I trasformatori sono un tipo di architettura di rete neurale che sta guadagnando popolarità. I trasformatori sono stati recentemente utilizzati da OpenAI nei suoi modelli linguistici e da DeepMind per AlphaStar, il suo programma per sconfiggere un giocatore professionista di Starcraft.
I trasformatori sono stati sviluppati per risolvere il problema della trasduzione di sequenze, o traduzione automatica neurale. Si tratta di qualsiasi attività che trasforma una sequenza di input in una sequenza di output. Ciò include il riconoscimento vocale, la trasformazione da testo a voce, ecc.

Affinché i modelli possano eseguire la trasduzione di sequenze, è necessario disporre di una sorta di memoria. Per esempio, supponiamo di dover tradurre la seguente frase in un’altra lingua (il francese):
“I Transformers” sono una band [[hardcore punk]] giapponese. Il gruppo si è formato nel 1968, all’apice della storia della musica giapponese”.
In questo esempio, la parola “il gruppo” nella seconda frase si riferisce al gruppo “The Transformers” introdotto nella prima frase. Quando si legge della band nella seconda frase, si sa che ci si riferisce alla band “The Transformers”. Questo può essere importante per la traduzione. Ci sono molti esempi in cui le parole di alcune frasi fanno riferimento a parole di frasi precedenti.
Per tradurre frasi di questo tipo, un modello deve capire questo tipo di dipendenze e connessioni. Le reti neurali ricorrenti (RNN) e le reti neurali convoluzionali (CNN) sono state utilizzate per affrontare questo problema grazie alle loro proprietà. Se siete ancora alle prime armi con questo tipo di reti neurali, vi consiglio il nostro corso di Deep Learning. Se invece siete già preparati, esaminiamo queste due architetture e i loro svantaggi.
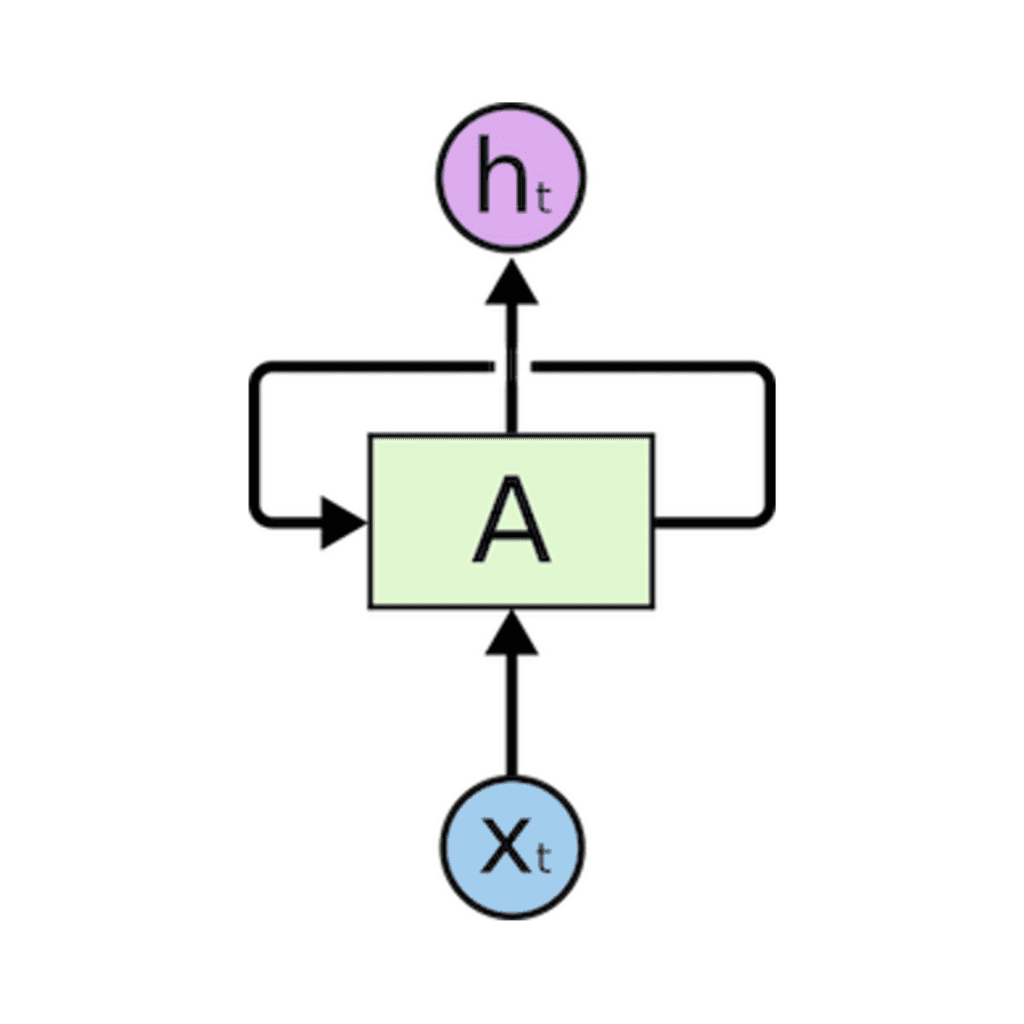
Le reti neurali ricorrenti sono dotate di cicli che consentono di mantenere le informazioni.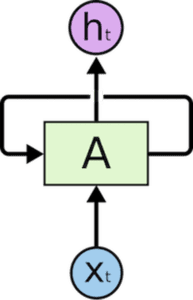
Nella figura precedente, vediamo una parte della rete neurale, A, che elabora alcuni input x_t e gli output h_t. Un ciclo permette di passare informazioni da un passaggio all’altro.
