Diamo un’occhiata al progetto di AI di Meta e implementiamolo in Python
Articolo in lingua originale di Amir Shakiba
https://miro.medium.com/v2/resize:fit:1100/format:webp/1*HQhR89EHQfbBojKXA4vFbQ.png
{kind=link}
Il modello in grado di segmentare tutti gli oggetti (segmen anything model, SAM) sta per rivoluzionare positivamente la computer vision!
Segment Anything Model (SAM) è un modello AI di Facebook progettato per generalizzare la segmentazione. Nel nostro precedente post, abbiamo discusso le caratteristiche generali di SAM e ora approfondiamo i suoi dettagli tecnici.
Altri post relativi a SAM: Instance segmentation with SAM e SAM and stable diffusion
https://miro.medium.com/v2/resize:fit:1100/format:webp/1*Blvl91_qy6PnkXyuzWYgtw.png
{kind=link}
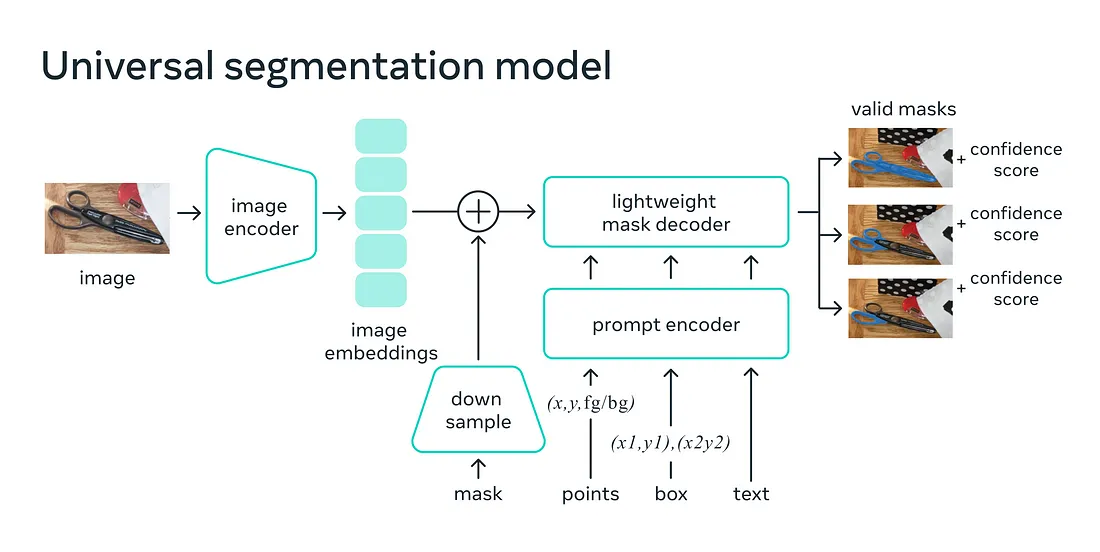
La struttura del modello SAM
Come mostrato nella figura, un’immagine passa attraverso un encoder in modo da ottenerne l’embedding. Successivamente qualsiasi maschera può essere implementata. Il prompt può essere in forma di testo, una bounding box (box di contorno) o punti liberi. Il prompt viene codificato e passato al decoder insieme all’embedding dell’immagine ottenuto con l’encoder. Il decoder genera la maschera.
Una delle caratteristiche più interessanti di SAM sono i suoi encoder e decoder con un ridotto numero di pesi che permettono una performance in tempo reale. E’ possibile utilizzare SAM in Python attraverso il pacchetto disponibile su GitHub: https://github.com/kadirnar/segment-anything-video
Tuttavia, se riscontrate errori lavorandoci, potete utilizzare il file Colab disponibile sulla patina GitHub originale. Ecco come potete iniziare:
using_colab = True
if using_colab:
import torch
import torchvision
print("PyTorch version:", torch.__version__)
print("Torchvision version:", torchvision.__version__)
print("CUDA is available:", torch.cuda.is_available())
import sys
!{sys.executable} -m pip install opencv-python matplotlib
!{sys.executable} -m pip install 'git+https://github.com/facebookresearch/segment-anything.git
!wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
Innanzitutto serve importare Torch e Torchvision che sono necessari per il progetto, e poi installare Segment Anything utilizzando il comando pip. Scaricate un modello checkpoint da questo link:https://github.com/facebookresearch/segment-anything#model-checkpoints, lo useremo più avanti.
