L’articolo “Attention Is All You Need” presenta un’architettura innovativa chiamata Transformer. Come indica il titolo, utilizza il meccanismo di attenzione che abbiamo visto in precedenza. Come LSTM, Transformer è un’architettura per trasformare una sequenza in un’altra con l’aiuto di due parti (Encoder e Decoder), ma si differenzia dai modelli sequenza-sequenza precedentemente descritti/esistenti perché non implica alcuna rete ricorrente (GRU, LSTM, ecc.).
Le reti ricorrenti sono state finora uno dei modi migliori per catturare le dipendenze puntuali nelle sequenze. Tuttavia, il team che ha presentato l’articolo ha dimostrato che un’architettura con i soli meccanismi di attenzione senza alcuna RNN (Recurrent Neural Networks) può migliorare i risultati nel compito di traduzione e in altri compiti!
Quindi, cos’è esattamente un Transformer?
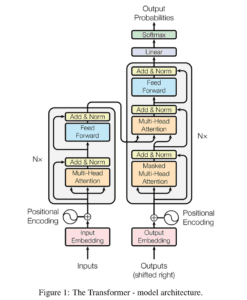
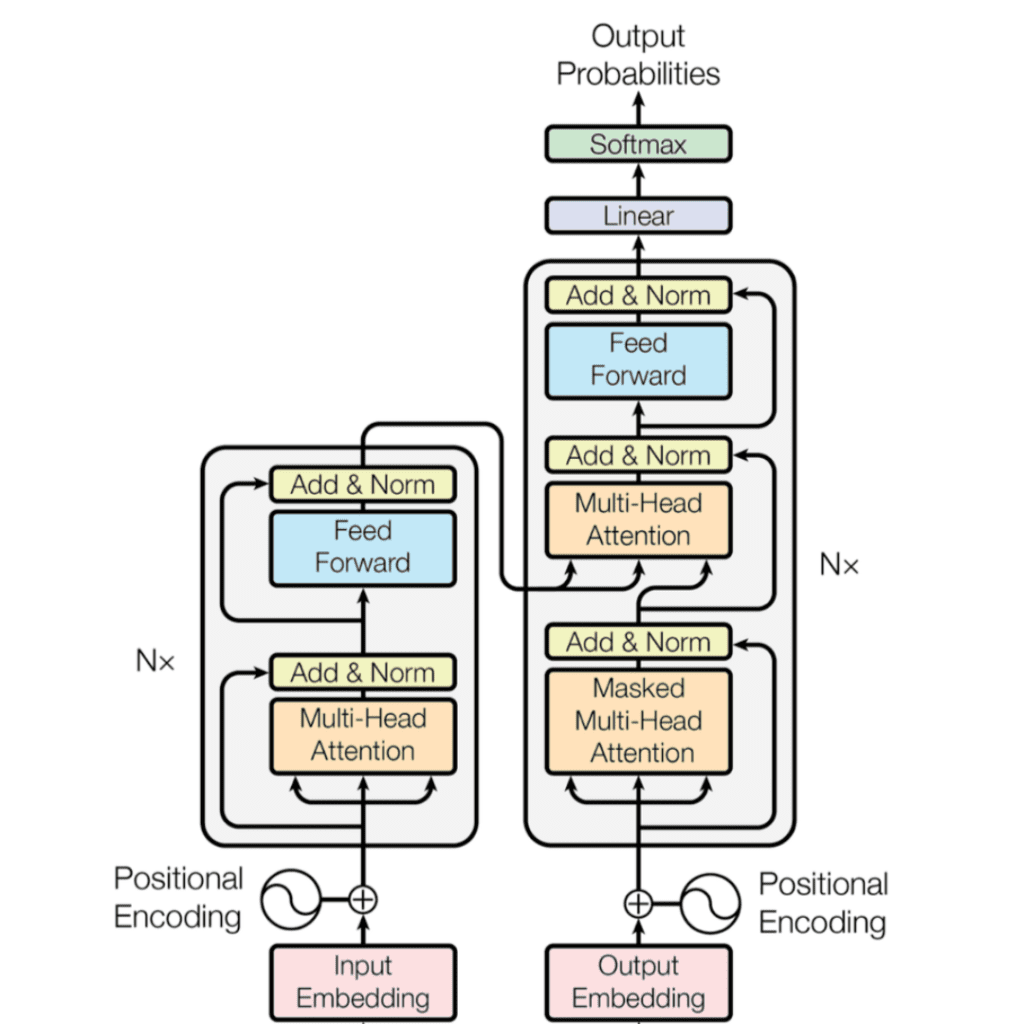
L’Encoder è a sinistra e il Decoder a destra. Sia l’Encoder che il Decoder sono composti da moduli che possono essere impilati l’uno sull’altro più volte, il che è descritto da Nx nella figura. Si nota che i moduli sono costituiti principalmente da livelli di attenzione a più teste e da livelli Feed Forward. Gli input e gli output (frasi target) vengono prima inseriti in uno spazio n-dimensionale, poiché non possiamo usare direttamente le stringhe.
