
Negli ultimi anni i trasformatori hanno conquistato il mondo della PNL. Ora vengono utilizzati con successo anche in applicazioni che vanno oltre la PNL.
Il Transformer ottiene i suoi poteri grazie al modulo di attenzione. Questo avviene perché cattura le relazioni tra ogni parola di una sequenza e ogni altra parola.
.
Ma la domanda fondamentale è: come fa esattamente a farlo?
In questo articolo cercheremo di rispondere a questa domanda e di capire perché esegue i calcoli che esegue.
Ho altri articoli nella mia serie sui trasformatori. In questi articoli abbiamo imparato a conoscere l’architettura dei trasformatori e ne abbiamo analizzato il funzionamento durante l’addestramento e l’inferenza, passo dopo passo. Abbiamo anche esplorato il loro interno e capito esattamente come funzionano in dettaglio.
Il nostro obiettivo è capire non solo come funziona qualcosa, ma anche perché funziona in quel modo.
- Panoramica delle funzionalità (come vengono utilizzati i trasformatori e perché sono migliori delle RNN. Componenti dell’architettura e comportamento durante l’addestramento e l’inferenza).
- Come funziona (Funzionamento interno end-to-end. Come fluiscono i dati e quali calcoli vengono eseguiti, comprese le rappresentazioni matriciali).
- Attenzione a più teste (Funzionamento interno del modulo di attenzione in tutto il trasformatore).
Se siete interessati alle applicazioni della PNL in generale, ho altri articoli che potrebbero interessarvi.
- Beam Search (Algoritmo comunemente usato dalle applicazioni Speech-to-Text e NLP per migliorare le predizioni)
- Bleu Score (Bleu Score e Word Error Rate sono due metriche essenziali per i modelli NLP).
Per capire cosa fa funzionare il Transformer, dobbiamo concentrarci su Attenzione.
Cominciamo con l’input che gli arriva e poi guardiamo come lo elabora.
Il modulo Attention è presente in ogni Encoder dello stack Encoder e in ogni Decoder dello stack Decoder. Per prima cosa ci concentreremo sull’attenzione dell’Encoder.

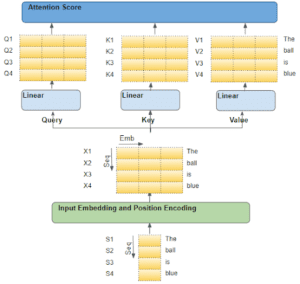
A titolo di esempio, diciamo che stiamo lavorando a un problema di traduzione dall’inglese allo spagnolo, in cui una sequenza campione di partenza è “The ball is blue”. La sequenza di destinazione è “La bola es azul”.
La sequenza di partenza viene prima passata attraverso il livello Embedding and Position Encoding, che genera vettori di incorporamento per ogni parola della sequenza. L’embedding viene passato all’Encoder, dove raggiunge il modulo Attention.
All’interno di Attention, la sequenza incorporata passa attraverso tre livelli Linear che producono tre matrici separate, note come Query, Key e Value. Queste sono le tre matrici utilizzate per calcolare il punteggio di attenzione.
La cosa importante da tenere a mente è che ogni “riga” di queste matrici corrisponde a una parola della sequenza di partenza.
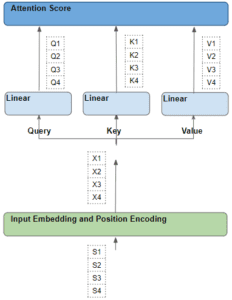
Per capire cosa succede con l’attenzione, si parte dalle singole parole della sequenza di partenza e si segue il loro percorso attraverso il trasformatore. In particolare, vogliamo concentrarci su ciò che accade all’interno del modulo di attenzione.
Questo ci aiuterà a vedere chiaramente come ogni parola della sequenza di partenza e di arrivo interagisce con le altre parole della sequenza di partenza e di arrivo.
Quindi, nel corso di questa spiegazione, concentriamoci sulle operazioni che vengono eseguite su ogni parola e sul modo in cui ogni vettore si rapporta alla parola originale in ingresso. Non è necessario preoccuparsi di molti altri dettagli, come le forme delle matrici, le specifiche dei calcoli aritmetici, le teste di attenzione multiple e così via, se non sono direttamente rilevanti per la destinazione di ogni parola.
Per semplificare la spiegazione e la visualizzazione, ignoriamo la dimensione di incorporazione e teniamo traccia solo delle righe per ogni parola.
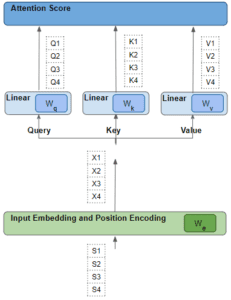
Ogni parola passa attraverso una serie di trasformazioni apprendibili.
Ogni riga è stata generata dalla corrispondente parola di partenza attraverso una serie di trasformazioni: incorporazione, codifica della posizione e strato lineare.
Tutte queste trasformazioni sono operazioni addestrabili.
Ciò significa che i pesi utilizzati in queste operazioni non sono predeterminati, ma vengono appresi dal modello in modo da produrre le previsioni di uscita desiderate.
La domanda chiave è: come fa il Transformer a capire quale serie di pesi gli darà i migliori risultati? Tenete a mente questo punto, perché ci torneremo più avanti.
Attention esegue diverse operazioni, ma qui ci concentreremo solo sul livello lineare e sul punteggio di attenzione.