I loop possono essere pensati in un altro modo. Una rete neurale ricorrente può essere considerata come più copie della stessa rete, A, ciascuna delle quali passa un messaggio al suo successore. Consideriamo cosa succede se srotoliamo il loop:
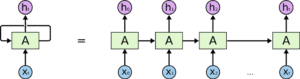
Questa natura a catena dimostra che le reti neurali ricorrenti sono chiaramente collegate a sequenze ed elenchi. In questo modo, se vogliamo tradurre un testo, possiamo impostare ogni ingresso come la parola di quel testo. La rete neurale ricorrente passa le informazioni delle parole precedenti alla rete successiva, che può utilizzarle ed elaborarle.
L’immagine seguente mostra come funziona un modello sequenza-sequenza utilizzando le reti neurali ricorrenti. Ogni parola viene elaborata separatamente e la frase risultante viene generata passando uno stato nascosto alla fase di decodifica che, quindi, genera l’output.
Consideriamo un modello linguistico che cerca di prevedere la parola successiva sulla base di quelle precedenti. Se stiamo cercando di prevedere la parola successiva della frase “le nuvole nel cielo”, non abbiamo bisogno di ulteriore contesto. È abbastanza ovvio che la parola successiva sarà cielo.
In questo caso, in cui la differenza tra le informazioni rilevanti e il luogo necessario è minima, le RNN possono imparare a utilizzare le informazioni passate e a capire qual è la parola successiva della frase.
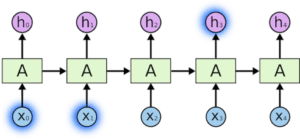 Ma ci sono casi in cui abbiamo bisogno di un contesto più ampio. Per esempio, supponiamo che si stia cercando di prevedere l’ultima parola del testo: “Sono cresciuto in Francia… parlo correntemente…”. Le informazioni recenti suggeriscono che la parola successiva è probabilmente una lingua, ma se vogliamo restringere il campo a quale lingua, abbiamo bisogno del contesto della Francia, che si trova più indietro nel testo.
Ma ci sono casi in cui abbiamo bisogno di un contesto più ampio. Per esempio, supponiamo che si stia cercando di prevedere l’ultima parola del testo: “Sono cresciuto in Francia… parlo correntemente…”. Le informazioni recenti suggeriscono che la parola successiva è probabilmente una lingua, ma se vogliamo restringere il campo a quale lingua, abbiamo bisogno del contesto della Francia, che si trova più indietro nel testo.
