
Questo articolo descrive un nuovo approccio alla classificazione dei documenti multi-pagina, che sfrutta l’apprendimento automatico avanzato e l’analisi testuale per risolvere una delle principali sfide del settore ipotecario.
Astratto
Anche nell’odierna era tecnologica, la maggior parte delle attività commerciali viene svolta utilizzando documenti e la quantità di documenti cartacei coinvolti varia da settore a settore. Molti di questi settori hanno bisogno di scansionare le immagini dei documenti digitalizzati (che di solito contengono testo non selezionabile) per ottenere le informazioni per i campi indice chiave per svolgere le loro attività quotidiane.
A tal fine, il primo compito importante è l’indicizzazione di diversi tipi di documenti, che in seguito aiuta a estrarre informazioni e metadati da una varietà di documenti complessi. Questo blog post illustra come le tecniche avanzate di apprendimento automatico e di NLP possano essere sfruttate per risolvere questa parte importante del puzzle, formalmente chiamata classificazione dei documenti.
Nel settore dei mutui ipotecari, diverse società eseguono revisioni dei prestiti ipotecari di migliaia di persone.
Ogni singola verifica viene eseguita su un assortimento di documenti, presentati in un pacchetto chiamato Loan Package. Un pacchetto è una combinazione di pagine scansionate, che può variare da (100-400~) pagine. All’interno del pacchetto sono presenti più sottocomponenti che possono consistere in (1-30~) pagine. Tali sottocomponenti sono chiamati Documenti o classi di documenti. La tabella seguente rappresenta visivamente questo aspetto.
![]()
Tradizionalmente, durante la valutazione delle revisioni dei prestiti, la classificazione dei documenti è una delle parti principali dello sforzo manuale. Le società di mutui ipotecari esternalizzano per lo più questo lavoro a società di BPO di terze parti, che eseguono questo compito utilizzando tecniche di classificazione manuali o parzialmente automatizzate, come motori di regole e template matching. Il problema di fondo delle attuali implementazioni è che il personale di Business Process Outsourcing (BPO) deve trovare e ordinare manualmente i documenti presenti nei pacchetti.
Tuttavia, alcune aziende di terze parti hanno raggiunto un certo grado di automazione utilizzando ricerche per parole chiave, espressioni regolari, ecc. L’accuratezza e la solidità di queste soluzioni sono discutibili e la riduzione del carico di lavoro manuale non è ancora soddisfacente. Le ricerche per parole chiave e le espressioni regolari implicano che queste soluzioni devono tenere conto di ogni nuovo documento o di ogni variazione di documento che viene presentata e devono anche aggiungere regole per questo. Questo diventa di per sé uno sforzo manuale e si ottiene solo un’automazione parziale. Rimane la possibilità che il sistema identifichi una classe di documenti come “Doc A”, ma in realtà si tratta di “Doc B”, a causa di regole comuni presenti in entrambi. Inoltre, non esiste un grado di certezza nell’identificazione. Il più delle volte è necessaria una verifica manuale.
Esistono diverse centinaia di tipi di documenti, e il personale del BPO deve avere una base di conoscenze su “come appare un certo documento e quali sono le diverse varianti dello stesso documento?”, al fine di classificare i documenti. Inoltre, se il lavoro manuale è eccessivo, l’errore umano tende ad aumentare.
Obiettivo
La soluzione di classificazione dei documenti deve ridurre in modo significativo lo sforzo umano manuale. Dovrebbe raggiungere un livello superiore di accuratezza e automazione con un intervento umano minimo.
L’approccio alla soluzione che tratteremo in questa serie di blog non è limitato al settore ipotecario, ma può essere applicato ovunque vi siano immagini di documenti scansionati e sia richiesto l’ordinamento di tali documenti. Alcuni dei settori possibili sono le organizzazioni finanziarie, le università, gli istituti di ricerca e i negozi al dettaglio.
Caratteristiche dei documenti
Per creare una pipeline di soluzioni, il primo passo è conoscere i dati e le loro caratteristiche. Poiché abbiamo lavorato nel settore dei mutui, definiremo le caratteristiche dei dati che trattiamo nel settore dei mutui.
All’interno di un pacchetto, esistono molti tipi di pagine, ma in generale si possono classificare in tre tipi:
Moduli e modelli strutturati e coerenti

Non strutturato | Testuale, senza formattazione e tabelle

Semi-strutturato | ibrido dei due precedenti, può avere una struttura parziale

In termini di documenti, le caratteristiche osservate nei dati sono le seguenti.
