Articolo in lingua originale di Luis Garcia Fuentes
Il Natural Language Processing (NLP) è un potente strumento per l’analisi e la comprensione dei dati testuali. In qualità di analisti, potreste essere nuovi all’NLP e non sapere come iniziare.
Pipeline complessiva di un progetto NLP
In questo corso intensivo di PNL tratteremo le basi della PNL e le sue varie tecniche. In questa prima parte, ci concentreremo sul pre-processing e sulla vettorizzazione, fasi essenziali per preparare i dati ai modelli NLP.
- Pre-processing del testo: include la pulizia, riduzione a lettere minuscole, tokenizzazione, rimozione parole di stop e stemming/lemmatizzazione dei dati testuali. Questo viene fatto per rimuovere il rumore inutile dai dati, mantenendo solo le caratteristiche essenziali del testo.
- Vettorizzazione: Si tratta di convertire i dati testuali pre-elaborati in una rappresentazione numerica che può essere utilizzata dai modelli di apprendimento automatico. È importante ricordare che il calcolo avviene sui numeri e quindi i nostri dati testuali devono essere mappati in una rappresentazione numerica.
Questa sezione è fondamentale e, indipendentemente dall’attività di NLP o dal modello utilizzato per realizzarla, è necessario comprendere chiaramente il contenuto di questo articolo.
Il pre-processing prevede la pulizia e la trasformazione dei dati testuali grezzi in un formato che possa essere facilmente analizzato dai modelli NLP. Di seguito sono riportate alcune tecniche comuni di pre-processing:
- Tokens: La tokenizzazione è il processo di scomposizione di un testo in singole parole, frasi o altri elementi significativi, chiamati token. In NLP, le parole sono tipicamente separate da spazi, ma ci sono casi in cui le parole vengono combinate (ad esempio, parole sillabate) o vengono utilizzati segni di punteggiatura (ad esempio, punti fermi, virgole, punti interrogativi) nella creazione dei token.
Ad esempio, si consideri la frase “La volpe marrone veloce salta il cane pigro”. La tokenizzazione di questa frase tramite spaziatura produrrebbe i seguenti token [“La”, “volpe”, “marrone”, “veloce”, “salta”, “il”, “cane”, “pigro”].
- Stemming e lemmatizzazione: La stemmatizzazione e la lemmatizzazione riducono le parole alla loro forma base o radice. Queste azioni possono contribuire a ridurre il numero di parole uniche in un testo, aumentando l’efficacia del modello nel trovare pattern tra i dati.
- La stemmatizzazione consiste nel rimuovere i suffissi dalle parole per ottenere la forma di base o radice. Ad esempio, lo stelo della parola “salti” è “salto”.
- La lemmatizzazione, invece, consiste nel ridurre le parole alla loro forma base o dizionario, chiamata lemma. Questo processo tiene conto della parte del discorso della parola e del suo contesto nella frase. Ad esempio, il lemma della parola “era” è “essere” e il lemma della parola “saltando” è “saltare”.
- Rimozione delle parole di stop: Le paroel di stop sono parole comuni in in linguaggio che sono generalmente considerate di poco valore in termini di significato o rilevanza all’interno di un testo. Ad esempio “il”, “un”, “una”, “e”, “in”, “a”, “di”, “che”, “è”, “per”, “con” ecc.

Esempio di analisi di un insieme di parole su dati dove le parole di stop non sono state rimosse
Le parole di stop vengono spesso rimosse da un testo durante il pre-processing perché possono rendere più difficile l’analisi e la comprensione del contenuto importante del testo. La rimozione delle stopword può anche contribuire a ridurre le dimensioni di un corpus testuale, il che può essere importante per l’efficienza computazionale e l’archiviazione.
