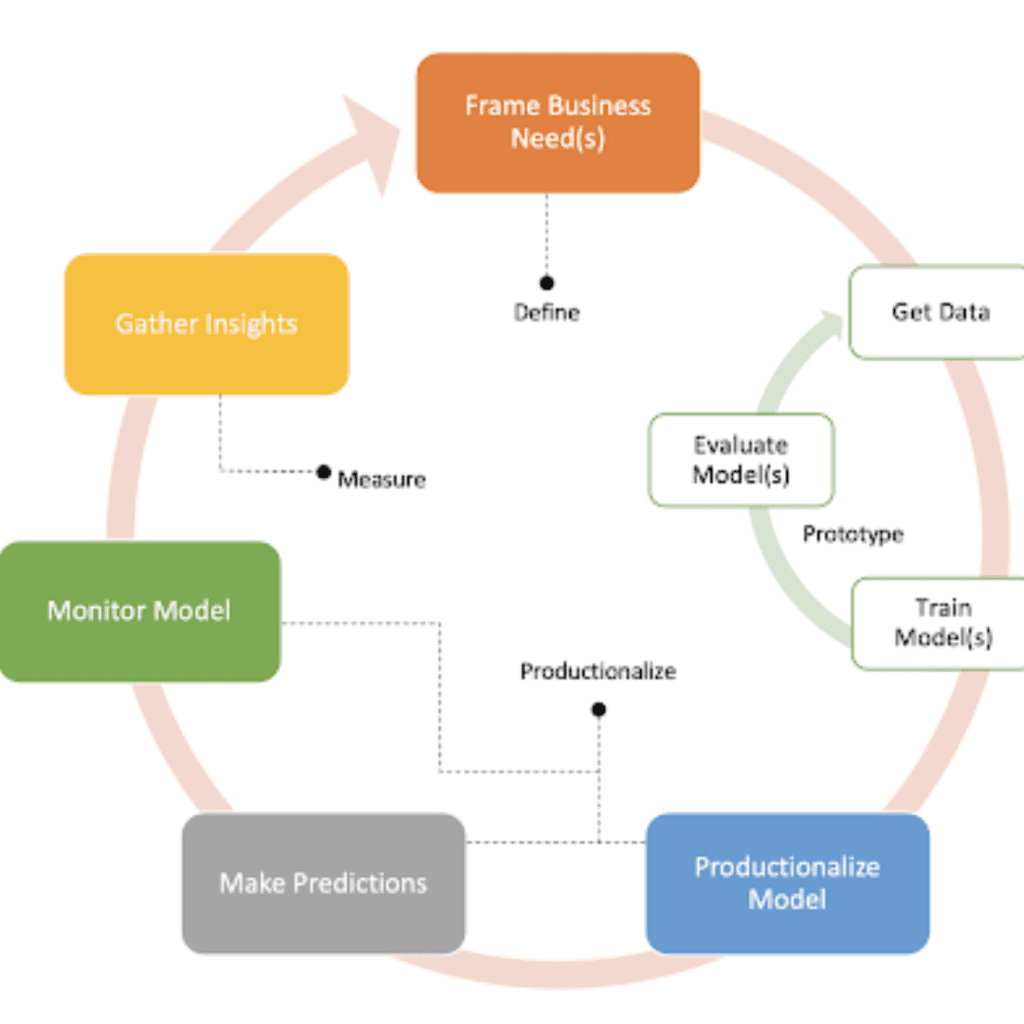
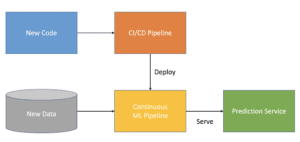
Un tipico ciclo di vita di un progetto di ML può essere riassunto con il seguente diagramma, composto principalmente da 3 fasi.
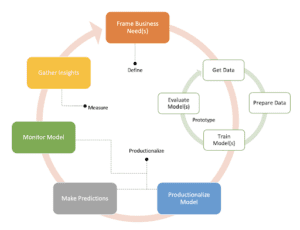
Nella prima fase, e prima di immergersi nei dati, è importante prepararsi al successo. Pertanto, insieme agli esperti di business, dobbiamo definire attentamente il nostro problema e gli obiettivi aziendali! Dobbiamo rispondere ad alcune domande importanti che ci permettono di prendere decisioni di formazione e di servizio per quanto riguarda la progettazione del modello e la pipeline di produzione. Ad esempio:
– Qual è il risultato ideale?