– I documenti presenti nei pacchetti non sono in un ordine coerente. Ad esempio, in un pacchetto il documento “A” può venire dopo il documento “B” e nell’altro è il contrario.
– Esistono molte varianti di una stessa classe di documenti. Una stessa classe di documenti può avere variazioni di aspetto diverso, ad esempio il modello/formato della pagina di una classe di documenti “A” può cambiare per i diversi Stati degli USA. All’interno del dominio ipotecario, queste rappresentano le stesse informazioni, ma presentano differenze nella formattazione e nei contenuti. In altre parole, se “gatto” è un documento, le diverse razze di gatti sono le “varianti”.
– I tipi di documenti presentano diversi tipi di deformazioni scansionate, come rumore, rotazioni 2D e 3D, cattiva qualità della scansione, orientamento della pagina, che compromettono l’OCR per questi documenti.
In questa sezione spiegheremo astrattamente come funziona la nostra pipeline di soluzioni e come ogni componente o modulo si unisca per produrre una pipeline end-to-end. Segue il diagramma di flusso della soluzione.
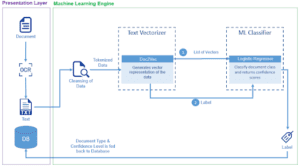
Poiché l’obiettivo è identificare i documenti all’interno del pacchetto, abbiamo dovuto individuare quali caratteristiche all’interno di un documento lo rendono diverso da un altro. Nel nostro caso, abbiamo deciso che il testo presente nel documento è la chiave, perché intuitivamente anche noi umani facciamo così. La sfida successiva è stata quella di capire la posizione del documento all’interno del pacchetto. Nel caso di documenti a più pagine, le pagine di confine (inizio, fine) sono quelle più importanti, perché grazie a queste pagine è possibile identificare una serie di documenti.
Classi di apprendimento automatico
In termini di Machine Learning, abbiamo trattato questo problema come un problema di classificazione. Abbiamo deciso di identificare la prima e l’ultima pagina di ogni documento e abbiamo classificato le nostre classi di apprendimento automatico (classi ML) in tre tipi:
– Classi di prima pagina: Queste classi sono le prime pagine di ogni classe di documento, che saranno responsabili di identificare l’inizio del documento.
– Classi di ultima pagina: Queste classi sono le ultime pagine di ogni classe di documenti, che hanno il compito di identificare la fine del documento. Queste classi saranno create solo per le classi di documenti che hanno campioni con più di una pagina.
– Altra classe: Questa classe è un’unica classe che contiene le pagine centrali di tutte le classi di documenti combinate in un’unica classe. La presenza di questa classe aiuta la pipeline nelle fasi successive, in quanto riduce i casi in cui una pagina centrale di un documento viene classificata come prima o ultima pagina dello stesso documento, cosa che intuitivamente è possibile perché possono esserci delle somiglianze tra tutte le pagine, come intestazioni, piè di pagina e modelli. Ciò consente al modello di apprendere caratteristiche più robuste.
Il diagramma seguente rappresenta l’aspetto di questi diversi tipi di classi ML in termini di pacchetti e documenti
![]()
Una volta definite le classi ML, il passo successivo è la preparazione del set di dati per l’addestramento del Machine Learning Engine (la parte di preparazione dei dati sarà discussa in dettaglio nelle prossime sezioni). Il diagramma seguente spiega il funzionamento interno del Machine Learning Engine e rappresenta una visione più tecnica della pipeline della soluzione.

Descriviamo passo dopo passo le diverse fasi della soluzione.
Fase 1
– Il pacchetto (in formato pdf) viene suddiviso in singole pagine (immagini).
Fase 2
– Le singole pagine vengono elaborate attraverso un OCR (Optical Character Recognition), che estrae il testo dall’immagine e genera i file di testo. Nel nostro caso abbiamo utilizzato un motore OCR all’avanguardia per produrre il testo. Esistono molte offerte online gratuite di OCR che possono essere utilizzate in questa fase.
Fase 3
– Il testo corrispondente a ciascuna pagina viene passato al motore di apprendimento automatico, dove il Text Vectorizer (Doc2Vec) genera la rappresentazione del vettore di caratteristiche, che è essenzialmente un elenco di float.