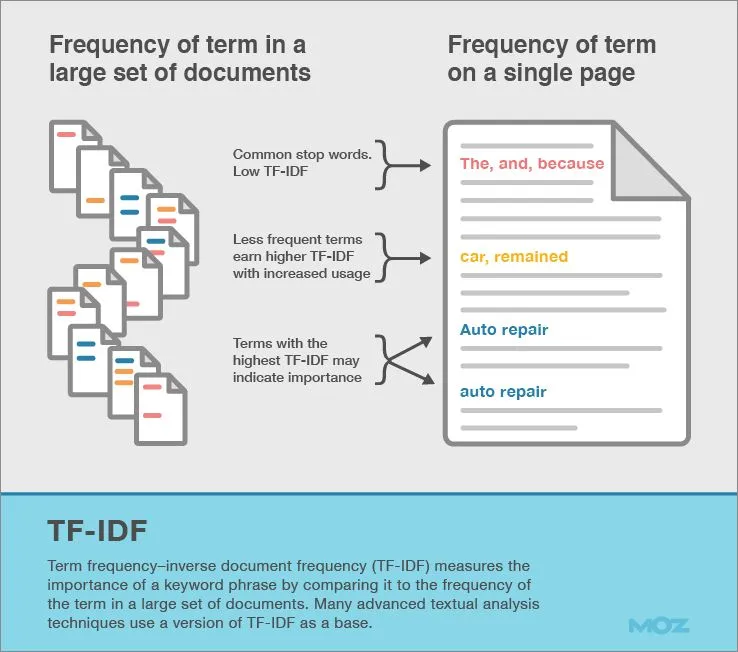
In sostanza, TF-IDF assegna a ogni parola di un documento un punteggio che riflette l’unicità della parola per quel documento. In questo modo si dà meno importanza alle parole che compaiono spesso nei documenti e che quindi si presume non contengano informazioni specifiche relative a quel documento. TF-IDF può essere utilizzato anche per identificare l’argomento dei documenti, in quanto i contenuti specifici relativi a un documento vengono segnalati attraverso punteggi TF-IDF più elevati.
La vettorizzazione consiste nel convertire i dati di testo in un formato numerico che possa essere utilizzato dai modelli NLP. Di seguito sono riportate alcune tecniche di vettorizzazione comuni:
- Bag of words
- Word embedding
- Sentence embedding
Bag of words: Nell’approccio BoW, un documento di testo viene prima tokenizzato, il che comporta la scomposizione del testo in singole parole. Quindi, viene creato un vocabolario di parole uniche, selezionando tutte le parole distinte che compaiono nel documento.
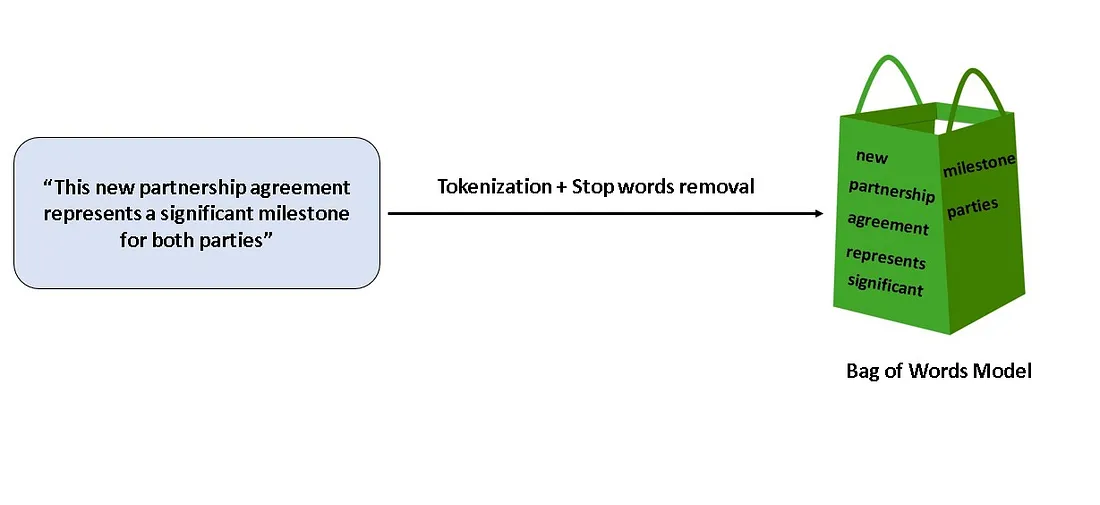
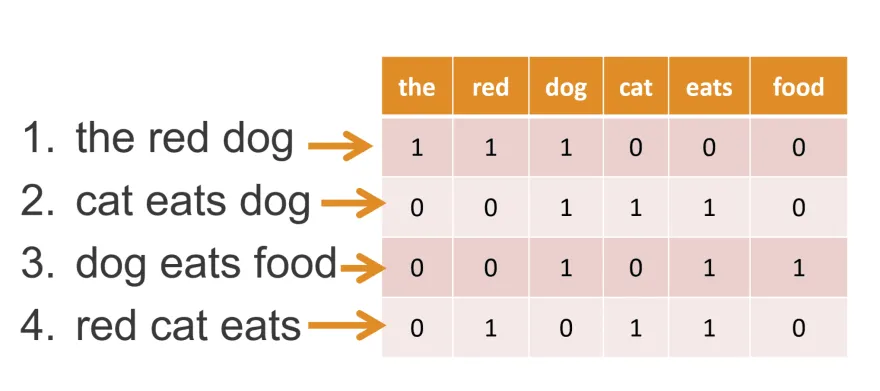
Infine, viene generata una rappresentazione vettoriale del testo contando la frequenza di ogni parola del vocabolario all’interno del testo. Il vettore risultante è chiamato “bag of words” perché rappresenta il testo come una collezione non ordinata di parole.
Ad esempio, si consideri la frase: “Il gatto col cappello inseguiva il topo”. La rappresentazione BoW di questa frase sarebbe un vettore contenente i conteggi di ogni parola della frase: {il: 2, gatto: 1, nel: 1, cappello: 1, inseguiva: 1, topo: 1}.
In un modello BoW, ogni parola è convertita in un vettore one-hot encoded, dove ad ogni parola viene assegnato un indice unico per cui il vettore ad essa associata sarà costituito da tutti zeri eccetto nella posizione a cui corrisponde quella parola.
Mentre BoW è un modello semplice, spesso non è in grado di identificare le complessità del linguaggio come il sarcasmo e l’informazione riguardo il significato o la relazione tra parole.
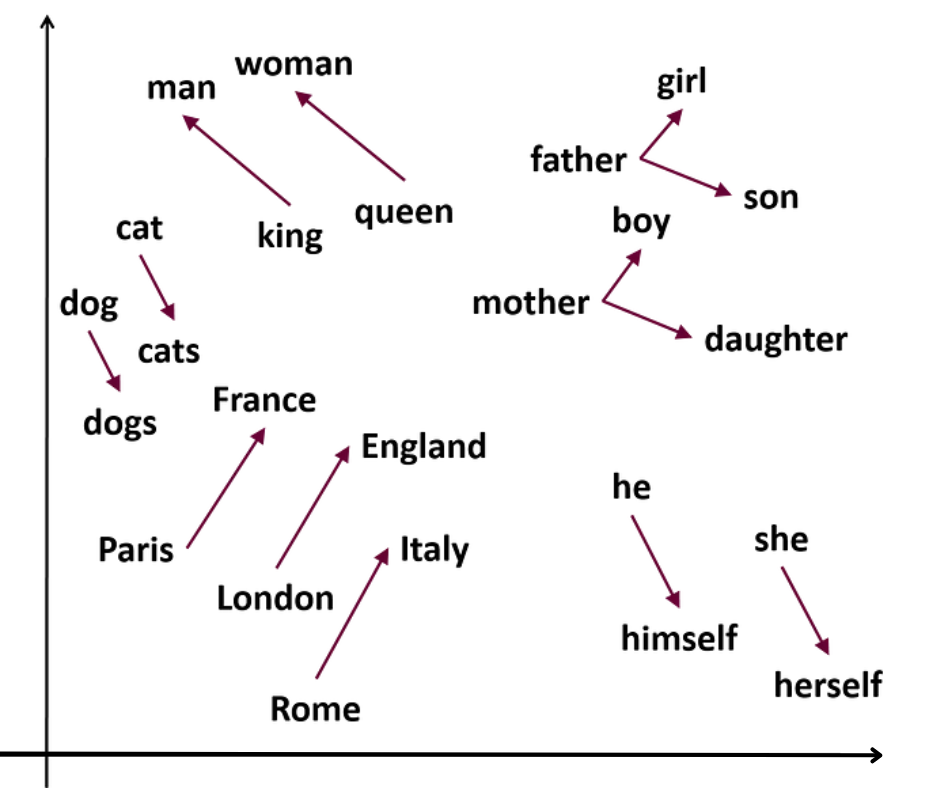
Il word embedding è un tipo di rappresentazione numerica delle parole che cattura il significato e la relazione tra di esse in un modo che può essere compreso da un algoritmo di Machine learning e contiene un contesto linguistico reale.
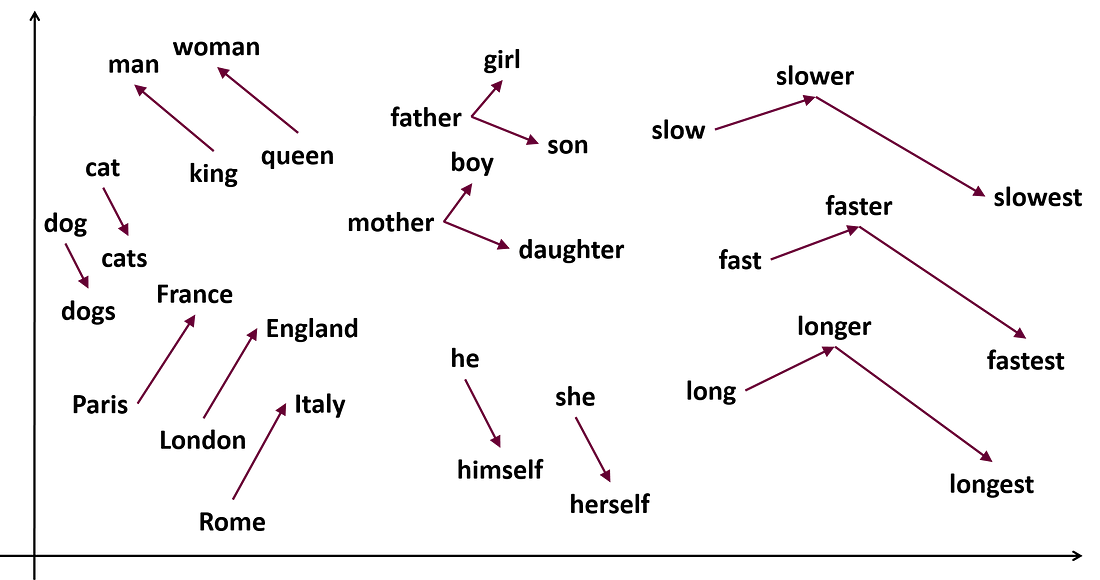
Il Word Embedding risolve le limitazioni del modello BoW rappresentando ogni parola come vettore di numeri tipicamente in uno spazio multidimensionale. Ciascuna dimensione nel vettore rappresenta un aspetto particolare del significato della parola, come le sue proprietà sintattiche o semantiche.
I valori nel vettore sono imparati da un corpo di testo di grandi dimensioni utilizzando tecniche di machine learning non supervisionato, dove l’obiettivo è predire il contesto in cui la parola appare. Allenando il modello su un corpo di testo ampio, l’embedding cattura relazioni statistiche tra le parole ed i loro contesti.
Invece di rappresentare parole specifiche, possiamo rappresentare intere frasi. Il sentence embedding è un modo di rappresentare il significato di una frase in un vettore, dove ciascuna dimensione rappresenta un diverso aspetto del significato della frase. Il sentence embedding viene tipicamente creato attraverso tecniche come la media o il pooling del word embedding delle parole individuali di una frase.
Ci sono metodi più sofisticati per creare sentence embedding oltre al pooling del word embedding. Queste nuove metodologie si basano sulle architetture più recenti di reti neurali. Nonostante non sia necessario capire come queste reti lavorino nel dettaglio, è importante riconoscere che gli algoritmi più recenti non utilizzano il word embedding per arrivare al sentence embedding.
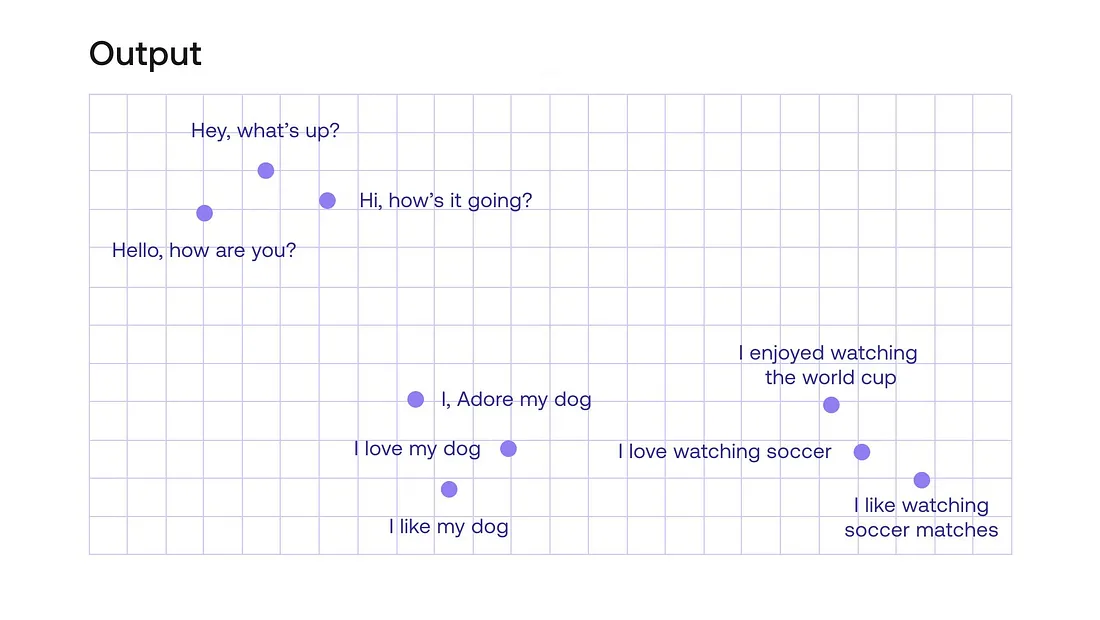
Questi metodi più nuovi possono prendere in considerazione l’ordine e il contesto delle parole in una frase, così come la loro relazione le une rispetto alle altre, ottenendo un sentence embedding più sfumato e informativo.