
Se avete mai sentito parlare o studiato il deep learning, probabilmente avrete sentito parlare di MNIST, SVHN, ImageNet, PascalVoc e altri. Ognuno di questi set di dati ha una cosa in comune. Sono costituiti da centinaia e migliaia di dati etichettati. In altre parole, queste raccolte sono composte da coppie (x,y) in cui (x) è il dato grezzo, ad esempio una matrice di immagine, e (y) è una descrizione di ciò che quel punto di dati (x) rappresenta.
Prendiamo come esempio il set di dati MNIST. Ciascuno dei 60.000 punti dati è una coppia (input, label). input è un’immagine in scala di grigi 28×28 e label è un segno che rappresenta l’input. Per il dataset MNIST, un’immagine di input può essere uno zero, uno, due, tre e così via fino a 10 possibili categorie.

L’uso più comune di dataset come questi è quello di sviluppare modelli supervisionati. Per addestrare questi algoritmi, di solito forniamo un’enorme quantità di campioni di dati.
L’apprendimento supervisionato è stato al centro della maggior parte delle ricerche nel deep learning. Tuttavia, la necessità di creare modelli in grado di apprendere da un numero inferiore di dati sta aumentando rapidamente.
In quest’ottica, l’apprendimento semi-supervisionato è una tecnica che prevede l’utilizzo di dati etichettati e non etichettati per addestrare un classificatore.
Questo tipo di classificatore prende una piccola porzione di dati etichettati e una quantità molto maggiore di dati non etichettati (provenienti dallo stesso dominio). L’obiettivo è quello di combinare queste fonti di dati per addestrare una rete neurale a convoluzione profonda (Deep Convolution Neural Networks, DCNN) per apprendere una funzione dedotta in grado di mappare un nuovo punto di dati al risultato desiderato.
In questa frontiera, presentiamo un modello GAN per classificare i numeri civici di street view utilizzando un set di addestramento etichettato molto piccolo. Infatti, il modello utilizza circa l’1,3% delle etichette di addestramento originali di SVHN, cioè 1000 (mille) esempi etichettati. Utilizziamo alcune delle tecniche descritte nel documento Improved Techniques for Training GANs di OpenAI.
Se non avete familiarità con le GAN per la generazione di immagini, consultate A Short Introduction to Generative Adversarial Networks. Questo articolo fa riferimento ad alcuni dei contenuti descritti in quell’opera. Il codice completo è disponibile qui. Altrimenti, iscrivetevi al nostro corso ad hoc interamente dedicato ai modelli generativi!
Quando abbiamo costruito una GAN per la generazione di immagini, abbiamo addestrato contemporaneamente il generatore e il discriminatore. Dopo l’addestramento, abbiamo potuto scartare il discriminatore perché lo abbiamo usato solo per addestrare il generatore.
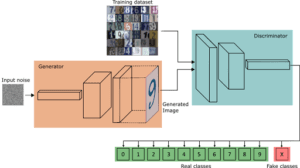
Per l’apprendimento semi-supervisionato, dobbiamo trasformare il discriminatore in un classificatore multiclasse. Questo nuovo modello deve essere in grado di generalizzare bene sul set di test, anche se non abbiamo molti esempi etichettati per l’addestramento.
Inoltre, questa volta, al termine dell’addestramento, possiamo effettivamente buttare via il generatore. Si noti che i ruoli sono cambiati. Ora il generatore viene utilizzato solo per aiutare il discriminatore durante l’addestramento.
In altre parole, il generatore agisce come un’altra fonte di informazioni da cui il discriminatore ottiene dati di addestramento non etichettati. Come vedremo, questi dati non etichettati sono fondamentali per migliorare le prestazioni del discriminatore.
Inoltre, per una normale GAN a generazione di immagini, il discriminatore ha un solo ruolo. Calcolare la probabilità che i suoi input siano reali o meno – chiamiamolo il problema del GAN.
Tuttavia, per trasformare il discriminatore in un classificatore semi-supervisionato, oltre al problema GAN, il discriminatore deve anche apprendere le probabilità di ciascuna delle classi del dataset originale.
In altre parole, per ogni immagine in ingresso, il discriminatore deve apprendere le probabilità che sia una, due, tre e così via.
Ricordiamo che per un discriminatore GAN di generazione di immagini, abbiamo una singola unità sigmoide in uscita. Questo valore rappresenta la probabilità che un’immagine in ingresso sia reale (valore vicino a 1) o falsa (valore vicino a 0).
In altre parole, dal punto di vista del discriminatore, valori prossimi a 1 significano che i campioni provengono probabilmente dall’insieme di allenamento. Allo stesso modo, un valore vicino a 0 indica una maggiore probabilità che i campioni provengano dalla rete del generatore.
Utilizzando questa probabilità, il discriminatore è in grado di inviare un segnale al generatore. Questo segnale permette al generatore di adattare i suoi parametri durante l’addestramento, migliorando le sue capacità di creare immagini realistiche.
Dobbiamo convertire il discriminatore (del GAN precedente) in un classificatore a 11 classi. Per farlo, possiamo trasformare la sua uscita sigmoide in una softmax con 11 uscite di classe. Le prime 10 per le probabilità delle singole classi del set di dati SVHN (da zero a nove) e l’undicesima classe per tutte le immagini false provenienti dal generatore.
