Articolo in lingua originale di Benedict Neo
State scrivendo lo stesso codice per creare plot per dataset diversi? Con FastEDA potete fare analisi dati esplorativa (EDA) con una sola linea di codice 🚀.
Questo articolo esplorerà cosa FastEDA può fare andando nel dettaglio del codice e analizzando gli output su un dataset reale.
Immergiamoci!
Codice → Deepnote
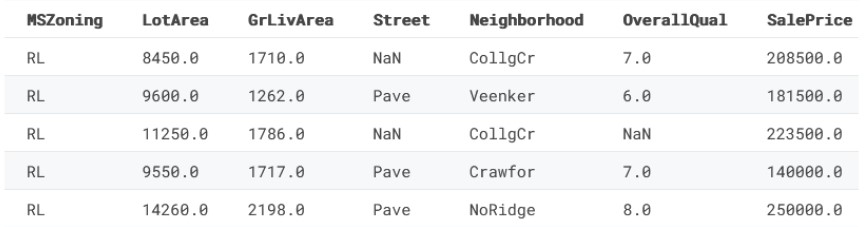
Ecco come sono i nostri dati:
df.head()
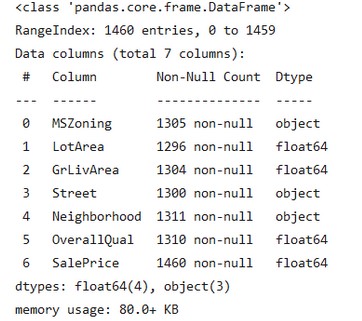
df.info()
Dati mancanti
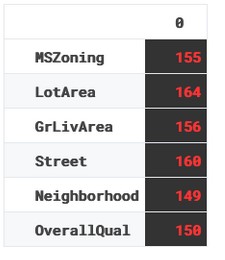
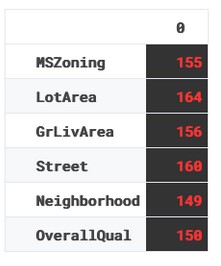
Il codice qua sotto filtra le colonne con dati mancanti. Siccome li abbiamo imputati, tutte le colonne saranno in null_cols
null_cols = [i for i in df.columns if df[i].isna().sum() > 0] df0 = df[null_cols] null_cols output: ['MSZoning', 'LotArea', 'GrLivArea', 'Street', 'Neighborhood', 'OverallQual']
Qui calcoliamo il totale dei valori mancati per ogni colonna, lo trasformiamo in dataframe e applichiamo gli stili.
display(
df0.isna()
.sum()
.to_frame()
.style.set_properties(
**{
"background-color": "#000000",
"color": "#ff0000",
"font-weight": "bold",
}
)
)
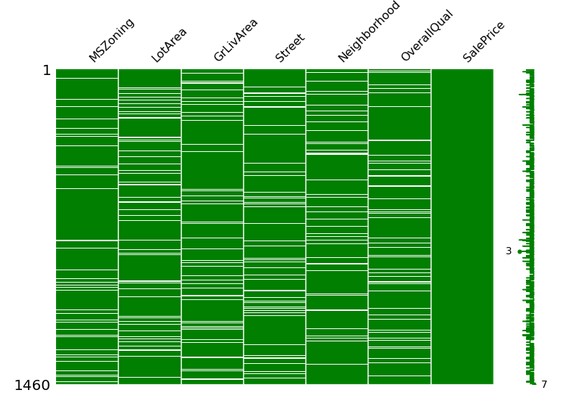
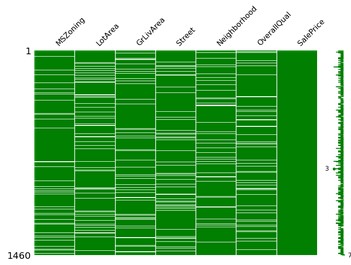
Qui vediamo missingno in azione, le parti bianche della matrice rappresentano i valori mancanti
import missingno as msno
msno.matrix(df, color=(0, 0.5, 0), figsize=(12, 8))
plt.show()
print("-" * 100)
Statistiche
Qui calcoliamo skew e curtosi. Se non sapete di cosa si tratta, ecco una breve lezione:
Skew e curtosi sono misure della forma di una distribuzione.