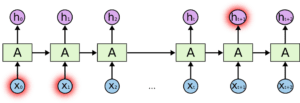
Le RNN diventano molto inefficaci quando lo scarto tra l’informazione rilevante e il punto in cui è necessaria diventa molto grande.
. Ciò è dovuto al fatto che l’informazione viene trasmessa a ogni passo e più lunga è la catena, più è probabile che l’informazione venga persa lungo la catena.
In teoria, le RNN potrebbero imparare queste dipendenze a lungo termine. In pratica, non sembrano impararle. LSTM, un tipo speciale di RNN, cerca di risolvere questo tipo di problema.
Quando organizziamo l’agenda per la giornata, diamo priorità agli appuntamenti. Se c’è qualcosa di importante, possiamo cancellare alcune riunioni e sistemare ciò che è importante.
Le RNN non fanno così. Ogni volta che aggiungono nuove informazioni, trasformano completamente quelle esistenti applicando una funzione. L’intera informazione viene modificata e non si tiene conto di ciò che è importante o meno.
Gli LSTM apportano piccole modifiche alle informazioni mediante moltiplicazioni e aggiunte. Con gli LSTM, l’informazione scorre attraverso un meccanismo noto come stati di cella. In questo modo, gli LSTM possono ricordare o dimenticare selettivamente le cose importanti e quelle meno importanti.
Internamente, un LSTM si presenta come segue:
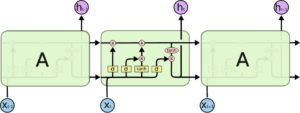
Ogni cella prende in ingresso x_t (una parola nel caso di una traduzione da frase a frase), lo stato della cella precedente e l’uscita della cella precedente. Manipola questi input e, sulla base di essi, genera un nuovo stato della cella e un output. Non entrerò nel dettaglio della meccanica di ciascuna cella.
Con lo stato di una cella, le informazioni di una frase importanti per la traduzione di una parola possono passare da una parola all’altra, durante la traduzione.
Per risolvere alcuni di questi problemi, i ricercatori hanno creato una tecnica per prestare attenzione a parole specifiche.
Quando traduco una frase, presto particolare attenzione alla parola che sto traducendo. Quando trascrivo una registrazione audio, ascolto attentamente il segmento che sto scrivendo. E se mi chiedete di descrivere la stanza in cui sono seduto, do un’occhiata agli oggetti che sto descrivendo.
Le reti neurali possono ottenere questo stesso comportamento utilizzando l’attenzione, concentrandosi su una parte di un sottoinsieme delle informazioni che vengono loro fornite. Ad esempio, una RNN può prestare attenzione all’output di un’altra RNN. A ogni passo temporale, si concentra su posizioni diverse dell’altra RNN.
Per risolvere questi problemi, l’attenzione è una tecnica utilizzata nelle reti neurali. Per le RNN, invece di codificare l’intera frase in uno stato nascosto, ogni parola ha uno stato nascosto corrispondente che viene trasmesso fino alla fase di decodifica. Quindi, gli stati nascosti vengono utilizzati in ogni fase della RNN per la decodifica. La figura seguente mostra come ciò avviene.
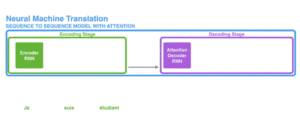
L’idea alla base è che ogni parola di una frase può contenere informazioni rilevanti. Quindi, affinché la decodifica sia precisa, deve prendere in considerazione ogni parola dell’input, utilizzando l’attenzione.
Per portare l’attenzione alle RNN nella trasduzione di sequenze, dividiamo la codifica e la decodifica in due fasi principali. Una fase è rappresentata in verde e l’altra in viola. La fase verde è chiamata fase di codifica e quella viola fase di decodifica.

La fase in verde si occupa di creare gli stati nascosti a partire dall’input. Invece di passare un solo stato nascosto ai decodificatori, come facevamo prima usando l’attenzione, passiamo tutti gli stati nascosti generati da ogni “parola” della frase alla fase di decodifica. Ogni stato nascosto viene utilizzato nella fase di decodifica, per capire dove la rete deve prestare attenzione.
