Articolo originale in lingua inglese di Paweł Kapica
Riguardo all’autore:
Sono il co-fondatore e CEO di Impeccable.AI. La mia esperienza precedente include lavorare per Microsoft e trattabile su AI/ ML problemi come ML Engineer.
A Impeccable.AI stiamo costruendo una piattaforma di sviluppo AI (ha uno spazio anche per i notebook) per aiutare i team che sviluppano prodotti di IA a lavorare più velocemente e collaborare meglio. Stiamo adottando un approccio orizzontale che offre strumenti che sono “assistenti intelligenti” e offrono la massima flessibilità. Sappiamo che i nostri clienti – gli esperti nei loro domini – sanno esattamente cosa fare e come farlo.

Vorrei condividere il mio codice con le soluzioni ad alcuni problemi con cui ho lottato durante l’attuazione.
Non mi concentrerò molto su aspetti non legati all’attuazione. Presumo che abbiate familiarità con CNN, rilevamento degli oggetti, architettura YOLO v3 ecc. così come Tensorflow e TF-Slim framework. In caso contrario, potrebbe essere meglio iniziare con corrispondenti documenti/ tutorial. Non spiegherò cosa fa ogni singola riga, piuttosto presente il codice di lavoro con spiegazioni su alcuni problemi su cui mi sono imbattuto.
Tutto il codice necessario per eseguire questo rilevatore e alcuni demo sono disponibili nel mio repo GitHub. Ho provato su Ubuntu 16.04, Tensorflow 1.8.0 e CUDA 9.0.
Questo post è organizzato come segue:
- Setup
- Implementazione degli strati Darknet-53
- Implementazione dei livelli di rilevamento YOLO v3
- Conversione dei pesi COCO pre-formati
- Implementazione di algoritmi di post-elaborazione
- Sommario
Nel documento YOLO v3, gli autori presentano una nuova architettura più profonda di estrattore di funzionalità chiamato Darknet-53. Come suggerisce il nome, contiene 53 strati convoluzionali, ciascuno seguito da livello di normalizzazione batch e attivazione Leaky Relu. Il downsampling è fatto dai livelli Conv con stride=2.
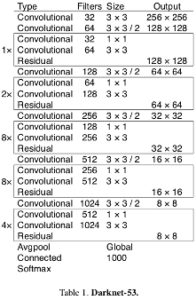
Prima di definire livelli convoluzionali, dobbiamo renderci conto che l’implementazione degli autori utilizza padding fisso indipendentemente dalla dimensione dell’input. Per ottenere lo stesso comportamento, possiamo usare la funzione qui sotto (ho leggermente modificato il codice trovato qui).
@tf.contrib.framework.add_arg_scope
def _fixed_padding(inputs, kernel_size, *args, mode='CONSTANT', **kwargs):
"""
Pads the input along the spatial dimensions independently of input size.
Args:
inputs: A tensor of size [batch, channels, height_in, width_in] or
[batch, height_in, width_in, channels] depending on data_format.
kernel_size: The kernel to be used in the conv2d or max_pool2d operation.
Should be a positive integer.
data_format: The input format ('NHWC' or 'NCHW').
mode: The mode for tf.pad.
Returns:
A tensor with the same format as the input with the data either intact
(if kernel_size == 1) or padded (if kernel_size > 1).
"""
pad_total = kernel_size - 1
pad_beg = pad_total // 2
pad_end = pad_total - pad_beg
if kwargs['data_format'] == 'NCHW':
padded_inputs = tf.pad(inputs, [[0, 0], [0, 0],
[pad_beg, pad_end], [pad_beg, pad_end]], mode=mode)
else:
padded_inputs = tf.pad(inputs, [[0, 0], [pad_beg, pad_end],
[pad_beg, pad_end], [0, 0]], mode=mode)
return padded_inputs
_fixed_padding input pad lungo la dimensione altezza e larghezza con un numero appropriato di 0 (quando mode=’CONSTANT’). Useremo anche mode=’SYMMETRIC’ più avanti.