Fase 4
– I vettori di caratteristiche vengono quindi passati al classificatore (Regressione logistica). Il classificatore predice la classe per ogni vettore di caratteristiche. Che è essenzialmente una delle classi ML di cui abbiamo parlato in precedenza (prima, ultima o altra).
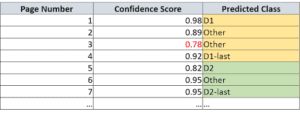
Inoltre, il classificatore restituisce i punteggi di confidenza per tutte le classi ML (la sezione più a destra del diagramma). Ad esempio, se (D1,D2 …) sono le classi ML, per una singola pagina i risultati possono essere i seguenti.

Una volta elaborato l’intero pacchetto, utilizziamo i risultati e le previsioni per identificare i confini dei documenti. I risultati contengono la classe prevista e i punteggi di confidenza delle previsioni per tutte le pagine del pacchetto. Si veda la seguente tabella
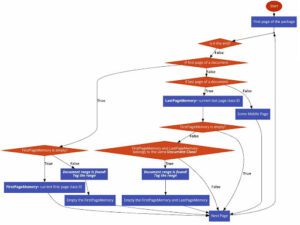
Di seguito sono illustrati il semplice algoritmo e i passaggi utilizzati per identificare i confini del documento utilizzando i risultati del motore di apprendimento automatico.
Dettagli delle soluzioni (approfondimento TL;DR)
Preparazione dei dati
Nel tentativo di sviluppare una pipeline di classificazione dei documenti end-to-end, il primo passo, e probabilmente il più importante, è la preparazione dei dati, perché la soluzione è buona quanto i dati che utilizza. I dati che abbiamo utilizzato per i nostri esperimenti sono documenti provenienti dal settore dei mutui. Le strategie adottate possono essere applicate in modo analogo a qualsiasi tipo di dataset di documenti. Di seguito sono riportati i passaggi che sono stati eseguiti.
Definizione : Il campione di documento è un’istanza di un particolare documento. Di solito si tratta di un file (pdf) contenente solo le pagine di quel documento.
Fase 1
– Il primo passo consiste nel decidere quali documenti all’interno di un pacchetto devono essere riconosciuti e classificati. Idealmente, dovrebbero essere selezionati tutti i documenti presenti nei pacchetti. Una volta decise le classi di documenti, si passa alla parte di estrazione. Nel nostro caso, abbiamo deciso di classificare (44) classi di documenti.
Fase 2
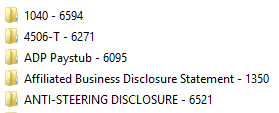
– Per ottenere il set di dati, abbiamo raccolto i pdf di diverse centinaia di pacchetti e abbiamo estratto manualmente i documenti selezionati da tali pacchetti. Una volta individuato il documento all’interno del pacchetto, le sue pagine sono state separate e concatenate insieme sotto forma di file pdf. Ad esempio, se in un pacchetto abbiamo trovato il “Doc A” dalla pagina 4 alla 10, estraiamo le 6 pagine (4-10) e le uniamo in un pdf di 6 pagine. Questo pdf di 6 pagine costituisce un campione di documento. Tutti i campioni estratti per una particolare classe di documenti sono stati inseriti in una cartella separata. Di seguito viene mostrata la struttura della cartella. Abbiamo raccolto oltre 300 campioni di documenti per ogni classe di documenti. A ogni classe di documenti è stato assegnato un identificatore unico che abbiamo chiamato “DocumentIdentifierID”.
Fase 3
– Il passo successivo consiste nell’applicare l’OCR ed estrarre il testo da tutte le pagine presenti nei campioni di documenti. L’OCR ha iterato su tutte le cartelle e ha generato file excel contenenti il testo estratto e alcuni meta-dati. Di seguito viene mostrato il formato dei file excel, Ogni riga rappresenta una pagina.
![]()
Numero di prestito, nome del file: si tratta di identificatori univoci del campione (pdf). Nella tabella sono presenti due campioni (verde e giallo).
ID identificatore documento, nome documento: rappresentano la classe di documenti a cui appartengono i campioni.
Conteggio pagine : Numero totale di pagine presenti in un particolare campione. (entrambi i campioni hanno 2 pagine)
Page Number : è il numero di pagina ordinato di ogni pagina all’interno di un campione.