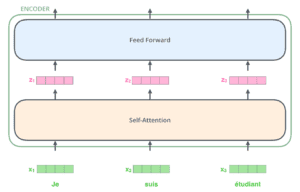
Ad esempio, quando si traduce la frase “Je suis étudiant” in inglese, è necessario che la fase di decodifica prenda in considerazione diverse parole.

Oppure, ad esempio, quando si traduce la frase “L’accord sur la zone économique européenne a été signé en août 1992” dal francese all’inglese, e quanta attenzione viene prestata a ciascun input.

Ma alcuni dei problemi che abbiamo discusso non sono ancora stati risolti con le RNN che utilizzano l’attenzione. Ad esempio, non è possibile elaborare gli input (parole) in parallelo. Per un corpus di testi di grandi dimensioni, questo aumenta il tempo di traduzione del testo.
Le reti neurali convoluzionali aiutano a risolvere questi problemi. Con esse è possibile
– Sono banalmente parallelizzabili (per strato)
– Sfrutta le dipendenze locali
– La distanza tra le posizioni è logaritmica
Alcune delle reti neurali più popolari per la trasduzione di sequenze, Wavenet e Bytenet, sono reti neurali convoluzionali.

Il motivo per cui le reti neurali convoluzionali possono lavorare in parallelo è che ogni parola in ingresso può essere elaborata contemporaneamente e non dipende necessariamente dalle parole precedenti da tradurre. Non solo, ma la “distanza” tra la parola in uscita e qualsiasi ingresso per una CNN è dell’ordine di log(N) – cioè la dimensione dell’altezza dell’albero generato dall’uscita all’ingresso (si può vedere nella GIF qui sopra. Questo è molto meglio della distanza tra l’uscita di una RNN e un ingresso, che è dell’ordine di N.
Il problema è che le reti neurali convoluzionali non aiutano necessariamente a risolvere il problema delle dipendenze nella traduzione delle frasi. Per questo motivo sono stati creati i Transformers, una combinazione di CNN e di attenzione.
Per risolvere il problema della parallelizzazione, i Transformers cercano di risolvere il problema utilizzando le reti neurali convoluzionali insieme ai modelli di attenzione. L’attenzione aumenta la velocità di traduzione del modello da una sequenza all’altra.
Vediamo come funziona Transformer. Transformer è un modello che utilizza l’attenzione per aumentare la velocità. Più precisamente, utilizza l’autoattenzione.

Internamente, il Transformer ha un’architettura simile a quella dei modelli precedenti.
Ma il Transformer è composto da sei codificatori e sei decodificatori.
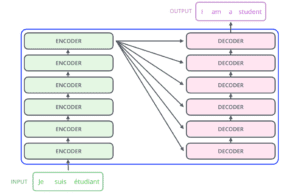
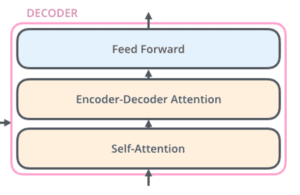
Ogni encoder è molto simile all’altro. Tutti i codificatori hanno la stessa architettura. I decodificatori condividono la stessa proprietà, cioè sono anch’essi molto simili tra loro. Ogni codificatore è composto da due strati: Autoattenzione e Rete neurale feed forward.
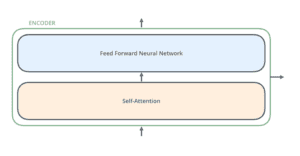
Gli input del codificatore passano prima attraverso uno strato di autoattenzione. Questo strato aiuta il codificatore a guardare le altre parole della frase in ingresso mentre codifica una parola specifica. Il decodificatore ha entrambi questi livelli, ma tra di essi c’è un livello di attenzione che aiuta il decodificatore a concentrarsi sulle parti rilevantidella frase in ingresso.
Nota: questa sezione proviene dal post di Jay Allamar sul blog
Cominciamo a esaminare i vari vettori/tensori e il modo in cui fluiscono tra questi componenti per trasformare l’input di un modello addestrato in un output. Come avviene nelle applicazioni NLP in generale, iniziamo a trasformare ogni parola in ingresso in un vettore utilizzando un algoritmo di embedding.

