“MLOps (un composto di Machine Learning e “information technology OPerationS”) è [una] nuova disciplina/focus/pratica per la collaborazione e la comunicazione tra gli scienziati dei dati e i professionisti dell’information technology (IT) durante l’automazione e la produzione di algoritmi di apprendimento automatico”. – Nisha Talagala (2018)

La comprensione del ciclo di vita dell’apprendimento automatico è in continua evoluzione. Quando anni fa ho visto per la prima volta dei grafici che illustravano questo “ciclo”, l’enfasi era posta sui soliti sospetti (preparazione e pulizia dei dati, EDA, modellazione ecc…). Si dava meno importanza allo stato finale, più sfuggente e meno tangibile, spesso definito “deployment”, “delivery” o in alcuni casi semplicemente “prediction”.
All’epoca, non credo che molti data scientist emergenti considerassero davvero la portata di quest’ultimo termine (io di sicuro non lo facevo). “Previsione” non significava solo .predict(), ma implicava una vera e propria scala, un’implementazione a livello di produzione, il monitoraggio e l’aggiornamento – un vero e proprio ciclo. Senza le competenze ingegneristiche necessarie per trasformare questo vago concetto in realtà, il data scientist era bloccato nel notebook. I modelli vivevano come file .pickle sulla macchina locale del data scientist, le prestazioni venivano riportate con Powerpoint e il ciclo di vita del ML era interrotto.
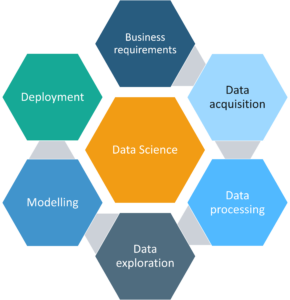
Sebbene il ciclo di vita end-to-end del ML sia sempre stato presentato come un vero e proprio “ciclo”, ad oggi il successo nella gestione di questo processo end-to-end a livello aziendale è stato limitato per i seguenti motivi:
– I data scientist non sono spesso ingegneri formati e quindi non sempre seguono le buone pratiche DevOps.
– Gli ingegneri dei dati, gli scienziati dei dati e gli ingegneri responsabili della consegna operano in silos, creando attriti tra i team.
– La miriade di strumenti e framework per l’apprendimento automatico favorisce la mancanza di standardizzazione nel settore.
– Non esiste ancora un’unica soluzione gestita che soddisfi le esigenze degli ingegneri e dei data scientist senza essere in qualche modo limitante (abbonamento a un linguaggio, a un framework, a un fornitore specifico, ecc.)
– In generale, l’apprendimento automatico aziendale in produzione è ancora immaturo.
Sono sicuro che ci sono altre ragioni e molte sotto-ragioni che contribuiscono a questo aspetto, ma questi problemi di alto livello portano a risultati spiacevoli. L’apprendimento automatico in azienda è lento, difficile da scalare, non è molto automatizzato, la collaborazione è difficile e i modelli operativi che forniscono valore al business sono pochi.

Per questo motivo, abbiamo bisogno di buone “MLOps” – pratiche operative di machine learning volte a standardizzare e semplificare il ciclo di vita del machine learning in produzione. Prima di addentrarmi nel panorama o in altre definizioni, però, vorrei parlare un po’ di più del perché abbiamo bisogno di MLOps migliori.
L’apprendimento automatico è in qualche modo maturo, ma le pratiche di implementazione e l’impatto sul business non lo sono.
In ambito accademico, l’apprendimento automatico ha fatto passi da gigante. Gli algoritmi stanno dimostrando grandi miglioramenti rispetto al lavoro precedente in compiti difficili come l’NLP (anche se si tratta solo di Google che sta gettando più dati e calcoli) e si dice che il numero di articoli sull’apprendimento automatico su arXiv raddoppi ogni 18 mesi.
Questo entusiasmo rende facile perdere la concentrazione sui risultati, ovvero sull’impatto tangibile. Questo sondaggio Databricks del 2018 ha mostrato che, sebbene la maggior parte delle aziende stia adottando o investendo nell’IA, esse citano universalmente la difficoltà delle loro soluzioni, con progetti di “IA” che richiedono in media 6 mesi per essere completati.