IsLastPage : Se 1, significa che la pagina è l’ultima di quel particolare campione.
Testo della pagina : è il testo restituito dall’OCR per quella particolare pagina.
![]()
Tabella del set di dati con righe di esempio.
Numero di prestito, nome del file: si tratta di identificatori univoci del campione (pdf). Nella tabella sono presenti due campioni (verde e giallo).
ID identificatore documento, nome documento: rappresentano la classe di documenti a cui appartengono i campioni.
Conteggio pagine : Numero totale di pagine presenti in un particolare campione. (entrambi i campioni hanno 2 pagine)
Page Number : è il numero di pagina ordinato di ogni pagina all’interno di un campione.
IsLastPage : Se 1, significa che la pagina è l’ultima di quel particolare campione.
Testo della pagina : è il testo restituito dall’OCR per quella particolare pagina.
Una volta generati i dati nel formato sopra descritto, il passo successivo è la loro trasformazione. Nella fase di trasformazione, i dati vengono convertiti/manipolati nel formato essenziale per l’addestramento di un modello di apprendimento automatico. Di seguito sono riportate le trasformazioni applicate al set di dati.
Fase 1 – Generazione delle classi ML
– Il primo passo della trasformazione consiste nel generare le classi prima pagina, ultima pagina e altre pagine. A tal fine, vengono utilizzati i valori delle colonne Page Number e IsLastPage. Di seguito è riportata una rappresentazione condizionale della logica utilizzata.

– Inoltre, la tabella sottostante rappresenta le colonne. Si noti la colonna gialla in cui 6853 rappresenta la classe della prima pagina, 6853-ultima rappresenta la classe dell’ultima pagina, mentre le pagine intermedie sono considerate come classe Altro.
![]()
Fase 2 – Suddivisione dei dati per l’addestramento e il test della pipeline
– Una volta completata la fase 1, da quel momento in poi abbiamo bisogno solo di due colonne “Page Text” e “ML Class” per creare la pipeline di addestramento. Le altre colonne sono utilizzate per le valutazioni di test.
– Il passo successivo consiste nel suddividere i dati per l’addestramento e il test della pipeline. I dati vengono suddivisi in modo che l’80% venga utilizzato per l’addestramento e il 20% per il test. I dati vengono anche mescolati in modo casuale, ma in modo stratificato per ogni classe. Per ulteriori informazioni, fare clic sul link.
Fase 3 – Pulizia e trasformazione dei dati
– La colonna “Page Text”, che contiene il testo OCR di ogni pagina, viene ripulita; questo processo viene applicato sia al training che al test. I processi eseguiti sono i seguenti.
- Correzione dei casi: Tutto il testo viene convertito in maiuscolo o minuscolo.
- Regex per i caratteri non alfanumerici: Tutti i caratteri non alfanumerici vengono eliminati.
- Tokenizzazione delle parole: Tutte le parole vengono tokenizzate, il che significa che la stringa di testo di una pagina diventa un elenco di parole.
- Rimozione delle stopwords: Le stopword sono parole troppo comuni nella lingua inglese e potrebbero non essere utili per classificare i singoli documenti. Ad esempio, parole come “the”, “is”, “a”. Queste parole possono anche essere specifiche per il dominio.
Le tabelle seguenti mostrano le trasformazioni prima e dopo

Pipeline di addestramento
Nella precedente sezione sul motore di apprendimento automatico, abbiamo discusso astrattamente il funzionamento interno del motore di apprendimento automatico. I due componenti principali sono.
- Vettorizzatore di testo: Nel nostro caso, abbiamo utilizzato Doc2Vec.
- Modello di classificazione: Per la classificazione viene utilizzato il Regressore logistico.
Vettorizzatore di testo (Doc2Vec)
Fin dall’inizio dell’elaborazione del linguaggio naturale (NLP), è nata l’esigenza di trasformare il testo in qualcosa di comprensibile per le macchine. Ciò significa trasformare le informazioni testuali in una rappresentazione significativa, solitamente nota come vettori (o array) di numeri. La comunità dei ricercatori ha sviluppato diversi metodi per svolgere questo compito. Nella nostra ricerca e sviluppo abbiamo provato diverse tecniche e abbiamo scoperto che Doc2Vec è la migliore tra tutte.
