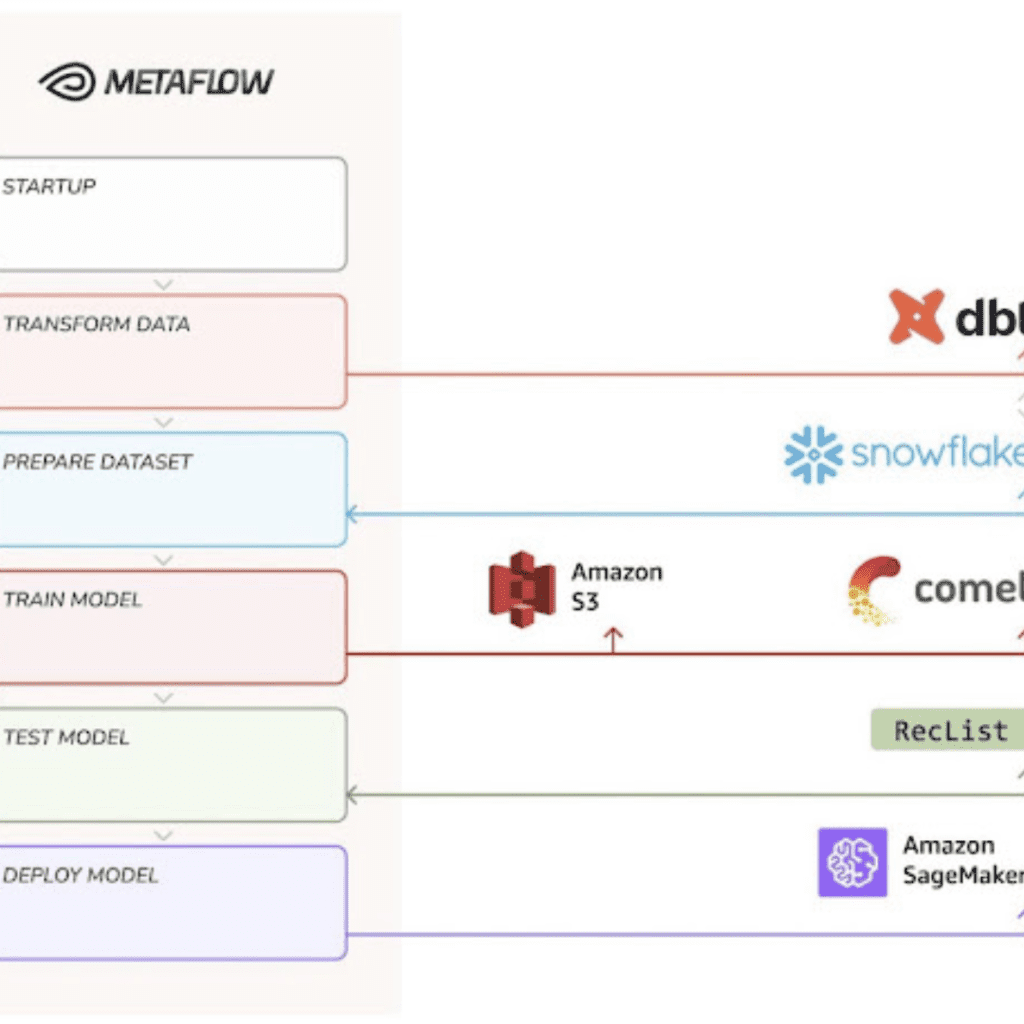
Poiché un diagramma di flusso vale più di mille README, il nostro Post-Modern Stack (PMS) si presenta così:
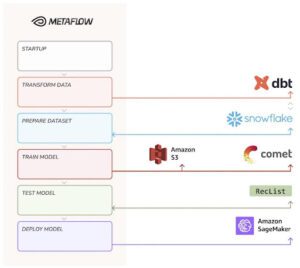
- Archiviazione: utilizziamo Snowflake per archiviare i dati grezzi – riutilizziamo il fantastico set di dati aperti per l’e-commerce rilasciato da Coveo lo scorso anno, contenente milioni di eventi di acquisto anonimizzati nel mondo reale.
- Trasformazione: usiamo dbt come framework di trasformazione – eseguiamo una serie di query SQL di tipo DAG all’interno di Snowflake e prepariamo i nostri dati grezzi per essere consumati dal codice Python.
- Formazione: utilizziamo un framework di deep learning, Keras, per addestrare un modello sequenziale per le raccomandazioni sugli acquisti: dato un elenco di prodotti con cui l’acquirente ha interagito, qual è l’interazione successiva più probabile?
- Serving: utilizziamo Sagemaker come piattaforma di servicing PaaS, in modo che i) possiamo utilizzare codice Python per attivare il deployment e ii) utilizzando AWS, otteniamo un’ottima interoperabilità con Metaflow (cioè gli artefatti del modello sono già in s3).
Il PDP non è particolarmente più complesso della pipeline Metaflow standard: delegando le aggregazioni a Snowflake, il calcolo distribuito è astratto per una scala ragionevole; introducendo il supporto per il dbt, lo scienziato end-to-end può preparare le proprie caratteristiche e versionare il proprio set di dati in un’unica mossa; utilizzando Metaflow, possiamo eseguire tutto il codice Python che vogliamo, dove vogliamo: possiamo unire dataOps e MLOps in un modo unificato e basato su principi, e possiamo scegliere dove è necessaria l’accelerazione hardware.
Il PDP è una pipeline a costo zero, senza fronzoli ma del tutto realistica, per iniziare a trasformare i dati grezzi in previsioni in tempo reale.
Meglio ancora, si tratta di una pipeline fortemente basata sull’open-source e che richiede poco tempo: lo sviluppo, l’addestramento e la distribuzione possono essere eseguiti da un ingegnere di ML senza alcuna conoscenza dell’infrastruttura e senza richiedere il supporto di devOps.
Prima di esplorare tutte le conseguenze di questa configurazione per l’organizzazione, e non solo per il codice, può essere un buon momento per menzionare alcune gemme nascoste per il lettore interessato ai dettagli nerd:
– dbt cloud: dbt offre una versione SaaS del suo strumento per la collaborazione all’interno e tra i team. Per supportare questo scenario, includiamo la possibilità di eseguire lo stesso flusso collegandosi a un’istanza dbt cloud: sebbene sia un po’ meno intuitivo dal punto di vista del flusso, riteniamo che l’offerta cloud abbia un valore, soprattutto in un’organizzazione più grande con un insieme più diversificato di persone coinvolte nello stack di dati.
– Test del modello: includiamo una fase di test prima della distribuzione per sensibilizzare sull’importanza di un test approfondito prima della distribuzione. Combiniamo la potenza di RecList con le schede Metaflow per mostrare come il software open-source possa aiutare a sviluppare modelli più affidabili e una documentazione più completa. Restate sintonizzati per un’integrazione più profonda nel prossimo futuro!
In un momento di fioritura, ma anche di crescita confusa dello spazio, ci auguriamo che il nostro stack aperto fornisca un primo passo affidabile per i team che stanno testando le acque di MLOps, mostrando come pochi, semplici pezzi facciano molta strada verso la costruzione di sistemi ML su scala.
Non sarà la fine del vostro viaggio, ma crediamo che possa essere un ottimo inizio.