– Qual è la nostra metrica di valutazione? Come possiamo definire il ROI?
– Quali sono i criteri di successo e di fallimento?
– Quali sono i requisiti di latenza? E possiamo ottenere ogni caratteristica per servire entro i requisiti di latenza? …
Nella seconda fase, prototipiamo il nostro primo modello di ML o, in altre parole, eseguiamo uno studio di fattibilità del ML.
Quindi, dimostriamo il valore commerciale del ML utilizzando le metriche definite nella prima fase. Ricordiamo che la regola numero 1 delle best practice per l’ingegneria del ML è “mantenere il primo modello semplice e ottenere l’infrastruttura giusta”. Il primo modello fornisce la spinta maggiore al nostro prodotto, quindi non è necessario che sia il modello più sofisticato all’inizio.
Nella terza fase si passa alla produzione. Questo è l’argomento principale di questo articolo, quindi lo vedremo più in dettaglio nelle prossime sezioni. Una volta che la nostra pipeline di produzione è pronta e ben progettata, possiamo raccogliere intuizioni e iterare nuove idee in modo molto più rapido ed efficiente.
Oggi la maggior parte dei percorsi di ML per portare un modello di apprendimento automatico in produzione assomiglia a questo. Come data scientist, si inizia con un caso d’uso di ML e un obiettivo di business. Con il caso d’uso a portata di mano, iniziamo a raccogliere ed esplorare i dati che ci sembrano rilevanti da diverse fonti di dati per capirne e valutarne la qualità.
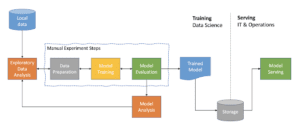
Una volta che abbiamo un’idea dei nostri dati, iniziamo a creare e progettare alcune caratteristiche che riteniamo interessanti per il nostro problema. Quindi entriamo nella fase di modellazione e iniziamo ad affrontare alcuni esperimenti. In questa fase, eseguiamo manualmente e regolarmente le diverse fasi sperimentali. Per ciascun esperimento, eseguiamo la preparazione dei dati, l’ingegnerizzazione delle caratteristiche e i test. In seguito, eseguiamo l’addestramento dei modelli e la regolazione degli iperparametri su tutti i modelli o le architetture di modelli che riteniamo particolarmente promettenti.
Infine, ma non meno importante, valutiamo tutti i modelli generati, li testiamo con un set di dati di riserva, valutiamo le diverse metriche, osserviamo le prestazioni e confrontiamo i modelli tra loro per vedere quale funziona meglio o quale produce la metrica di valutazione più alta. L’intero processo è iterativo e viene eseguito manualmente più e più volte finché non si ottiene il modello più bello con le migliori prestazioni possibili.
Una volta ottenuto il modello con le migliori prestazioni, di solito lo mettiamo in uno spazio di archiviazione e lo lanciamo al di là del muro al team IT e operativo, il cui compito è quello di distribuire il modello in produzione come servizio di predizione. E noi, purtroppo, consideriamo il nostro lavoro concluso.
Ecco cosa c’è di sbagliato nell’approccio sopra descritto.
Manuale: I passaggi sono altamente manuali e vengono scritti da zero ogni volta. Ogni volta che lo scienziato dei dati deve condurre un nuovo esperimento, deve esaminare i suoi quaderni, aggiornarli ed eseguirli manualmente. Se il modello deve essere aggiornato con nuovi dati di addestramento, il data scientist deve eseguire nuovamente il codice manualmente.
Richiede tempo: Questo processo manuale richiede molto tempo e non è efficiente.
Non è riutilizzabile: Il codice personalizzato scritto nei notebook può essere compreso solo dall’autore stesso e non può essere riutilizzato o sfruttato da altri data scientist o in altri casi d’uso. Anche gli stessi autori potrebbero avere difficoltà a comprendere il loro lavoro dopo un certo periodo di tempo.
