Articolo in lingua originale di Semih Gülüm

Negli studi di machine learning e deep learning, lo scopo principale è quello di minimizzare la funzione di perdita. Per raggiungere il minimo il prima possibile, è necessario inizializzare i pesi in base al nostro caso. Questo problema è chiamato “inizializzazione dei pesi”. La prima cosa da sapere è che si tratta di una decisione da prendere in fase di progettazione. Prima di addestrare la rete, è necessario inizializzare tutti i pesi. I valori iniziali dei pesi possono avere un impatto significativo sul processo di addestramento. A seconda del punto da cui il modello di deep learning parte nel processo di addestramento, può convergere verso uno qualsiasi dei possibili minimi locali della superficie di perdita irregolare.
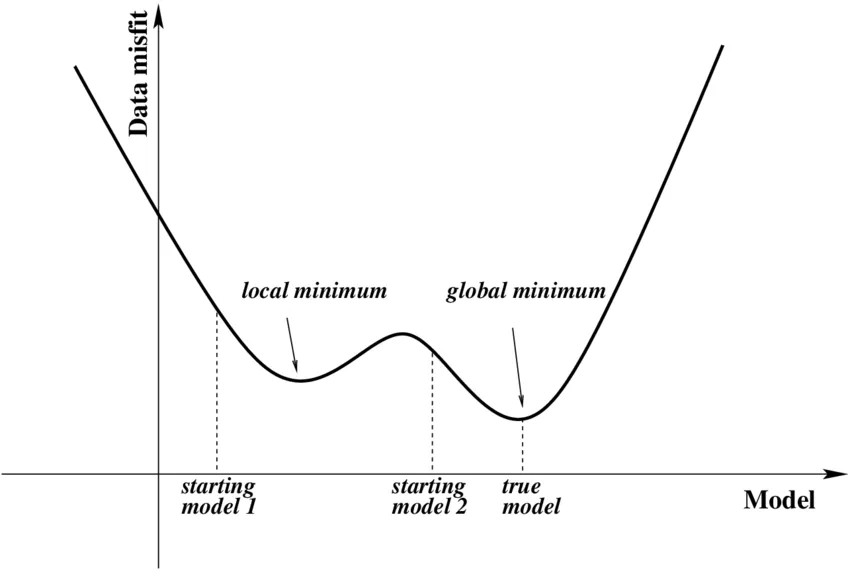
Riflettiamo insieme. Se iniziamo tutti i pesi da 0, sarà una scelta sbagliata sia in termini di tempo che di costi. Oppure ha senso farli partire tutti da 0.5? Iniziare con i pesi sbagliati porta a un gradiente che esplode o che svanisce durante la discesa del gradiente? La risposta è sì! Ecco perché abbiamo bisogno di un’inizializzazione.
- Il risultato dell’addestramento di una rete neurale artificiale dipende dal setting iniziale dei pesi e dei bias
- La discesa del gradiente stocastico (SGD) converge ad un minimo locale
- Per evitare problemi di evanescenza o esplosione del gradiente. (Inizializzazioni tropp ograndi portano all’esplosione del gradiente, mentre inizializzazioni troppo piccole portano ad un gradiente che svanisce)
Quando la funzione di attivazione è sigmoide, più il valore del peso è lontano da 0, più grande è la deviazione standard, più il valore di uscita è distorto vicino a 0 e 1, e quindi il gradiente viene perso. Un modo per risolvere questo problema è quello di inizializzare i pesi in una distribuzione normale con una piccola deviazione standard. In generale, i pesi iniziali sono inizializzati in modo casuale con una distribuzione normale (distribuzione gaussiana) con una media di 0 e una deviazione standard di 0,01 come segue
![]()
# With normal distributions model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(64, 32)), tf.keras.layers.Dense(128, activation='relu', kernel_initializer='RandomNormal', bias_initializer='zeros') ]) ''' # With Uniform Distributions model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(64, 32)), tf.keras.layers.Dense(128, activation='relu', kernel_initializer='RandomUniform', bias_initializer='zeros') '''