Ogni parola è incorporata in un vettore di dimensioni 512. Rappresenteremo questi vettori con queste semplici caselle.
L’incorporazione avviene solo nel codificatore più in basso. L’astrazione comune a tutti i codificatori è che essi ricevono un elenco di vettori di dimensione 512 ciascuno.
Nel codificatore in basso si tratta dell’incorporamento delle parole, mentre negli altri codificatori si tratta dell’output del codificatore che si trova direttamente sotto. Dopo aver incorporato le parole nella nostra sequenza di ingresso, ognuna di esse passa attraverso ciascuno dei due livelli del codificatore.
Qui cominciamo a vedere una proprietà chiave del trasformatore, ovvero che la parola in ogni posizione scorre attraverso il proprio percorso nel codificatore. Nel livello di autoattenzione esistono dipendenze tra questi percorsi. Il livello feed-forward, invece, non ha queste dipendenze e quindi i vari percorsi possono essere eseguiti in parallelo mentre scorrono nel livello feed-forward.
In seguito, cambieremo l’esempio con una frase più breve e vedremo cosa succede in ciascun sottolivello del codificatore.
Vediamo innanzitutto come calcolare l’autoattenzione utilizzando i vettori, per poi passare a vedere come viene effettivamente implementata: utilizzando le matrici.
Il primo passo per calcolare l’autoattenzione è creare tre vettori da ciascuno dei vettori di ingresso del codificatore (in questo caso, l’incorporazione di ogni parola). Quindi, per ogni parola, creiamo un vettore Query, un vettore Key e un vettore Value. Questi vettori vengono creati moltiplicando l’embedding per tre matrici che abbiamo addestrato durante il processo di formazione.
Si noti che questi nuovi vettori hanno una dimensione inferiore a quella del vettore embedding. La loro dimensione è di 64, mentre i vettori di input/output dell’embedding e dell’encoder hanno una dimensione di 512. Non è necessario che siano più piccoli, si tratta di una scelta architettonica per rendere costante il calcolo dell’attenzione a più teste.
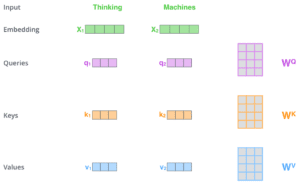
Moltiplicando x1 per la matrice dei pesi WQ si ottiene q1, il vettore “query” associato a quella parola. Alla fine si crea una proiezione “query”, una “chiave” e una “valore” di ogni parola della frase in ingresso.
Cosa sono i vettori “query”, “chiave” e “valore”?
Sono astrazioni utili per calcolare e pensare all’attenzione. Una volta che avrete letto come viene calcolata l’attenzione, saprete più o meno tutto quello che c’è da sapere sul ruolo di ciascuno di questi vettori.
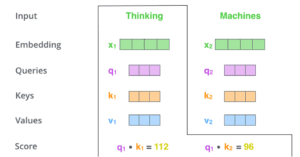
La seconda fase del calcolo dell’autoattenzione consiste nel calcolare un punteggio. Supponiamo di calcolare l’autoattenzione per la prima parola di questo esempio, “Pensare”. Dobbiamo assegnare un punteggio a ogni parola della frase in ingresso rispetto a questa parola. Il punteggio determina la quantità di attenzione da porre sulle altre parti della frase in ingresso mentre codifichiamo una parola in una certa posizione.
Il punteggio viene calcolato prendendo il prodotto del punto del vettore query con il vettore chiave della rispettiva parola che stiamo valutando. Quindi, se stiamo elaborando l’autoattenzione per la parola in posizione #1, il primo punteggio sarà il prodotto del punto di q1 e k1. Il secondo punteggio sarà il prodotto del punto di q1 e k2.
Il terzo e il quarto passo consistono nel dividere i punteggi per 8 (la radice quadrata della dimensione dei vettori chiave utilizzati nel documento – 64). Questo porta ad avere gradienti più stabili. Potrebbero esserci altri valori possibili, ma questo è il valore predefinito), quindi passare il risultato attraverso un’operazione di softmax. Softmax normalizza i punteggi in modo che siano tutti positivi e sommino a 1.