Irriproducibilità: La riproducibilità è la capacità di essere ricreati o copiati. Nell’apprendimento automatico, è importante poter riprodurre il modello esatto. In un processo manuale come questo, è probabile che non si riesca a riprodurre una versione precedente di un modello, poiché i dati sottostanti potrebbero essere cambiati, il codice stesso potrebbe essere stato sovrascritto o le dipendenze e le loro versioni esatte potrebbero non essere state registrate. Pertanto, in caso di problemi, qualsiasi tentativo di tornare a una versione precedente di un modello potrebbe essere impossibile.
Rischio di errori: Questo processo può portare a molti errori, come la distorsione dell’addestramento, il decadimento delle prestazioni del modello, la distorsione del modello, il crash dell’infrastruttura nel tempo…
– Skew del servizio di formazione: Quando distribuiamo il nostro modello, a volte notiamo che le prestazioni online del nostro modello sono completamente inferiori a quelle previste e misurate sul dataset di attesa. Questo fenomeno è molto frequente per i modelli di apprendimento automatico gestiti. Le discrepanze tra le pipeline di addestramento e di servizio possono introdurre uno skew di servizio di addestramento. Lo skew di addestramento può essere molto difficile da rilevare e può rendere completamente inutili le previsioni di un modello. Per evitare questo problema, dobbiamo assicurarci che le funzioni di elaborazione siano eseguite esattamente su entrambi i dati di addestramento e di servizio, monitorare la distribuzione dei dati di addestramento e di servizio e monitorare le prestazioni in tempo reale del modello e confrontarle con le prestazioni offline.
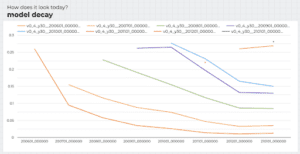
– Decadimento del modello: Nella maggior parte dei casi d’uso, i profili dei dati sono dinamici e cambiano nel tempo. Quando i dati sottostanti cambiano, le prestazioni del modello decadono, poiché i modelli esistenti non sono più aggiornati. I modelli statici raramente continuano ad avere un valore. Dobbiamo assicurarci che i modelli siano aggiornati regolarmente con nuovi dati e monitorare le prestazioni in tempo reale dei modelli serviti per innescare i decadimenti dei modelli. La figura seguente mostra come un modello distribuito decade nel tempo e la necessità costante di aggiornare il modello con uno nuovo.
– Pregiudizio del modello: le applicazioni dei sistemi di IA possono avere una natura critica, come la diagnosi o la prognosi medica, l’abbinamento delle competenze di una persona con un lavoro o la verifica dell’idoneità di una persona per un prestito. Per quanto queste applicazioni possano sembrare pratiche, l’impatto di eventuali distorsioni in questi sistemi può essere ampiamente dannoso. Pertanto, una proprietà importante dei futuri sistemi di IA è l’equità e l’inclusione per tutti. Pertanto, per qualsiasi modello di apprendimento automatico, è importante misurare l’equità tra le caratteristiche sensibili (genere, razza…). Le caratteristiche sensibili dipendono dal contesto. Anche per le caratteristiche non sensibili, è importante valutare le prestazioni dei sistemi di IA sui diversi sottogruppi per assicurarsi di essere consapevoli di eventuali sottogruppi poco performanti prima che il modello venga distribuito.
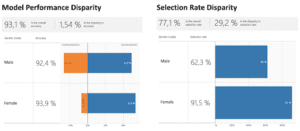
– Scalabilità: La scalabilità è importante nell’apprendimento automatico perché l’addestramento di un modello può richiedere molto tempo e quindi l’ottimizzazione di un modello che richiede diverse settimane di addestramento non è fattibile. Un modello può essere così grande da non poter essere inserito nella memoria di lavoro del dispositivo di addestramento. Anche se decidiamo di scalare verticalmente, sarà più costoso che scalare orizzontalmente. Ci possono essere casi in cui la quantità di dati non è elevata e quindi la scalabilità potrebbe non essere necessaria all’inizio, ma dobbiamo pensare se, con l’addestramento continuo, la quantità di dati di addestramento che ci aspettiamo di ricevere aumenterà nel tempo e potrebbe introdurre un problema di memoria per l’infrastruttura che abbiamo impostato.