Adesso possiamo definire la funzione _conv2d_fixed_padding:
def _conv2d_fixed_padding(inputs, filters, kernel_size, strides=1):
if strides > 1:
inputs = _fixed_padding(inputs, kernel_size)
inputs = slim.conv2d(inputs, filters, kernel_size, stride=strides, padding=('SAME' if strides == 1 else 'VALID'))
return inputs
Il modello Darknet-53 è costruito da un certo numero di blocchi con 2 livelli Conv e connessione di collegamento seguita dal livello di downsampling. Per evitare il codice della caldaia, definiamo la funzione _darknet_block: def _darknet53_block(inputs, filters): shortcut = inputs inputs = _conv2d_fixed_padding(inputs, filters, 1) inputs = _conv2d_fixed_padding(inputs, filters * 2, 3) inputs = inputs + shortcut return inputs
Infine, abbiamo tutti i mattoni necessari per il modello Darknet-53:
def darknet53(inputs): """ Builds Darknet-53 model. """ inputs = _conv2d_fixed_padding(inputs, 32, 3) inputs = _conv2d_fixed_padding(inputs, 64, 3, strides=2) inputs = _darknet53_block(inputs, 32) inputs = _conv2d_fixed_padding(inputs, 128, 3, strides=2) for i in range(2): inputs = _darknet53_block(inputs, 64) inputs = _conv2d_fixed_padding(inputs, 256, 3, strides=2) for i in range(8): inputs = _darknet53_block(inputs, 128) inputs = _conv2d_fixed_padding(inputs, 512, 3, strides=2) for i in range(8): inputs = _darknet53_block(inputs, 256) inputs = _conv2d_fixed_padding(inputs, 1024, 3, strides=2) for i in range(4): inputs = _darknet53_block(inputs, 512) return inputs
Originariamente, c’è global avg pool layer e Softmax dopo l’ultimo blocco, ma non sono utilizzati da YOLO v3 (così in realtà, abbiamo 52 strati invece di 53 😉
Le caratteristiche estratte da Darknet-53 sono dirette agli strati di rilevamento. Il modulo di rilevamento è costruito da un certo numero di livelli Conv raggruppati in blocchi, strati di upsampling e 3 livelli Conv con funzione di attivazione lineare, facendo rilevamenti a 3 diverse scale. Iniziamo con la funzione helper di scrittura _yolo_block:
def _yolo_block(inputs, filters): inputs = _conv2d_fixed_padding(inputs, filters, 1) inputs = _conv2d_fixed_padding(inputs, filters * 2, 3) inputs = _conv2d_fixed_padding(inputs, filters, 1) inputs = _conv2d_fixed_padding(inputs, filters * 2, 3) inputs = _conv2d_fixed_padding(inputs, filters, 1) route = inputs inputs = _conv2d_fixed_padding(inputs, filters * 2, 3) return route, inputs
Le attivazioni dal quinto livello del blocco vengono poi instradate ad un altro livello Conv e sovracampionate, mentre le attivazioni dal sesto livello vanno al livello _detection_layerche andremo a definire ora:
def _detection_layer(inputs, num_classes, anchors, img_size, data_format): num_anchors = len(anchors) predictions = slim.conv2d(inputs, num_anchors * (5 + num_classes), 1, stride=1, normalizer_fn=None, activation_fn=None, biases_initializer=tf.zeros_initializer()) shape = predictions.get_shape().as_list() grid_size = _get_size(shape, data_format) dim = grid_size[0] * grid_size[1] bbox_attrs = 5 + num_classes if data_format == 'NCHW': predictions = tf.reshape(predictions, [-1, num_anchors * bbox_attrs, dim]) predictions = tf.transpose(predictions, [0, 2, 1]) predictions = tf.reshape(predictions, [-1, num_anchors * dim, bbox_attrs]) stride = (img_size[0] // grid_size[0], img_size[1] // grid_size[1]) anchors = [(a[0] / stride[0], a[1] / stride[1]) for a in anchors] box_centers, box_sizes, confidence, classes = tf.split(predictions, [2, 2, 1, num_classes], axis=-1) box_centers = tf.nn.sigmoid(box_centers) confidence = tf.nn.sigmoid(confidence) grid_x = tf.range(grid_size[0], dtype=tf.float32) grid_y = tf.range(grid_size[1], dtype=tf.float32) a, b = tf.meshgrid(grid_x, grid_y) x_offset = tf.reshape(a, (-1, 1)) y_offset = tf.reshape(b, (-1, 1)) x_y_offset = tf.concat([x_offset, y_offset], axis=-1) x_y_offset = tf.reshape(tf.tile(x_y_offset, [1, num_anchors]), [1, -1, 2]) box_centers = box_centers + x_y_offset box_centers = box_centers * stride anchors = tf.tile(anchors, [dim, 1]) box_sizes = tf.exp(box_sizes) * anchors box_sizes = box_sizes * stride detections = tf.concat([box_centers, box_sizes, confidence], axis=-1) classes = tf.nn.sigmoid(classes) predictions = tf.concat([detections, classes], axis=-1) return predictions
Questo livello trasforma le previsioni grezze secondo le seguenti equazioni. Poiché YOLO v3 su ogni scala rileva oggetti di dimensioni e proporzioni diverse, viene passato l’argomento ancore, che è un elenco di 3 tuple (altezza, larghezza) per ogni scala. Gli ancoraggi devono essere personalizzati per il set di dati (in questo tutorial useremo gli ancoraggi per il set di dati COCO). Basta aggiungere questa costante da qualche parte sopra yolo_v3.py file.
_ANCHORS = [(10, 13), (16, 30), (33, 23), (30, 61), (62, 45), (59, 119), (116, 90), (156, 198), (373, 326)]
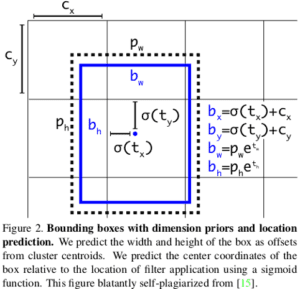
Abbiamo bisogno di una piccola funzione helper _get_size che restituisce altezza e larghezza dell’input:
def _get_size(shape, data_format): if len(shape) == 4: shape = shape[1:] return shape[1:3] if data_format == 'NCHW' else shape[0:2]
Come accennato in precedenza, l’ultimo elemento che dobbiamo implementare YOLO v3 è lo strato di sovracampionamento. Il rivelatore YOLO utilizza il metodo di upsampling bilineare. Perché non possiamo semplicemente usare il metodo standard tf.image.resize_bilinear da Tensorflow API? Il motivo è che, come per oggi (TF versione 1.8.0), tutti i metodi di upsampling utilizzano la modalità pad costante. Il metodo standard pad in YOLO authors repo e in PyTorch is edge (un buon confronto delle modalità padding può essere trovato qui). Questa piccola differenza ha un impatto significativo sui rilevamenti (e mi è costato un paio d’ore di debug).
Per aggirare questo problema, inseriremo manualmente gli ingressi con 1 pixel e mode=’SYMMETRIC’, che è l’equivalente della modalità edge.
# we just need to pad with one pixel, so we set kernel_size = 3 inputs = _fixed_padding(inputs, 3, 'NHWC', mode='SYMMETRIC')
La funzione Whole _upsample figura come di seguito:
def _upsample(inputs, out_shape, data_format='NCHW'): # we need to pad with one pixel, so we set kernel_size = 3 inputs = _fixed_padding(inputs, 3, mode='SYMMETRIC') # tf.image.resize_bilinear accepts input in format NHWC if data_format == 'NCHW': inputs = tf.transpose(inputs, [0, 2, 3, 1]) if data_format == 'NCHW': height = out_shape[3] width = out_shape[2] else: height = out_shape[2] width = out_shape[1] # we padded with 1 pixel from each side and upsample by factor of 2, so new dimensions will be # greater by 4 pixels after interpolation new_height = height + 4 new_width = width + 4 inputs = tf.image.resize_bilinear(inputs, (new_height, new_width)) # trim back to desired size inputs = inputs[:, 2:-2, 2:-2, :] # back to NCHW if needed if data_format == 'NCHW': inputs = tf.transpose(inputs, [0, 3, 1, 2]) inputs = tf.identity(inputs, name='upsampled') return inputs
AGGIORNAMENTO: Grazie a Srikanth Vidapanakal, ho controllato il codice sorgente di darknet e ho scoperto che il metodo di upsampling è il più vicino, non bilineare. Non abbiamo più bisogno di inserire immagini. Il codice aggiornato è già disponibile nel mio repo.
La funzione Fixed _upsample figura come di seguito:
def _upsample(inputs, out_shape, data_format='NCHW'): # tf.image.resize_nearest_neighbor accepts input in format NHWC if data_format == 'NCHW': inputs = tf.transpose(inputs, [0, 2, 3, 1]) if data_format == 'NCHW': new_height = out_shape[3] new_width = out_shape[2] else: new_height = out_shape[2] new_width = out_shape[1] inputs = tf.image.resize_nearest_neighbor(inputs, (new_height, new_width)) # back to NCHW if needed if data_format == 'NCHW': inputs = tf.transpose(inputs, [0, 3, 1, 2]) inputs = tf.identity(inputs, name='upsampled') return inputs
Le attivazioni sovracampionate sono concatenate lungo l’asse dei canali con attivazioni da strati Darknet-53. Questo è il motivo per cui dobbiamo tornare alla funzione darknet53function e restituire le attivazioni dai livelli Conv prima dei livelli di downsampling 4th e 5th.
def darknet53(inputs): """ Builds Darknet-53 model. """ inputs = _conv2d_fixed_padding(inputs, 32, 3) inputs = _conv2d_fixed_padding(inputs, 64, 3, strides=2) inputs = _darknet53_block(inputs, 32) inputs = _conv2d_fixed_padding(inputs, 128, 3, strides=2) for i in range(2): inputs = _darknet53_block(inputs, 64) inputs = _conv2d_fixed_padding(inputs, 256, 3, strides=2) for i in range(8): inputs = _darknet53_block(inputs, 128) route1 = inputs inputs = _conv2d_fixed_padding(inputs, 512, 3, strides=2) for i in range(8): inputs = _darknet53_block(inputs, 256) route2 = inputs inputs = _conv2d_fixed_padding(inputs, 1024, 3, strides=2) for i in range(4): inputs = _darknet53_block(inputs, 512) return route1, route2, inputs
Ora siamo pronti a definire il modulo del rilevatore. Torniamo alla funzione yolo_v3function e aggiungiamo le seguenti righe sotto l’ambito dell’Arg sottile:
with tf.variable_scope('darknet-53'):
route_1, route_2, inputs = darknet53(inputs)
with tf.variable_scope('yolo-v3'):
route, inputs = _yolo_block(inputs, 512)
detect_1 = _detection_layer(inputs, num_classes, _ANCHORS[6:9], img_size, data_format)
detect_1 = tf.identity(detect_1, name='detect_1')
inputs = _conv2d_fixed_padding(route, 256, 1)
upsample_size = route_2.get_shape().as_list()
inputs = _upsample(inputs, upsample_size, data_format)
inputs = tf.concat([inputs, route_2], axis=1 if data_format == 'NCHW' else 3)
route, inputs = _yolo_block(inputs, 256)
detect_2 = _detection_layer(inputs, num_classes, _ANCHORS[3:6], img_size, data_format)
detect_2 = tf.identity(detect_2, name='detect_2')
inputs = _conv2d_fixed_padding(route, 128, 1)
upsample_size = route_1.get_shape().as_list()
inputs = _upsample(inputs, upsample_size, data_format)
inputs = tf.concat([inputs, route_1], axis=1 if data_format == 'NCHW' else 3)
_, inputs = _yolo_block(inputs, 128)
detect_3 = _detection_layer(inputs, num_classes, _ANCHORS[0:3], img_size, data_format)
detect_3 = tf.identity(detect_3, name='detect_3')
detections = tf.concat([detect_1, detect_2, detect_3], axis=1)
return detections