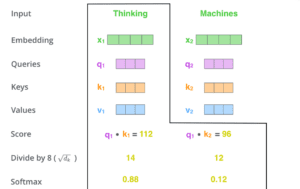
Questo punteggio softmax determina quanto ogni parola sarà espressa in questa posizione. Chiaramente la parola in questa posizione avrà il punteggio softmax più alto, ma a volte è utile prestare attenzione a un’altra parola che sia rilevante per la parola corrente.
Il quinto passo consiste nel moltiplicare ogni vettore di valori per il punteggio softmax (in preparazione alla somma). L’intuizione è quella di mantenere intatti i valori delle parole su cui vogliamo concentrarci e di eliminare le parole irrilevanti (moltiplicandole per numeri piccoli come 0,001, per esempio).
Il sesto passo consiste nel sommare i vettori di valori ponderati. Questo produce l’output dello strato di autoattenzione in questa posizione (per la prima parola).
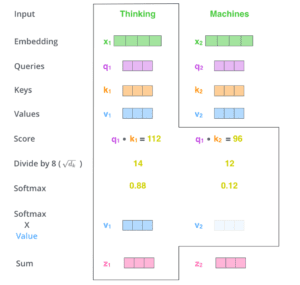
Questo conclude il calcolo dell’autoattenzione. Il vettore risultante può essere inviato alla rete neurale feed-forward. Nell’implementazione reale, tuttavia, questo calcolo viene eseguito in forma di matrice per un’elaborazione più rapida. Vediamo quindi come funziona, dopo aver visto l’intuizione del calcolo a livello di parola.
Attenzione a più teste
I trasformatori funzionano fondamentalmente così. Ci sono alcuni altri dettagli che li fanno funzionare meglio. Per esempio, invece di prestare attenzione all’altro in una sola dimensione, i trasformatori utilizzano il concetto di attenzione multitesta.
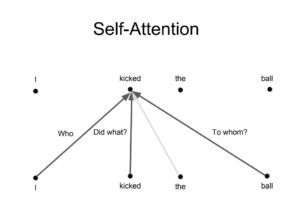
L’idea alla base è che ogni volta che si traduce una parola, si può prestare un’attenzione diversa a ciascuna parola in base al tipo di domanda che si sta ponendo. Le immagini seguenti mostrano cosa significa. Ad esempio, quando si traduce “kicked” nella frase “I kicked the ball”, si può chiedere “Who kicked”. A seconda della risposta, la traduzione della parola in un’altra lingua può cambiare. Oppure si possono fare altre domande, come “Ha fatto cosa?”, ecc.
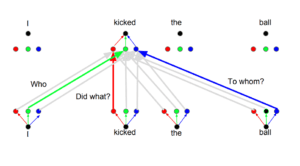
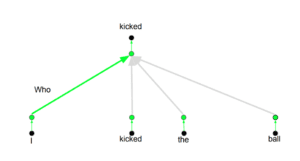
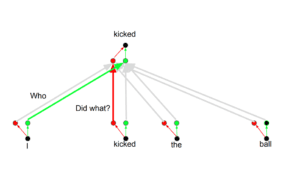
Codifica posizionale
Un altro passo importante del Trasformatore è l’aggiunta della codifica posizionale nella codifica di ogni parola. La codifica della posizione di ogni parola è importante, poiché la posizione di ogni parola è rilevante per la traduzione.
Panoramica
Ho fornito una panoramica su come funzionano i trasformatori e sul perché questa è la tecnica utilizzata per la trasduzione delle sequenze. Se volete capire a fondo come funziona il modello e tutte le sue sfumature, vi consiglio i seguenti post, articoli e video che ho utilizzato come base per riassumere la tecnica
- The Unreasonable Effectiveness of Recurrent Neural Networks
- Understanding LSTM Networks
- Visualizing A Neural Machine Translation Model
- The Illustrated Transformer
- The Transformer — Attention is all you need
- The Annotated Transformer
- Attention is all you need attentional neural network models
- Self-Attention For Generative Models
- OpenAI GPT-2: Understanding Language Generation through Visualization
- WaveNet: A Generative Model for Raw Audio