Una piccola ma importante parte del modello è la codifica posizionale delle diverse parole. Poiché non disponiamo di reti ricorrenti in grado di ricordare il modo in cui le sequenze vengono inserite nel modello, dobbiamo in qualche modo assegnare a ogni parola/parte della nostra sequenza una posizione relativa, poiché una sequenza dipende dall’ordine dei suoi elementi. Queste posizioni vengono aggiunte alla rappresentazione incorporata (vettore n-dimensionale) di ogni parola.
Diamo un’occhiata più da vicino a questi mattoncini di attenzione multi-testa nel modello:
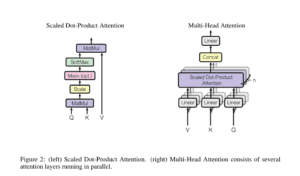
Cominciamo con la descrizione a sinistra del meccanismo di attenzione. Non è molto complicato e può essere descritto dalla seguente equazione:
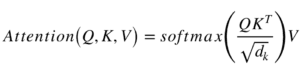
Q è una matrice che contiene la query (rappresentazione vettoriale di una parola della sequenza), K sono tutte le chiavi (rappresentazioni vettoriali di tutte le parole della sequenza) e V sono i valori, che sono di nuovo le rappresentazioni vettoriali di tutte le parole della sequenza. Per i moduli di attenzione multitesta del codificatore e del decodificatore, V è costituito dalla stessa sequenza di parole di Q. Tuttavia, per il modulo di attenzione che tiene conto delle sequenze del codificatore e del decodificatore, V è diverso dalla sequenza rappresentata da Q.
Per semplificare un po’, potremmo dire che i valori in V sono moltiplicati e sommati con alcuni pesi di attenzione a, dove i pesi sono definiti da:
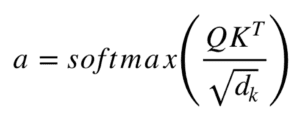
Ciò significa che i pesi a sono definiti da come ogni parola della sequenza (rappresentata da Q) è influenzata da tutte le altre parole della sequenza (rappresentate da K). Inoltre, la funzione SoftMax viene applicata ai pesi a per avere una distribuzione tra 0 e 1. Questi pesi vengono poi applicati a tutte le parole della sequenza che vengono introdotte in V (gli stessi vettori di Q per il codificatore e il decodificatore, ma diversi per il modulo che ha ingressi di codifica e decodifica).
L’immagine di destra descrive come questo meccanismo di attenzione possa essere parallelizzato in più meccanismi che possono essere utilizzati uno accanto all’altro. Il meccanismo di attenzione viene ripetuto più volte con proiezioni lineari di Q, K e V. Ciò consente al sistema di apprendere da diverse rappresentazioni di Q, K e V, a vantaggio del modello. Queste rappresentazioni lineari sono realizzate moltiplicando Q, K e V per le matrici di peso W apprese durante l’addestramento.
Le matrici Q, K e V sono diverse per ogni posizione dei moduli di attenzione nella struttura, a seconda che si trovino nell’encoder, nel decoder o tra l’encoder e il decoder. Il motivo è che si vuole prestare attenzione all’intera sequenza di ingresso del codificatore o a una parte della sequenza di ingresso del decodificatore. Il modulo di attenzione multitesta che collega l’encoder e il decoder farà in modo che la sequenza di ingresso dell’encoder venga presa in considerazione insieme alla sequenza di ingresso del decoder fino a una determinata posizione.
Dopo le teste di attenzione multipla sia nell’encoder che nel decoder, abbiamo uno strato di feed-forward puntuale. Questa piccola rete feed-forward ha parametri identici per ogni posizione, che possono essere descritti come una trasformazione lineare separata e identica di ogni elemento della sequenza data.
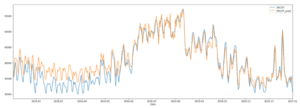
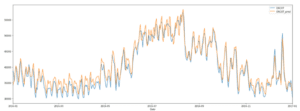
I due grafici seguenti mostrano i risultati. Ho preso il valore medio dei valori orari per giorno e l’ho confrontato con i valori corretti. Il primo grafico mostra le previsioni a 12 ore date le 24 ore precedenti. Nel secondo grafico, abbiamo previsto un’ora in base alle 24 ore precedenti. Si nota che il modello è in grado di cogliere molto bene alcune fluttuazioni. L’errore quadratico medio per il set di addestramento è di 859 e per il set di validazione è di 4.106 per le previsioni a 12 ore e di 2.583 per quelle a 1 ora. Ciò corrisponde a un errore percentuale medio assoluto della previsione del modello dell’8,4% per il primo grafico e del 5,1% per il secondo.