Doc2Vec si basa sul modello Word2Vec. Il modello Word2Vec è un modello di spazio vettoriale predittivo. Per capire Word2Vec, iniziamo con i modelli spaziali vettoriali.
Modelli spaziali vettoriali (VSM): Inseriscono le parole in uno spazio vettoriale continuo in cui le parole semanticamente simili sono mappate in punti vicini.
Due approcci per i VSM:
- Metodi basati sul conteggio: Calcolano le statistiche sulla frequenza di co-occorrenza di una parola con le parole vicine in un corpus di testi di grandi dimensioni, quindi mappano queste statistiche di conteggio in un vettore piccolo e denso per ogni parola (ad esempio, TFIDF).
- Metodi predittivi: Prevedono una parola dai suoi vicini in termini di vettori di incorporamento piccoli e densi appresi (ad esempio, Skip-Gram, CBOW). Word2Vec e Doc2Vec appartengono a questa categoria di modelli.
Modello Word2Vec
È un modello predittivo efficiente dal punto di vista computazionale per l’apprendimento dell’incorporazione delle parole dal testo grezzo. Word2Vec può essere creato utilizzando i due modelli seguenti:
- Skip-Gram: Crea una finestra scorrevole intorno alla parola corrente (parola target). Quindi utilizza la parola corrente per predire tutte le parole circostanti (le parole di contesto). (ad esempio, predice “il gatto si siede sul” da “tappetino”).
- Borsa di parole continua (CBOW): Crea una finestra scorrevole intorno alla parola corrente (parola target). Quindi predice la parola corrente dalle parole circostanti (le parole di contesto). (ad esempio, predice “tappetino” da “il gatto si siede sul”).
Per maggiori dettagli, leggete questo articolo che ne spiega in dettaglio diversi aspetti.
Inoltre, se volete saperne di più sul Natural Language Processing potete iscrivervi ad uno o più dei nostri corsi dedicati che trovate sul sito. Vi lasciamo il link al pacchetto completo
Modello Doc2Vec
Questa tecnica di vettorizzazione del testo è stata introdotta nell’articolo di ricerca scientifica Distributed Representations of Sentences and Documents. Inoltre, ulteriori dettagli tecnici sono disponibili qui.
Si tratta di un algoritmo non supervisionato che apprende una rappresentazione vettoriale di caratteristiche di lunghezza fissa da parti di testo di lunghezza variabile. Questi vettori possono poi essere utilizzati in qualsiasi classificatore di apprendimento automatico per prevedere l’etichetta delle classi.
È simile al modello Word2Vec, ma utilizza tutte le parole di ogni file di testo per creare una colonna unica in una matrice (chiamata Matrice dei paragrafi). Quindi viene addestrato un NN a singolo strato, come quello visto nel modello Skip-Gram, dove i dati di input sono tutte le parole circostanti la parola corrente insieme alla colonna del paragrafo corrente per prevedere la parola corrente. Il resto è uguale ai modelli Skip-Gram o CBOW.
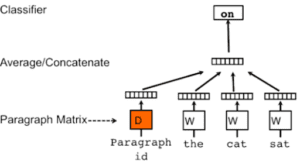
I vantaggi del modello Doc2Vec:
– Per quanto riguarda l’analisi del sentiment, Doc2Vec raggiunge nuovi risultati all’avanguardia, migliori rispetto ai metodi complessi, con un miglioramento relativo di oltre il 16% in termini di tasso di errore.
– Per quanto riguarda la classificazione dei testi, Doc2Vec batte in modo convincente i modelli bag-of-words, con un miglioramento relativo di circa il 30%.
Modello di classificatore (regressore logistico)
Una volta che il testo è stato convertito in un formato vettoriale, è pronto per un classificatore di apprendimento automatico per imparare i modelli presenti nei vettori di diversi tipi di documenti e identificare le distinzioni corrette. Poiché esistono molte tecniche di classificazione che possono essere utilizzate, abbiamo provato le migliori e abbiamo valutato i loro risultati: Random Forest, SVM, Multi-Layer Perceptron e Logistic Regressor. Per ogni classificatore sono stati provati diversi parametri per ottenere i risultati ottimali. Il Logistic Regressor è risultato il migliore tra tutti questi modelli.