In questa sezione descriveremo i principali componenti di un sistema di ML e le best practice che li riguardano e che ci permetteranno di evitare le insidie di cui sopra.
Il processo di realizzazione di un sistema di ML integrato e di funzionamento continuo in produzione prevede le seguenti fasi:
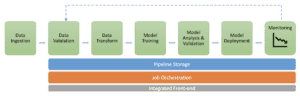
Parliamo un po’ in dettaglio di ciascuno dei componenti della pipeline.
Ingestione dei dati:
Questo componente è solitamente esterno e non rientra nella pipeline ML del nostro caso d’uso. Nei processi di dati maturi, gli ingegneri dei dati dovrebbero ottimizzare l’ingestione e la trasformazione continua dei dati per fornire continuamente dati aggiornati alle diverse entità di analisi dei dati all’interno dell’organizzazione, che non vedono l’ora di scoprire intuizioni basate sui dati e decisioni più informate.
Convalida dei dati:
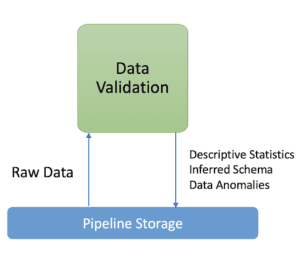
In questo componente, l’attenzione si concentra sulla convalida dei dati in ingresso alla nostra pipeline. Non si può sottovalutare l’importanza di questo problema nei sistemi di ML. Indipendentemente dagli algoritmi di ML impiegati, gli errori nei dati possono influire pesantemente sulla qualità del modello generato. Come dice un concetto popolare della scienza dei dati, “garbage in, garbage out”. Pertanto, è fondamentale individuare tempestivamente gli errori nei dati.
Un altro ruolo che i dati privi di errori possono svolgere è in termini di analisi dei risultati del modello. Questa componente ci permette di comprendere e debuggare correttamente l’output del nostro modello ML. Di conseguenza, i dati devono essere considerati cittadini di prima classe nei sistemi di ML, proprio come gli algoritmi e l’infrastruttura. Devono essere continuamente monitorati e validati a ogni esecuzione della pipeline di ML.
Questa fase viene utilizzata anche prima dell’addestramento del modello per decidere se riqualificare il modello (in caso di deriva dei dati) o interrompere l’esecuzione della pipeline (in caso di anomalie dei dati).
Ecco come dovrebbe essere il comportamento tipico del componente di validazione dei dati:
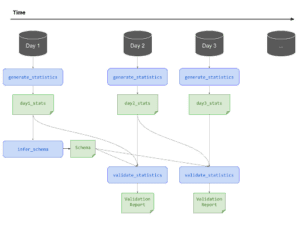
– Calcola e visualizza le statistiche descrittive dei dati; può anche visualizzare le statistiche descrittive di intervalli consecutivi di dati (ad esempio, tra l’attuale esecuzione della pipeline N e l’ultima esecuzione della pipeline N-1) per vedere come è cambiata la distribuzione dei dati.


– Rileva le anomalie dei dati. Deve verificare se il set di dati corrisponde allo schema predefinito e validato. Deve rilevare la deriva dei dati tra intervalli consecutivi di dati (cioè tra l’esecuzione corrente della pipeline N e l’ultima esecuzione della pipeline N-1), ad esempio tra diversi giorni di dati di addestramento. Dovrebbe inoltre rilevare lo skew del servizio di addestramento confrontando i dati di addestramento con i dati di servizio online.
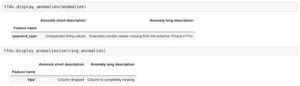
In produzione, con una formazione continua, ecco come appare una vista schematica che genera statistiche sui nuovi dati in arrivo, li convalida e genera rapporti sulle anomalie:
Trasformazione dei dati
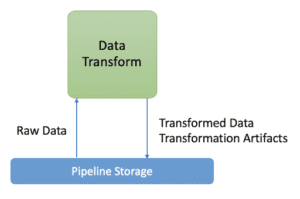
In questa fase, i dati vengono preparati per l’attività di ML. Ciò comporta la pulizia dei dati, il filtraggio, le trasformazioni dei dati e la gestione delle caratteristiche. Dovrebbe fare cose come generare mappature tra caratteristiche e numeri interi. Inoltre, questo componente prepara i metadati delle caratteristiche che potrebbero essere necessari nel componente di addestramento (ad esempio, i metaparametri necessari nella fase di addestramento per la normalizzazione delle caratteristiche, i dizionari necessari per la codifica delle variabili categoriali, ecc.) Questi sono chiamati artefatti di trasformazione; aiutano a costruire gli input del modello.