Si noti che se si imposta la probabilità dell’undicesima classe a 0, la somma delle prime 10 probabilità rappresenta la stessa probabilità calcolata con la funzione sigmoide.
Infine, dobbiamo impostare le perdite in modo tale che il discriminatore possa fare entrambe le cose:
– (i) aiutare il generatore di apprendimento a produrre immagini realistiche. A tal fine, dobbiamo istruire il discriminatore a distinguere tra campioni reali e falsi.
– (ii) utilizzare le immagini del generatore, insieme ai dati di addestramento etichettati e non etichettati, per aiutare a classificare il set di dati.
In sintesi, il discriminatore dispone di tre diverse fonti di dati di addestramento.
– Immagini reali con etichette. Si tratta di coppie di immagini etichettate come in un normale problema di classificazione supervisionata.
– Immagini reali senza etichette. Per queste, il classificatore impara solo che le immagini sono reali.
– Immagini dal generatore. Per queste, il discriminatore impara a classificare come false.
La combinazione di queste diverse fonti di dati renderà il classificatore in grado di apprendere da una prospettiva più ampia. Questo, a sua volta, consente al modello di eseguire inferenze in modo molto più preciso di quanto non farebbe utilizzando solo i 1000 esempi etichettati per l’addestramento.
Come abbiamo detto, possiamo dividere la perdita del discriminatore in due parti. Una che rappresenta il problema GAN, la perdita non supervisionata. E l’altra che calcola le probabilità delle singole classi reali, la perdita supervisionata.
Per quanto riguarda la perdita non supervisionata, il discriminatore deve distinguere tra le immagini di addestramento reali e le immagini false del generatore.
Come per una GAN normale, il discriminatore riceve per metà del tempo immagini non etichettate dall’insieme di addestramento e per l’altra metà immagini immaginarie non etichettate dal generatore.
In entrambi i casi si tratta di un problema di classificazione binaria. Poiché vogliamo un valore di probabilità vicino a 1 per le immagini reali e vicino a 0 per quelle irreali, possiamo utilizzare la funzione di entropia incrociata sigmoidea per calcolare la perdita.
Per le immagini provenienti dal set di addestramento, massimizziamo la loro probabilità di essere reali assegnando etichette di 1. Per le immagini fabbricate, provenienti dal generatore, massimizziamo la loro probabilità di essere reali. Per le immagini fabbricate provenienti dal generatore, massimizziamo la loro probabilità di essere false assegnando loro etichette di 0.
Per la perdita supervisionata, dobbiamo utilizzare i logit del discriminatore. Poiché si tratta di un problema di classificazione multiclasse, possiamo utilizzare la funzione di cross entropy softmax con le etichette reali che abbiamo a disposizione.
Si noti che questa parte è simile a qualsiasi altro modello di classificazione. Alla fine, la perdita del discriminatore è la somma della perdita supervisionata e della perdita non supervisionata. Inoltre, poiché stiamo facendo finta di non avere la maggior parte delle etichette, dobbiamo ignorarle nella perdita supervisionata. Per fare ciò, moltiplichiamo la perdita per la variabile maschere che indica quale insieme di etichette è disponibile per l’uso.
Come descritto nel documento Improved Techniques for Training GANs, utilizziamo la corrispondenza delle caratteristiche per la perdita del generatore.
Come descrivono gli autori:
La corrispondenza delle caratteristiche è il concetto di penalizzazione dell’errore assoluto medio tra il valore medio di un insieme di caratteristiche sui dati di addestramento e i valori medi di quell’insieme di caratteristiche sui campioni generati.
Per fare ciò, prendiamo un insieme di statistiche (i momenti) da due fonti diverse e le forziamo a essere simili.
In primo luogo, prendiamo la media delle caratteristiche estratte dal discriminatore durante l’elaborazione di un minibatch di formazione reale.
In secondo luogo, calcoliamo i momenti nello stesso modo, ma ora per quando un minibatch composto da immagini false provenienti dal generatore viene analizzato dal discriminatore.
Infine, con queste due serie di momenti, la perdita del generatore è la differenza assoluta media tra i due. In altre parole, come sottolinea il documento:
Addestriamo il generatore a far corrispondere i valori attesi delle caratteristiche a uno strato intermedio del discriminatore.
Sebbene la perdita di feature-matching abbia buone prestazioni nel compito di apprendimento semi-supervisionato, le immagini prodotte dal generatore non sono buone come quelle create nell’ultimo post.

Nel documento Improved Techniques for Training GANs, OpenAI riporta risultati all’avanguardia per l’apprendimento di classificazioni semi-supervisionate su MNIST, CIFAR-10 e SVHN.
La nostra implementazione raggiunge precisioni di addestramento e di test rispettivamente del 93% e del 68%. Questi risultati sono migliori di quelli riportati nell’articolo del NIPS 2014, che ha ottenuto circa il 64%.
Questo notebook non è destinato a dimostrare le migliori pratiche come le tecniche di convalida incrociata. Utilizza solo alcune delle tecniche descritte nell’articolo originale di OpenAI.
Il quaderno si basa sul programma di nanodiploma Udacity Deep learning Fundamentals in cui mi sono laureato.