Procedura di addestramento
– Una volta trasformati i dati. In primo luogo, si addestra il modello Doc2Vec sullo split di addestramento (come discusso nella sezione sulla trasformazione dei dati). –
– Dopo l’addestramento del modello Doc2Vec, i dati di addestramento vengono passati di nuovo attraverso di esso, ma questa volta il modello non viene addestrato, bensì vengono dedotti i vettori per i campioni di addestramento. L’ultimo passo consiste nel passare questi vettori e l’etichetta di classe ML attuale al modello di classificazione (Regressore logistico).
– Una volta che i modelli sono stati addestrati sui dati di addestramento, entrambi i modelli vengono salvati sul disco, in modo che possano essere caricati in memoria per essere utilizzati nei test e nella distribuzione finale in produzione. Il diagramma seguente mostra il flusso di base di questo schema collaborativo.
Pipeline di test e valutazione
Una volta addestrata la pipeline (che comprende sia il modello Doc2Vec che il classificatore), il seguente diagramma di flusso mostra come viene utilizzata per prevedere le classi di documenti per la suddivisione dei dati di test.
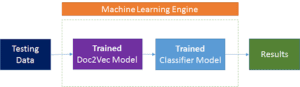
I dati di test trasformati vengono passati attraverso il modello Doc2Vec addestrato, dove vengono estratte e dedotte le rappresentazioni vettoriali di tutte le pagine presenti nei dati di test. Questi vettori vengono poi classificati attraverso il classificatore che restituisce la classe prevista e il punteggio di confidenza per tutte le classi ML.
Per la valutazione dettagliata del Machine Learning Engine, generiamo un file excel dai risultati. La tabella seguente mostra le colonne e le informazioni generate nella fase di test.
![]()
Page Text, File Name, Page Number: sono le stesse colonne che avevamo nella fase di preparazione dei dati, prese così come sono dal dataset di partenza.
ground, pred : ground mostra la classe ML effettiva di quella pagina, mentre pred mostra la classe ML prevista dal motore ML.
Colonne delle classi addestrate: Le colonne di questa sezione rappresentano le classi ML su cui il modello è stato addestrato e i punteggi di confidenza per tali classi.
MaxProb, Range: MaxProb mostra il massimo punteggio di confidenza raggiunto da una qualsiasi delle colonne della sezione Classi addestrate. Il testo colorato in rosso, Range indica l’intervallo in cui rientra MaxProb.
Attualmente esistono tre livelli di valutazione dei risultati.
- Metrica di valutazione dell’errore cumulativo
- Matrice di confusione
- Analisi dei punteggi di confidenza a livello di classe
Metrica di valutazione dell’errore cumulativo
Questa valutazione calcola due metriche, Accuracy e F1-Score. Per maggiori dettagli, consultare questo blog. Queste ci forniscono una visione astratta della bontà della pipeline. I punteggi possono essere compresi tra (1-100), dove un numero più alto rappresenta la bontà della pipeline nel classificare i documenti. Nei nostri esperimenti, abbiamo ottenuto i seguenti punteggi di accuratezza e f1-score.
![]()
Matrice di confusione
La matrice di confusione è una tabella spesso utilizzata per descrivere le prestazioni di un modello di classificazione (o “classificatore”) su un insieme di dati di prova per i quali sono noti i valori veri.
In sostanza, rende più facile la comprensione:
– Quali classi non funzionano bene?
– Qual è il punteggio di accuratezza di una singola classe?
– Quali classi si confondono tra loro?
Il grafico seguente rappresenta la matrice di confusione che abbiamo generato dopo i nostri test. Si tratta di un link incorporato, quindi cliccate per visualizzare la matrice di confusione.
Grafico della matrice di confusione
I valori sull’asse X (etichette vere) e sull’asse Y (etichette previste) rappresentano le classi di documenti su cui ci siamo addestrati. I numeri all’interno delle celle indicano la percentuale del dataset di test appartenente alla classe a sinistra e in basso.
I valori sulla diagonale rappresentano la percentuale di dati in cui le classi previste sono corrette. Una percentuale più alta è migliore, cioè se 0,99 significa che il 99% dei dati di test per quella particolare classe è stato predetto correttamente. Tutte le altre celle mostrano previsioni errate e la percentuale indica quanto una certa classe è stata confusa da un’altra classe.
Come si può notare, il modello è in grado di classificare correttamente la maggior parte delle classi ML con un’accuratezza superiore al 90%.