Se non si sta attenti, si può finire con i data scientist che inviano letteralmente via e-mail notebook e modelli Python agli ingegneri per la distribuzione in produzione e la riscrittura del codice. Forse questo codice Python scarsamente documentato è troppo inefficiente o incompleto per Docker, ma richiederà anche molto tempo per essere tradotto in Java. Senza una documentazione esauriente, l’ingegnere non ha idea di cosa ci sia in quel file .pickle, non c’è controllo di versione per il modello, le metriche e i parametri, e tutti sono confusi e arrabbiati perché ora sono bloccati in riunioni dolorose per cercare di allinearsi su qualcosa che dovrebbe richiedere giorni invece di mesi.
Non solo, ma una volta che la soluzione è in produzione non esiste un sistema di feedback intrinseco per il miglioramento e gli aggiornamenti. Per alcuni sistemi, è probabile che le prestazioni del modello soffrano nel tempo e il monitoraggio non è sempre una pratica standard. Inoltre, i data scientist non sono addestrati a scrivere casi di test validi, quindi non mi stupirei se gli aggiornamenti dei modelli che passano da Jupyter alla produzione occasionalmente rompessero le applicazioni o fornissero previsioni errate.
Definirei le MLOps nella loro forma più pura come la vera istanziazione del ciclo di vita automatizzato della produzione di ML. Il primo paragrafo della pagina di Wikipedia dedicata alle MLOps dice tutto. MLOps è la logica reazione alle attuali difficoltà che le imprese incontrano nel mettere in produzione l’apprendimento automatico. Nell’ingegneria del software abbiamo DevOps, quindi perché non MLOps? Un buon DevOps garantisce che il ciclo di vita dello sviluppo del software sia efficiente, ben documentato e facile da risolvere. È ora di sviluppare una serie di standard simili per l’apprendimento automatico.
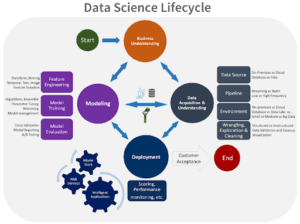
L’industria ha iniziato a raggiungere il suo punto di rottura e la tecnologia si sta evolvendo rapidamente per soddisfare la domanda e modificare lo standard attuale per il ML in produzione. Framework open source come mlflow e kubeflow competono per diventare lo standard del panorama open-source, mentre le nuove startup applicano le UI a queste soluzioni nel tentativo di portare sul mercato prodotti MLOps “proprietari”.
Naturalmente, gli MLOps sono ancora in fase embrionale (almeno nella pratica). Una ricerca di “MLOps” su Towards Data Science produce appena 2 risultati (al momento in cui scriviamo). Tecnicamente parlando, una soluzione completamente gestita con strumenti come mlflow o kubeflow richiede ancora una quantità ragionevole di sviluppo e/o di formazione dei dipendenti per essere utilizzata nella pratica.

Ora, noterete che non ho fornito un elenco preciso di principi MLOps, perché non sono sicuro che esista ancora un insieme universale. Questa idea è ancora in evoluzione e i veri principi si formeranno con l’avvento di nuovi framework e lezioni reali. È importante notare che, come DevOps, MLOps può essere buono o cattivo, e col tempo la linea di demarcazione tra i due diventerà più chiara.
Per ora, ritengo che sia meglio seguire le buone pratiche DevOps. Naturalmente esistono strumenti che facilitano il lavoro, ma da un punto di vista indipendente dal framework, immagino che un buon MLOps sia molto simile a un buon DevOps. Gli obiettivi di MLOps rimangono chiari e un buon MLOps dovrebbe realizzarli nel modo più efficiente possibile:
– Ridurre i tempi e le difficoltà per portare i modelli in produzione.
– ridurre l’attrito tra i team e migliorare la collaborazione
– Migliorare la tracciabilità, il versioning, il monitoraggio e la gestione dei modelli.
– Creare un ciclo di vita veramente ciclico per il modello di ML moderno.
– Standardizzare il processo di apprendimento automatico per prepararsi a normative e politiche sempre più stringenti.
Sono certo che, a seconda della vostra posizione nel settore, potrete essere d’accordo o meno con quanto ho ipotizzato sul panorama. Questi punti di vista sono il risultato della mia limitata esperienza e come tali sono soggetti a idee sbagliate. Come disse Obi-Wan ad Anakin: “Solo un Sith si occupa di assoluti”, e credo che questo sia vero nella mia analisi soggettiva di tutte le cose.

Tuttavia, lo scopo di questo articolo era quello di introdurre MLOps come concetto e forse come una delle prossime grandi rivoluzioni del ML aziendale, e spero di essere stato utile a questo scopo. Sentitevi liberi di connettervi con me su LinkedIn, o di lasciare commenti inutilmente sprezzanti qui sotto. ✌️
Articolo originale di Kyle Gallatin
