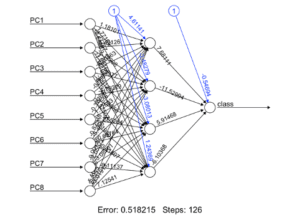
# Test the resulting output nn.results = compute( nn, new_testset ) # Results results = data.frame( actual = test$class, prediction = round( nn.results$net.result ) ) # Confusion Matrix library( caret ) t = table( results ) print( confusionMatrix( t ) )## Confusion Matrix and Statistics ## ## prediction ## actual 0 1 ## 0 76 3 ## 1 1 94 ## ## Accuracy : 0.9770115 ## 95% CI : (0.9421888, 0.9937017) ## No Information Rate : 0.5574713 ## P-Value [Acc > NIR] : < 0.00000000000000022 ## ## Kappa : 0.9535318 ## Mcnemar's Test P-Value : 0.6170751 ## ## Sensitivity : 0.9870130 ## Specificity : 0.9690722 ## Pos Pred Value : 0.9620253 ## Neg Pred Value : 0.9894737 ## Prevalence : 0.4425287 ## Detection Rate : 0.4367816 ## Detection Prevalence : 0.4540230 ## Balanced Accuracy : 0.9780426 ## ## 'Positive' Class : 0 ##
Beh, immagino che ora abbiamo risultati migliori. Esaminiamolo attentamente.
La matrice di confusione mostra risultati veramente buoni questa volta, la rete neurale sta commettendo meno errori di classificazione in entrambe le classi, si può vedere se i valori della diagonale principale e anche il valore di precisione è di circa il 95%. Significa che il classificatore ha il 95% di probabilità di classificare correttamente un nuovo esempio invisibile. Per i problemi di classificazione, non è affatto un cattivo risultato.