Analisi dei punteggi di confidenza a livello di classe
Sebbene la matrice di confusione fornisca dettagli sulle confusioni delle classi, non rappresenta i punteggi di confidenza delle previsioni. Che in altre parole significa
– “Quanto è fiducioso il modello quando fa una previsione su una classe di documenti?”.
Qual è l’esigenza?
In una situazione ideale, il modello dovrebbe avere un’alta fiducia quando prevede una classe ML corretta e una bassa fiducia quando prevede una classe ML sbagliata. Ma questo non è un comportamento rigoroso e dipende da molti fattori, come le prestazioni di una particolare classe, le effettive somiglianze di dominio tra le classi di documenti, ecc. Per valutare se questo comportamento esiste e se i punteggi di confidenza possono essere un’indicazione utile di una vera previsione, abbiamo ideato un ulteriore approccio di valutazione.
Approccio
Poiché il compito è quello di ridurre il lavoro manuale, si è deciso di scegliere solo le predizioni con un’alta confidenza, in modo da evitare predizioni errate (perché non hanno un’alta confidenza). Il resto dei documenti e delle pagine sarà verificato manualmente dal BPO.
Soglia
In questa fase vengono calcolati i punteggi di confidenza delle classi e viene definita la soglia. La soglia è una percentuale, ad esempio 80%, 75%, che viene decisa in base alle seguenti condizioni.
– Qual è il valore del punteggio di confidenza in cui le previsioni errate sono in numero irrilevante e quelle vere sono in numero maggiore. In altre parole, si tratta di trovare il punto di equilibrio.
Il grafico seguente mostra i veri positivi (linea blu) e i falsi positivi (linea rossa).
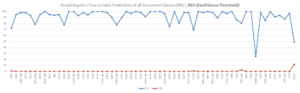
L’asse X mostra le classi ML, mentre l’asse Y mostra la percentuale dei dati di test per una particolare classe, che è coperta da veri positivi o falsi positivi.
Ad esempio: nel caso della classe ML 1330, le predizioni vere coprono quasi il 70% dell’intero set di dati di test per quella classe. Ciò significa che il motore ML è stato in grado di prevedere correttamente il 70% dei dati, con un punteggio di confidenza superiore al 90%. Inoltre, i falsi positivi coprono solo l’1% del set di dati di test, il che significa che solo l’1% dei dati di test è stato previsto in modo errato con un punteggio di confidenza superiore al 90%.
Tuttavia, a causa della soglia, a volte perdiamo dei veri positivi (quando il punteggio di confidenza è inferiore alla soglia). Ma questo non è così grave come i falsi positivi con un’alta confidenza. Tali pagine/documenti saranno verificati manualmente.
Il grafico precedente è stato realizzato con una soglia (90% e oltre). Nel grafico seguente, la soglia è (80% e oltre). Si noti che anche se la soglia viene abbassata all’80% i falsi positivi non aumentano, mentre i veri positivi aumentano in modo significativo. Ciò significa che tra le soglie del 90% e dell’80%, l’80% è ottimale.

Durante l’analisi vengono controllati tutti i livelli: 50%, 60%, 70%. La soglia ottimale viene scelta in base a questa metrica di valutazione.
Caratteristiche della soluzione
– Previsioni veloci | Il tempo di classificazione di una pagina è inferiore a (~300 ms). Se includiamo il tempo di OCR, una pagina può essere classificata ben al di sotto di 1 secondo. Inoltre, se si adotta la multielaborazione,
– L’attuale pipeline di soluzioni è in grado di identificare e classificare i documenti con un’elevata accuratezza e fiducia. Nella maggior parte delle classi otteniamo un’accuratezza superiore al 95%.
– Requisiti dei dati etichettati | Nei nostri esperimenti abbiamo osservato che la pipeline può funzionare bene con un massimo di 300 campioni per classe di documenti. (Come nell’esperimento di cui abbiamo parlato in questo blog). Ma questo dipende dalle variazioni e dal tipo di classe di documenti. Inoltre, vediamo che l’accuratezza e i punteggi di confidenza aumentano con un numero maggiore di campioni.
– Soglia del punteggio di confidenza | La pipeline fornisce punteggi di confidenza della predizione, che consentono un approccio di messa a punto e permettono di regolare tra i veri positivi e i falsi positivi.
– Multiprocessing | L’implementazione di Doc2Vec consente il multiprocessing, inoltre i nostri script di trasformazione dei dati sono altamente parallelizzati.