Poi, creiamo una cartella per le immagini dove possiamo inserire l’immagine testuale. Si possono usare anche immagini personali sostituendo l’URL nel comando seguente:
!mkdir images !wget -O images/image.jpg https://live.staticflickr.com/65535/49894878561_14a39c6c35_b.jpg
{kind=link}
Una volta che l’immagine è a disposizione, si importano i pacchetti necessari, ovvero numpy, Torch, Matplotlib e OpenCV.
import numpy as np import torch import matplotlib.pyplot as plt import cv2
Per plottare le annotazioni si può utilizzare la funzione seguente:
def show_anns(anns): if len(anns) == 0: return sorted_anns = sorted(anns, key=(lambda x: x['area']), reverse=True) ax = plt.gca() ax.set_autoscale_on(False) polygons = [] color = [] for ann in sorted_anns: m = ann['segmentation'] img = np.ones((m.shape[0], m.shape[1], 3)) color_mask = np.random.random((1, 3)).tolist()[0] for i in range(3): img[:,:,i] = color_mask[i] ax.imshow(np.dstack((img, m*0.35)))
Ora l’immagine viene letta utilizzando OpenCV e i colori vengono cambiati da BGR a RGB per poi mostrare l’immagine attraverso Matplotlib.
image = cv2.imread('images/image.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(20,20))
plt.imshow(image)
plt.axis('off')
plt.show()
https://miro.medium.com/v2/resize:fit:1100/format:webp/1*fdXBINCjXFEyyGlDra-m7A.png
{kind=link}
Sorgente: https://live.staticflickr.com/65535/49894878561_14a39c6c35_b.jpg
Per creare un generatore di maschere, servirà definire il modello sam e utilizzare SamAutomaticMaskGenerator:
import sys
sys.path.append("..")
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor
sam_checkpoint = "sam_vit_h_4b8939.pth" model_type = "vit_h"
device = "cuda"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint) sam.to(device=device)
mask_generator = SamAutomaticMaskGenerator(sam)
Il registro del nostro modello sam considera il checkpoint e il tipo di modello da dare al nostro modello, ricordatevi di settare il runtime a GPU.
SamAutomaticMaskGenerator prende il modello per ottenerne il mask_generator.
Tutto quello che serve fare per ottenere la maschera è passare il proprio input a questa funzione
masks = mask_generator.generate(image)
L’oggetto maschera contiene diverse informazioni sull’area, sul punteggio di stabilità e le etichette verranno successivamente aggiunte a questa maschera.
Diamo un’occhiata all’output:
plt.figure(figsize=(20,20))
plt.imshow(image)
show_anns(masks)
plt.axis('off')
plt.show()
https://miro.medium.com/v2/resize:fit:1100/format:webp/1*HqlFdPLsHIDhP1F8L8AaQQ.png
{kind=link}
Output a cui è stata applicata la maschera
E’ possibile aggiustare i parametri del generatore della maschera cambiando le seguenti variabili:
mask_generator_2 = SamAutomaticMaskGenerator(
model=sam,
points_per_side=32,
pred_iou_thresh=0.86,
stability_score_thresh=0.92,
crop_n_layers=1,
crop_n_points_downscale_factor=2,
min_mask_region_area=100, # Requires open-cv to run post-processing
)
masks2 = mask_generator_2.generate(image)
plt.figure(figsize=(20,20))
plt.imshow(image)
show_anns(masks2)
plt.axis('off')
plt.show()
https://miro.medium.com/v2/resize:fit:1100/format:webp/1*rzFe_hhDobAK9E-r4ctNLg.png
{kind=link}
Un altro output ottenuto con parametri diversi
Grazie per aver speso tempo leggendo questo articolo! Spero lo abbiate trovato utile ed interessante.
Codice sorgente:
Share:
