Inizieremo con un semplice problema di classificazione binaria come mostrato di seguito:

I nostri dati hanno solo due caratteristiche (variabili predittive), x1 e x2 con 6 punti dati – campioni – divisi in 2 etichette diverse. Anche se questo problema è semplice, non è separabile linearmente, il che significa che non possiamo tracciare una singola linea retta attraverso i dati per classificare i punti.
Possiamo comunque disegnare una serie di linee rette che dividono i punti dati in caselle, che chiameremo nodi. Infatti, questo è ciò che fa un albero decisionale durante l’allenamento. In effetti, a un albero decisionale è un modello non-lineare costruito costruendo molti confini lineari.
Per creare un albero decisionale e addestrarlo (fit) sui dati, usiamo Scikit-Learn.
Durante l’allenamento diamo al modello sia le caratteristiche che le etichette in modo che possa imparare a classificare i punti in base alle caratteristiche. (Non abbiamo un set di test per questo semplice problema, ma quando testiamo, diamo solo al modello le caratteristiche e facciamo fare previsioni sulle etichette.)
Possiamo testare l’accuratezza del nostro modello sui dati di allenamento:
Vediamo che ottiene 100% precisione, che è quello che ci aspettiamo perché abbiamo dato le risposte (y) per la formazione e non limitare la profondità dell’albero. Si scopre che questa capacità di apprendere completamente i dati di allenamento può essere un aspetto negativo di un albero di decisione perché può portare a sovradimensionamento come discuteremo in seguito.
Cosa succede quando formiamo un albero decisionale? Trovo un modo utile per capire l’albero decisionale è visualizzarlo, che possiamo fare utilizzando una funzione Scikit-Learn (per i dettagli controllare il notebook o questo articolo).
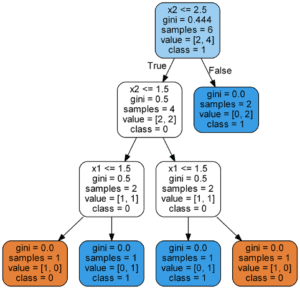
Tutti i nodi, tranne i nodi fogliari (nodi terminali colorati), hanno 5 parti:
- Domanda sui dati basata su un valore di una funzione. Ogni domanda ha una risposta Vero o Falso che divide il nodo. In base alla risposta alla domanda, un punto dati si sposta lungo l’albero.
- gini: L’Impurità di Gini del nodo. L’impurità media ponderata di Gini diminuisce mentre ci muoviamo giù dall’albero.
- samples: Il numero di osservazioni nel nodo.
- value: Il numero di campioni in ciascuna classe. Ad esempio, il nodo superiore ha 2 campioni in classe 0 e 4 campioni in classe 1.
- class: La classificazione di maggioranza per i punti nel nodo. Nel caso dei nodi fogliari, questa è la previsione per tutti i campioni nel nodo.
I nodi del foglio non hanno una domanda perché questi sono dove le previsioni finali sono fatte. Per classificare un nuovo punto, è sufficiente spostarsi lungo l’albero, utilizzando le caratteristiche del punto per rispondere alle domande fino ad arrivare a un nodo foglia in cui la classe è la predizione.
Per far vedere l’albero in un modo diverso, possiamo disegnare le divisioni costruite dall’albero di decisione sui dati originali.
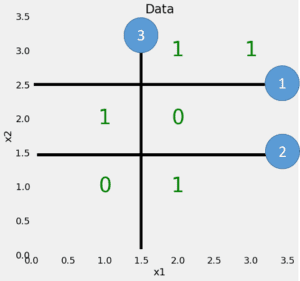
Ogni divisione è una singola riga che divide i punti dati in nodi in base ai valori delle funzionalità. Per questo semplice problema e senza limiti sulla profondità massima, le divisioni posizionano ogni punto in un nodo con solo punti della stessa classe. (Ancora una volta, più tardi vedremo che questa perfetta divisione dei dati di allenamento potrebbe non essere quello che vogliamo perché può portare a sovradimensionamento.)
A questo punto sarà utile immergersi nel concetto di Gini Impurity (la matematica non è intimidatorio!) L’impurità di Gini di un nodo è la probabilità che un campione scelto a caso in un nodo sarebbe erroneamente etichettato se fosse etichettato dalla distribuzione di campioni nel nodo. Ad esempio, nel nodo superiore (radice), c’è una probabilità del 44,4% di classificare in modo errato un punto dati scelto a caso in base alle etichette di esempio nel nodo. Arriviamo a questo valore usando la seguente equazione:
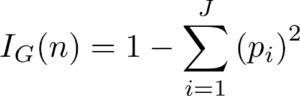
L’impurezza di Gini di un nodo n è 1 meno la somma su tutte le classi J (per un compito di classificazione binaria questo è 2) della frazione di esempi in ogni classe p_i al quadrato. Che potrebbe essere un po’ di confusione a parole, quindi cerchiamo di risolvere l’impurità di Gini del nodo radice.

Ad ogni nodo, l’albero di decisione cerca attraverso le caratteristiche per il valore da dividere su quello provoca la riduzione più grande nell’impurità di Gini. (Un alternativa per dividere i nodi è l’utilizzo del guadagno di informazioni, un concetto correlato).
Quindi ripete questo processo di divisione in una procedura procedura ricorsiva avida fino a raggiungere una profondità massima, o ogni nodo contiene solo campioni da una classe. L’impurità totale ponderata di Gini ad ogni livello dell’albero deve diminuire. Al secondo livello dell’albero, l’impurità ponderata totale di Gini è 0,333:

(L’impurità di Gini di ogni nodo è ponderata per la frazione di punti dal nodo padre in quel nodo.) Puoi continuare a lavorare sull’impurità di Gini per ogni nodo (controlla la visuale per le risposte). Da alcuni calcoli di base, emerge un modello potente!
Alla fine, l’impurità totale ponderata di Gini dell’ultimo strato va a 0, il che significa che ogni nodo è completamente puro e non c’è possibilità che un punto selezionato casualmente da quel nodo venga erroneamente classificato. Anche se questo può sembrare un positivo, significa che il modello potrebbe potenzialmente essere eccessivo perché i nodi sono costruiti solo utilizzando i dati di formazione.
Successivamente, costruiremo una foresta casuale in Python utilizzando Scikit-Learn. Invece di imparare un semplice problema, useremo un set di dati del mondo reale diviso in un set di formazione e test. Usiamo un set di test come una stima di come il modello si esibirà su nuovi dati che ci permette anche di determinare quanto il modello è troppo.
Dataset
Il problema che risolveremo è un compito di classificazione binaria con l’obiettivo di prevedere la salute di un individuo. Le caratteristiche sono socioeconomiche e caratteristiche di stile di vita degli individui e l’etichetta è 0 per cattiva salute e 1 per buona salute. Questo set di dati è stato raccolto dai centri per il controllo e la prevenzione delle malattie ed è disponibile qui.
Generalmente, l’80% di un progetto di data science viene speso per la pulizia, l’esplorazione e la creazione di funzionalità dai dati. Tuttavia, per questo articolo, ci atteniamo alla modellazione. (Per i dettagli degli altri passaggi, guarda questo articolo).
Si tratta di un problema di classificazione squilibrata, quindi la precisione non è una metrica appropriata. Invece misureremo l’area caratteristica operativa del ricevitore sotto la curva (ROC AUC), una misura da 0 (peggiore) a 1 (migliore) con un punteggio casuale 0.5. Possiamo anche tracciare la curva ROC per valutare un modello.
Il notebook contiene l’implementazione sia per l’albero decisionale che per la foresta casuale, ma qui ci concentreremo solo sulla foresta casuale. Dopo aver letto i dati, possiamo istanziare e addestrare una foresta casuale come segue:
Dopo pochi minuti per allenarsi, il modello è pronto a fare previsioni sui dati di test come segue:
Facciamo previsioni di classe (predict) così come le probabilità previste (predict_proba) per calcolare il ROC AUC. Una volta che abbiamo le previsioni di test, possiamo calcolare l’AUC ROC.
Il test finale ROC AUC per la foresta casuale è stato di 0,87 rispetto a 0,67 per l’albero decisionale singolo con una profondità massima illimitata. Se guardiamo i punteggi di allenamento, entrambi i modelli hanno raggiunto 1.0 ROC AUC, che ancora una volta è come previsto perché abbiamo dato a questi modelli le risposte di formazione e non ha limitato la profondità massima di ogni albero.
Sebbene la foresta casuale trabocchi (facendo meglio sui dati di allenamento che sui dati di test), è in grado di generalizzare molto meglio i dati di test rispetto al singolo albero di decisione. La foresta casuale ha una varianza inferiore (buona) pur mantenendo lo stesso bias basso (anche buono) di un albero decisionale.
Possiamo anche tracciare la curva ROC per il singolo albero di decisione (in alto) e la foresta casuale (in basso). Una curva in alto e a sinistra è un modello migliore:
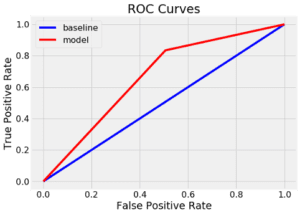
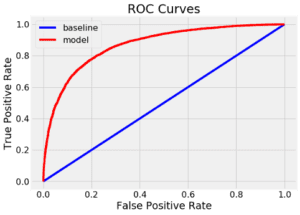
La foresta casuale supera significativamente il singolo albero decisionale.
Un’altra misura diagnostica del modello che possiamo prendere è quella di tracciare la matrice di confusione per le previsioni di test (vedere il notebook per i dettagli):
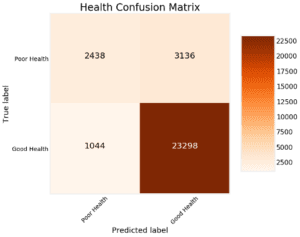
Questo mostra le previsioni che il modello ha ottenuto corrette negli angoli in alto a sinistra e in basso a destra e le previsioni mancate dal modello in basso a sinistra e in alto a destra. Possiamo usare grafici come questi per diagnosticare il nostro modello e decidere se sta facendo abbastanza bene per mettere in produzione.
Le caratteristiche importanti in una random forest indicano la somma della riduzione dell’impurità di Gini su tutti i nodi che sono divisi su quella funzione. Possiamo usarli per cercare di capire quali variabili predittive la foresta casuale considera più importanti. Le importanze delle funzionalità possono essere estratte da una foresta casuale addestrata e messe in un dataframe Pandas come segue:
L’importanza delle funzionalità può darci una visione del problema dicendoci quali sono le variabili più discerninti tra le classi. Ad esempio, qui DIFFWALK, che indica se il paziente ha difficoltà a camminare, è la caratteristica più importante che ha senso nel contesto del problema.
Le funzionalità importanti possono essere utilizzate per l’ingegneria delle funzionalità costruendo funzionalità aggiuntive dai più importanti. Possiamo anche utilizzare funzionalità importances per la selezione caratteristiche rimuovendo le caratteristiche di bassa importanza.
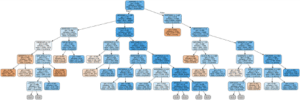
Visualizzare Tree nella Forest
Infine, possiamo visualizzare un singolo albero decisionale nella foresta. Questa volta, dobbiamo limitare la profondità dell’albero altrimenti sarà troppo grande per essere convertito in un’immagine. Per fare la figura qui sotto, ho limitato la profondità massima a 6. Questo si traduce ancora in un grande albero che non possiamo analizzare completamente! Tuttavia, data la nostra profonda immersione nell’albero decisionale, comprendiamo come funziona il nostro modello.
Next Steps
Un ulteriore passo è quello di ottimizzare la foresta casuale che possiamo fare attraverso la ricerca casuale utilizzando il RandomizedSearchCV in Scikit-Learn. L’ottimizzazione si riferisce alla ricerca dei migliori iperparametri per un modello su un dato set di dati. I migliori iperparametri variano tra i set di dati, quindi dobbiamo eseguire l’ottimizzazione (chiamata anche sintonizzazione del modello) separatamente su ciascun set di dati.
Mi piace pensare alla messa a punto del modello come trovare le migliori impostazioni per un algoritmo di apprendimento automatico. Esempi di ciò che potremmo ottimizzare in una foresta casuale sono il numero di alberi di decisione, la profondità massima di ogni albero di decisione, il numero massimo di caratteristiche considerate per dividere ogni nodo e il numero massimo di punti dati richiesti in un nodo foglia.
Per un’implementazione della ricerca casuale per l’ottimizzazione del modello della random forest, fare riferimento al Jupyter Notebook.
Esempio di esecuzione completo
Il codice sottostante viene creato con repl.it e presenta un esempio completo di esecuzione interattiva della foresta casuale in Python. Sentiti libero di eseguire e modificare il codice (il caricamento dei pacchetti potrebbe richiedere alcuni istanti).
Link al tutorial random forest.
Conclusioni
Mentre siamo in grado di costruire potenti modelli di apprendimento automatico in Python senza capire nulla su di loro, Trovo che è più efficace avere la conoscenza di ciò che sta accadendo dietro le quinte. In questo articolo, non solo abbiamo costruito e utilizzato una foresta casuale in Python, ma abbiamo anche sviluppato una comprensione del modello partendo dalle basi.
Abbiamo prima esaminato un albero decisionale individuale, l’elemento costitutivo di una random forest, e poi abbiamo visto come possiamo superare l’elevata varianza di un singolo albero decisionale combinandone centinaia in un modello complessivo noto come random forest. Questa utilizza i concetti di campionamento casuale di osservazioni, campionamento casuale di caratteristiche e previsioni di media.
I concetti chiave per capire da questo articolo sono:
- Albero decisionale: un modello intuitivo che prende decisioni sulla base di una sequenza di domande sui valori delle funzionalità. Ha un basso bias e un’elevata varianza che porta a sovradimensionare i dati di allenamento.
- Impurità di Gini: una misura che l’albero di decisione cerca di minimizzare quando si divide ogni nodo. Rappresenta la probabilità che un campione selezionato casualmente da un nodo venga classificato in modo errato in base alla distribuzione dei campioni nel nodo.
- Bootstrapping: campionamento di gruppi casuali di osservazioni con sostituzione.
- Sottoinsiemi casuali di caratteristiche: selezionando un insieme casuale delle caratteristiche quando si considerano le suddivisioni per ogni nodo in un albero di decisione.
- Random Forest: modello ensemble fatto di molti alberi di decisione utilizzando bootstrapping, sottoinsiemi casuali di caratteristiche, e voto medio per fare previsioni. Questo è un esempio di un insieme di bagging.
- Correzione della distorsione: un problema fondamentale nel machine learning che descrive l’equilibrio tra un modello con elevata flessibilità (elevata varianza) che impara molto bene i dati di allenamento a costo di non essere in grado di generalizzare a nuovi dati , e un modello inflessibile (alto bias) che non può apprendere i dati di allenamento. Una random forest riduce la varianza di un singolo albero di decisione che porta a migliori previsioni sui nuovi dati.
Speriamo che questo articolo vi ha dato la fiducia e la comprensione necessarie per iniziare a utilizzare la random forest sui vostri progetti. La foresta casuale è un potente modello di apprendimento automatico, ma questo non dovrebbe impedirci di sapere come funziona. Più sappiamo di un modello, meglio saremo attrezzati per usarlo efficacemente e spiegare come fa previsioni.
Come sempre, accolgo con favore commenti, feedback e critiche costruttive. Posso essere raggiunto su Twitter @koehrsen_will. Questo articolo è stato originariamente pubblicato su enlight, una comunità open-source per studiare l’apprendimento automatico. Vorrei ringraziare enlight e anche repl.it per ospitare il codice nell’articolo.
Articoli su Towards Data Science: https://williamkoehrsen.medium.com
Profilo Linkedin: https://www.linkedin.com/in/william-koehrsen-48a643a5/