Come si può vedere dalla formula, il primo passo di Attention consiste nell’eseguire una moltiplicazione matriciale (cioè il prodotto di punti) tra la matrice Query (Q) e la trasposizione della matrice Key (K). Osservate cosa succede a ogni parola.
Si ottiene una matrice intermedia (chiamiamola matrice ‘fattore’) in cui ogni cella è una moltiplicazione matriciale tra due parole.
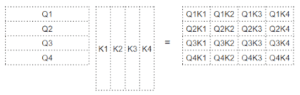
Ad esempio, ogni colonna della quarta riga corrisponde al prodotto di punti tra la quarta parola della query e ogni parola della chiave.

Il passo successivo è una moltiplicazione matriciale tra questa matrice intermedia ‘fattore’ e la matrice Valore (V), per produrre il punteggio di attenzione che viene emesso dal modulo di attenzione. Qui possiamo vedere che la quarta riga corrisponde alla matrice della quarta parola Query moltiplicata per tutte le altre parole Key e Value.

Questo produce il vettore del punteggio di attenzione (Z) che viene emesso dal modulo di attenzione.
Il modo in cui pensare al punteggio in uscita è che, per ogni parola, è il valore codificato di ogni parola dalla matrice “Valore”, ponderato per la matrice “fattore”. La matrice dei fattori è il prodotto puntuale del valore Query di quella specifica parola con il valore Key di tutte le parole.
La parola Query può essere interpretata come la parola per la quale stiamo calcolando l’attenzione. Le parole Chiave e Valore sono le parole a cui stiamo prestando attenzione, cioè quanto è rilevante quella parola per la parola Domanda, quanto è rilevante quella parola rispetto alla parola Query.
Ad esempio, per la frase “La palla è blu”, la riga relativa alla parola “blu” conterrà i punteggi di attenzione per “blu” con ogni altra parola. In questo caso, “blu” è la parola query e le altre parole sono le “chiavi/valori”.
Vengono eseguite altre operazioni, come una divisione e una softmax, ma possiamo ignorarle in questo articolo. Esse modificano solo i valori numerici delle matrici, ma non influiscono sulla posizione di ciascuna riga di parola nella matrice. Inoltre, non comportano alcuna interazione tra le parole.
Abbiamo quindi visto che il punteggio di attenzione coglie un’interazione tra una particolare parola e ogni altra parola della frase, facendo un prodotto di punti e poi sommandoli. Ma in che modo la matrice moltiplicata aiuta il Trasformatore a determinare la rilevanza tra due parole?
Per capirlo, ricordiamo che le righe Query, Key e Value sono in realtà vettori con una dimensione Embedding. Vediamo come viene calcolata la moltiplicazione della matrice tra questi vettori.
Quando si esegue un prodotto di punti tra due vettori, si moltiplicano coppie di numeri e poi si sommano.
– Se i due numeri accoppiati (ad esempio “a” e “d”) sono entrambi positivi o entrambi negativi, il prodotto sarà positivo. Il prodotto aumenterà la somma finale.
– Se un numero è positivo e l’altro negativo, il prodotto sarà negativo. Il prodotto ridurrà la somma finale.
– Se il prodotto è positivo, più i due numeri sono grandi, più contribuiscono alla somma finale.
Ciò significa che se i segni dei numeri corrispondenti nei due vettori sono allineati, la somma finale sarà maggiore.
L’attenzione viene utilizzata nel Trasformatore in tre punti:
– Autoattenzione nell’Encoder: la sequenza sorgente presta attenzione a se stessa.
– Autoattenzione nel decodificatore: la sequenza di destinazione presta attenzione a se stessa.
– Attenzione nel Decodificatore – la sequenza di destinazione presta attenzione alla sequenza di origine.

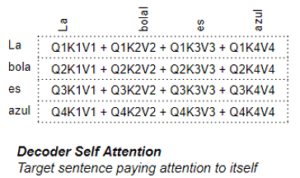
Nell’Encoder Self Attention, calcoliamo la rilevanza di ogni parola della frase di partenza rispetto a ogni altra parola della frase di partenza. Questo avviene in tutti i codificatori dello stack.
Autoattenzione del decodificatore nel trasformatore
La maggior parte di ciò che abbiamo appena visto nell’autoattenzione del codificatore si applica anche all’attenzione del decodificatore, con alcune piccole ma significative differenze.
Nell’autoattenzione del decodificatore, calcoliamo la rilevanza di ogni parola della frase target rispetto a ogni altra parola della frase target.
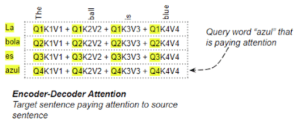
Attenzione codificatore-decodificatore nel trasformatore
Nell’Encoder-Decoder Attention, la Query è ottenuta dalla frase di arrivo e la Chiave/Valore dalla frase di partenza. In questo modo si calcola la rilevanza di ogni parola della frase di arrivo rispetto a ogni parola della frase di partenza.
Conclusione
Spero che questo vi dia un’idea dell’eleganza del design di Transformer. Leggete anche gli altri articoli su Transformer della mia serie per capire meglio perché Transformer è diventato l’architettura preferita per molte applicazioni di deep learning.
Infine, se vi è piaciuto questo articolo, potreste apprezzare anche le mie altre serie sull’Audio Deep Learning, sul Geolocation Machine Learning e sulla Batch Norm.
