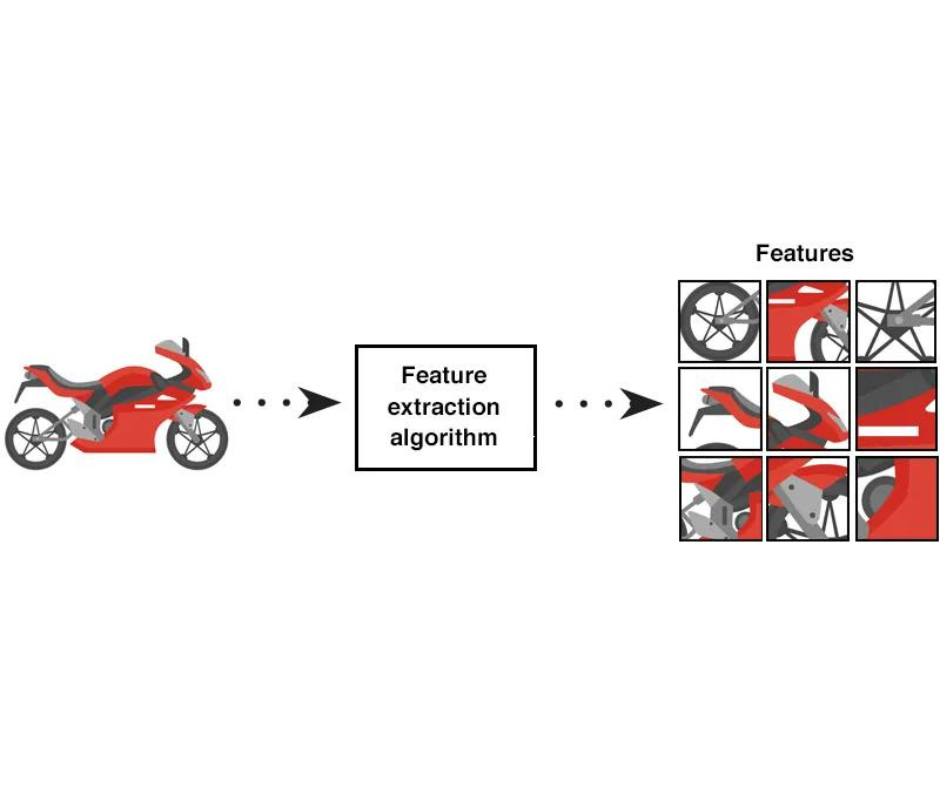
La Feature Engineering è un aspetto cruciale della costruzione di modelli di computer vision di successo. Si tratta di selezionare le caratteristiche (feature) rilevanti e di trasformarle in un formato comprensibile per il modello. La qualità delle caratteristiche utilizzate per addestrare il modello ha un impatto significativo sull’accuratezza dei risultati. Ad esempio, nel rilevamento degli oggetti, la selezione di caratteristiche rilevanti come la forma, il colore e la struttura di un oggetto può aiutare il modello a riconoscere e classificare correttamente l’oggetto.
Il processo di feature engineering nei modelli di computer vision può essere suddiviso in tre fasi: selezione delle caratteristiche, estrazione delle caratteristiche e trasformazione delle caratteristiche.
La selezione delle feature implica la scelta delle caratteristiche più rilevanti per il modello. Ciò avviene analizzando i dati e identificando le caratteristiche che hanno maggiori probabilità di essere importanti nella previsione della variabile target. La selezione delle caratteristiche può essere effettuata manualmente, ma spesso viene automatizzata utilizzando algoritmi di Machine Learning.
L’estrazione delle feature comporta la conversione dei dati grezzi in un formato utilizzabile per l’addestramento del modello. Ciò avviene estraendo le caratteristiche rilevanti dai dati grezzi, come la forma, la struttura o il colore di un oggetto in un’immagine. L’estrazione delle caratteristiche può essere effettuata con diverse tecniche, tra cui le reti neurali convoluzionali (CNN), l’analisi delle componenti principali (PCA) e l’analisi discriminante lineare (LDA).
La trasformazione delle feature comporta la trasformazione delle caratteristiche estratte in un formato utilizzabile dal modello. Ciò avviene applicando operazioni matematiche alle caratteristiche, come lo scaling, la normalizzazione o la standardizzazione.