Lo skew misura l’asimmetria. Una distribuzione è asimmetrica a destra se presenta una coda più lunga a destra, viceversa se presenta una coda più lunga a sinistra. Una distribuzione simmetrica ha skew pari a zero.
La curtosi misura la pesantezza delle code di una distribuzione. Una distribuzione con curtosi elevata presenta probabilità maggiori sulle code più che al centro, rispetto ad una distribuzione normale. Una distribuzione con curtosi bassa avrà meno probabilità sulle code piuttosto che al centro. La curtosi di una distribuzione normale è 3.
Queste misure ci danno quindi un’idea di come una distribuzione differisca da una distribuzione normale – se ha code più pesanti, più lunghe, ecc. Possono essere utili per verificare l’adattamento del modello o per rilevare anomalie nei dati.
from scipy.stats import skew, kurtosis skew_ = ( df._get_numeric_data().dropna().apply(lambda x: skew(x)).to_frame(name="skewness") ) kurt_ = ( df._get_numeric_data() .dropna() .apply(lambda x: kurtosis(x)) .to_frame(name="kurtosis") ) skew_kurt = pd.concat([skew_, kurt_], axis=1) skew_kurt
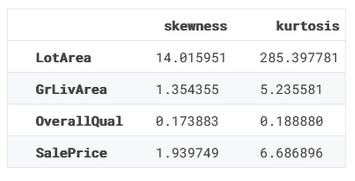
Basandoci sulle statistiche di LotArea possiamo già dire che la distribuzione di LotArea è asimmetrica (skew diverso da zero)
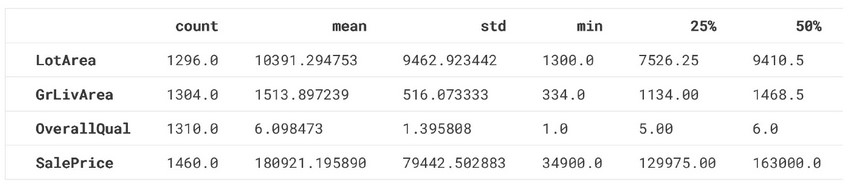
Qui è mostrato l’output del metodo standard describe()
desc_df = df.describe().T desc_df
Ora raggruppiamo tutto in un unico dataframe, includendo le informazioni su skew, kurtosis e mediana.
full_info = pd.concat([desc_df, skew_kurt], ignore_index=True, axis=1)
full_info.columns = list(desc_df.columns) + list(skew_kurt.columns)
full_info.insert( loc=2, column="median", value=df.median(skipna=True, numeric_only=True) )
full_info.iloc[:, :-2] = full_info.iloc[:, :-2].applymap(
lambda x: format(x, ".3f").rstrip("0").rstrip(".")
if isinstance(x, (int, float))
else x )
full_info

E ora aggiungiamo del colore:
def color_negative_red(value):
if value < 0:
color = "#ff0000"
elif value > 0:
color = "#00ff00"
else:
color = "#FFFFFF"
return "color: %s" % color
info_cols = ["skewness", "kurtosis"]
display(
full_info.style.background_gradient(cmap="Spectral", subset=full_info.columns[:-2]) .applymap(color_negative_red, subset=info_cols)
.set_properties( **{"background-color": "#000000", "font-weight": "bold"}, subset=info_cols, ) .set_properties(**{"font-weight": "bold"}, subset=full_info.columns[:-2]) )

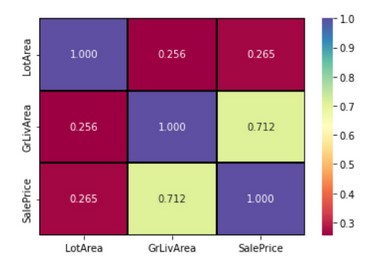
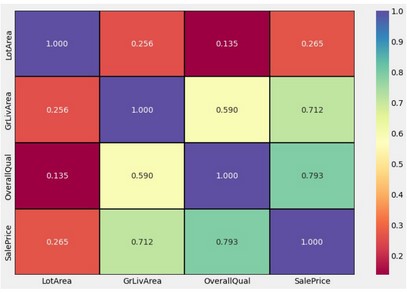
Ora prendiamo le colonne numeriche e calcoliamo la correlazione tra loro
import seaborn as sns sns.heatmap( df[num_cols].corr(), annot=True, cmap="Spectral", linewidths=2, linecolor="#000000", fmt=".3f", );
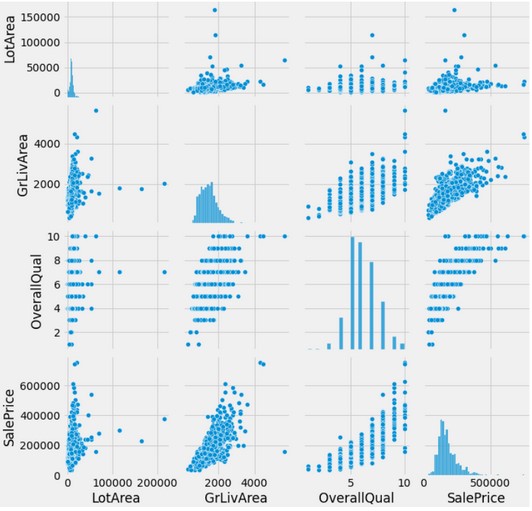
Il resto del codice ritorna un pairplot e, per ogni variable, istogramma, boxplot e countplot.
Lo vediamo nell’esecuzione di una riga sola.
from fasteda import fast_eda fast_eda(df)
DataFrame Head:

DataFrame Tail:

Missing values:
MSNO Matrix
Shape of DataFrame:
(1460, 7)
DataFrame Info:

Describe DataFrame:

DataFrame Correlation:
DataFrame pairplot:
Histogram(s) & Boxplot(s):
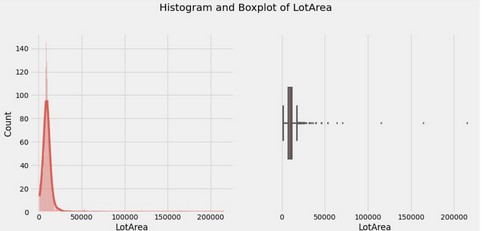
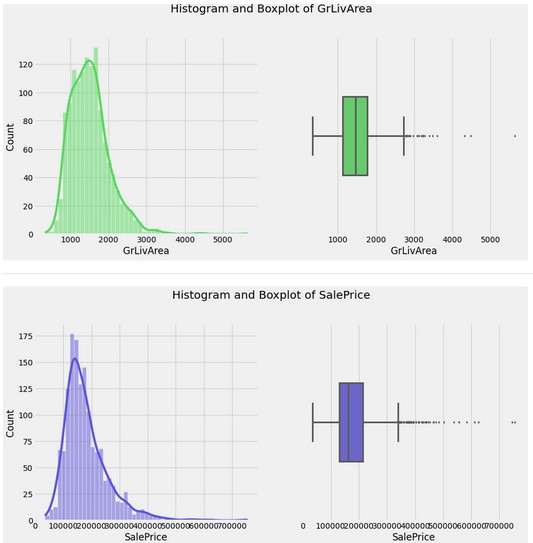
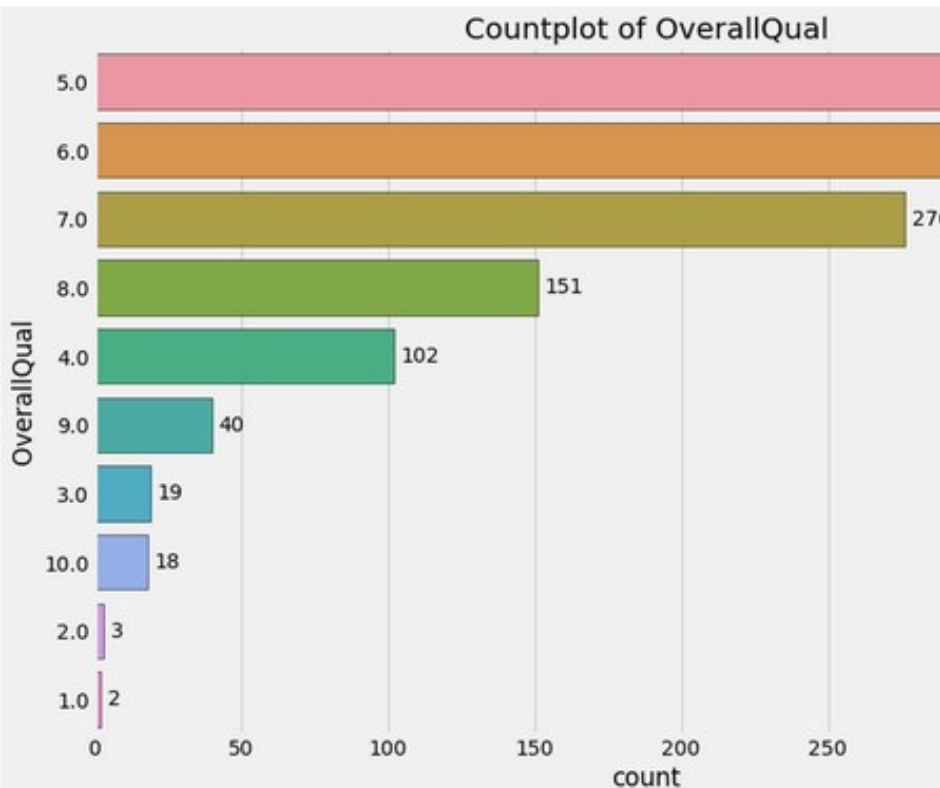
Countplot(s)
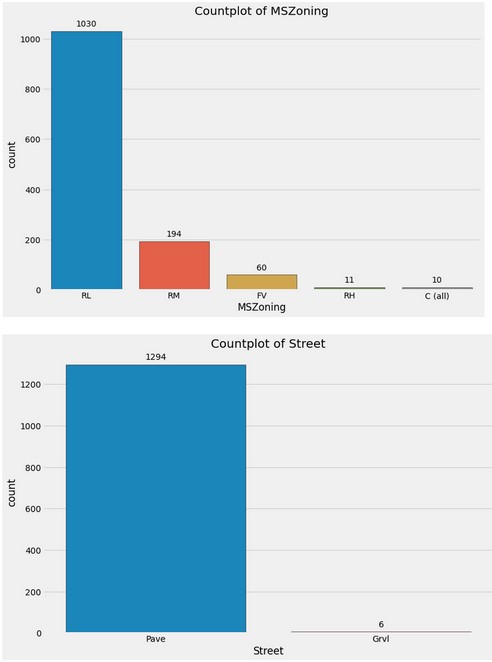
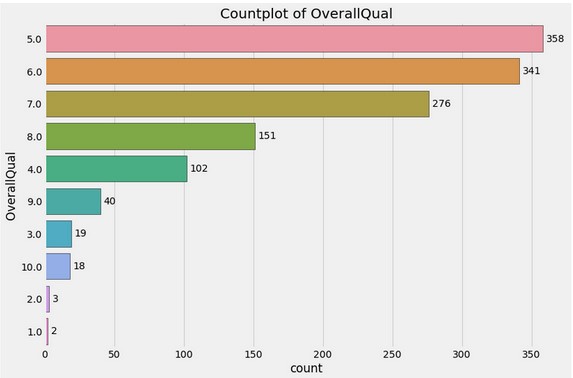
Questo conclude la presentazione di FastEDA! Se siete ancora curiosi, ecco un altro esempio sul dataset Titanic.