Articolo originale in lingua inglese di Urwa Muaz
Nei progetti di apprendimento automatico spesso ci imbattiamo in maledizione problema dimensionalità dove il numero di record di dati non sono un fattore sostanziale del numero di caratteristiche. Questo porta spesso ad un problema in quanto significa allenare molti parametri utilizzando un set di dati scarsi, che possono facilmente portare a sovradimensionamento e scarsa generalizzazione. Alta dimensionalità significa anche tempi di allenamento molto grandi. Quindi, le tecniche di riduzione della dimensionalità sono comunemente usate per affrontare questi problemi. E ‘spesso vero che, nonostante risiedono in spazio ad alta dimensionale, lo spazio caratteristica ha una struttura a basso dimensionale.
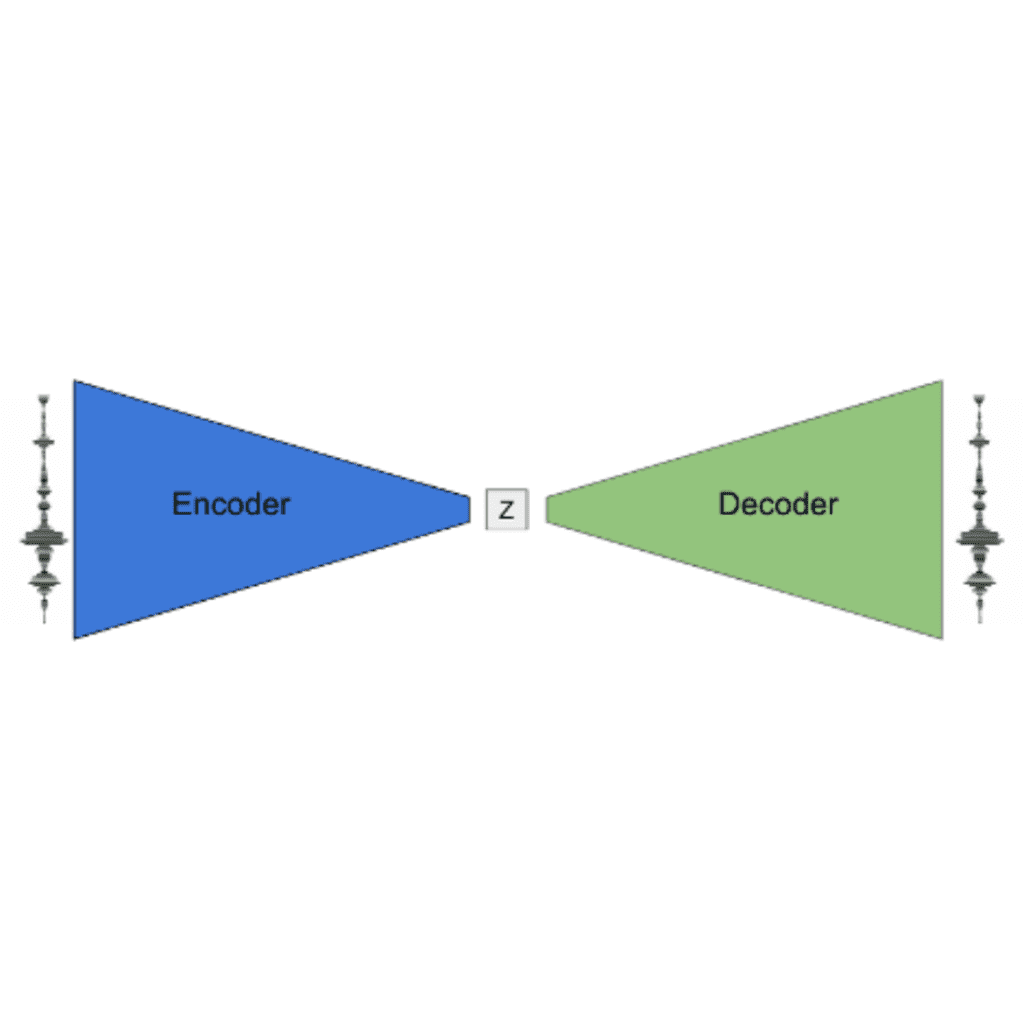
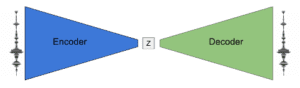
Due modi molto comuni di ridurre la dimensionalità dello spazio caratteristica sono PCA e auto-encoder. Mi limiterò a fornire una breve introduzione a questi, per un confronto più teoricamente orientato leggere questo post.
Qui costruiamo spazi di caratteristiche bidimensionali (x e y sono due caratteristiche) con relazione lineare e non lineare tra di loro (con qualche rumore aggiunto). Confronteremo la capacità di autoenocoder e PCA di ricostruire accuratamente l’input dopo averlo proiettato nello spazio latente. La PCA è una trasformazione lineare con una trasformazione inversa ben definita e l’uscita del decodificatore da Autoencoder ci dà l’input ricostruito. Usiamo uno spazio latente dimensionale per PCA e autoencoder.
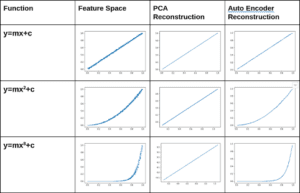
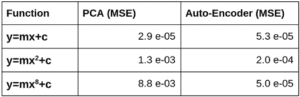
È evidente se c’è una relazione non lineare (o curvatura) nello spazio delle caratteristiche, lo spazio latente autocodificato può essere utilizzato per una ricostruzione più accurata. Mentre PCA mantiene solo la proiezione sul primo componente principale e qualsiasi informazione perpendicolare ad esso viene persa. Vediamo il costo della ricostruzione come misurato dall’errore quadratico medio (MSE) nella tabella seguente.
Condurre esperimenti simili in 3D. Creiamo due spazi di funzionalità tridimensionali. Uno è un piano 2D esistente nello spazio 3D e l’altro è una superficie curva nello spazio 3D.
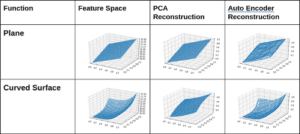
Possiamo vedere che nel caso di un piano c’è una struttura chiaramente bidimensionale ai dati e PCA con due componenti può rappresentare il 100% della varianza dei dati e può quindi ottenere una ricostruzione perfetta. Nel caso di una superficie curva PCA bidimensionale non è in grado di tenere conto di tutta la varianza e quindi perde informazioni. La proiezione verso la pianura che copre la maggior parte della varianza viene mantenuta e altre informazioni vengono perse, quindi la ricostruzione non è così accurata. D’altra parte Autoencoder è in grado di ricostruire sia il piano che la superficie con precisione utilizzando lo spazio latente bidimensionale. Quindi lo spazio latente 2D è in grado di codificare più informazioni in caso di Autoencoder perché è in grado di modellare non lineare. Il costo della ricostruzione è indicato nella tabella seguente.
Qui creiamo un dato casuale senza alcuna collinearità. Tutte le caratteristiche sono campionate indipendentemente da una distribuzione uniforme e non hanno alcuna relazione tra loro. Usiamo lo spazio latente bidimensionale sia da PCA che da Autoencoder.
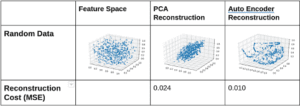
Vediamo che PCA è in grado di mantenere la proiezione sul piano con varianza massima, e perde un sacco di informazioni perché i dati casuali non hanno una struttura dimensionale 2 sottostante. Autoencoder fa anche male poiché non c’era alcuna relazione sottostante tra le caratteristiche.