È fondamentale che le mappature generate vengano salvate e riutilizzate al momento del servizio (quando il modello addestrato viene utilizzato per fare previsioni). Se non si riesce a farlo in modo coerente, si verifica il problema del Training Serving Skew di cui abbiamo parlato in precedenza.
Modello di formazione
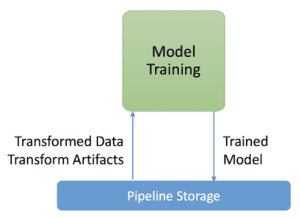
Il componente di addestramento del modello è responsabile dell’addestramento del nostro modello. Nella maggior parte dei casi d’uso, i modelli possono essere addestrati per ore, giorni e persino settimane. Ottimizzare un modello che richiede diverse settimane di addestramento non è fattibile. In altri casi, i dati utilizzati per l’addestramento del modello non sono nemmeno memorizzabili.
In questo scenario, il componente di addestramento del modello deve essere in grado di supportare il parallelismo dei dati e del modello e di scalare su un numero elevato di lavoratori. Dovrebbe anche essere in grado di gestire i dati fuori memoria.
Idealmente, tutti i componenti del nostro sistema di ML dovrebbero essere scalabili e funzionare su un’infrastruttura che supporti la scalabilità.
Questo componente di addestramento del modello dovrebbe anche essere in grado di monitorare automaticamente e registrare tutto durante l’addestramento. Non possiamo addestrare un modello di apprendimento automatico per un lungo periodo di tempo senza vedere come si sta comportando e assicurarci che sia configurato correttamente per minimizzare la funzione di perdita con il numero di iterazioni. Infine, il componente di addestramento dovrebbe anche supportare la regolazione degli iperparametri.
Analisi del modello
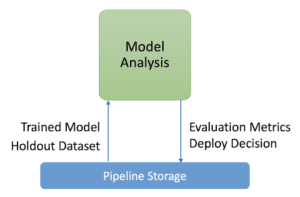
Nella componente di analisi del modello, conduciamo un’analisi approfondita dei risultati dell’addestramento e ci assicuriamo che i modelli esportati siano sufficientemente performanti per essere messi in produzione.
Questa fase ci aiuta a garantire che il modello venga promosso per la produzione solo se soddisfa i criteri di qualità prestabiliti durante la fase di definizione. I criteri devono includere il miglioramento delle prestazioni rispetto ai modelli distribuiti in precedenza e l’equità delle prestazioni sui vari sottoinsiemi/fette di dati. Nella figura seguente, mostriamo le prestazioni del nostro modello addestrato sulla feature slice trip_start_hour.

Il risultato di questa fase è una serie di metriche di prestazione e una decisione sull’opportunità di promuovere il modello alla produzione.
Servizio del modello
A differenza della componente di addestramento, dove di solito ci preoccupiamo di scalare con i dati e la complessità del modello. Nel componente di servizio, siamo interessati a rispondere alla domanda variabile degli utenti minimizzando la latenza di risposta e massimizzando il throughput.
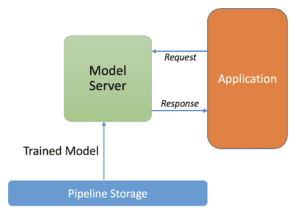
Pertanto, il componente di servizio deve avere una bassa latenza per rispondere rapidamente agli utenti, un’elevata efficienza in modo che molte istanze possano essere eseguite simultaneamente se necessario, scalare orizzontalmente, essere affidabile e robusto ai guasti.
Abbiamo anche bisogno che il nostro componente di servizio sia facilmente in grado di aggiornarsi alle nuove versioni del modello. Quando riceviamo nuovi dati, attiviamo una nuova pipeline o testiamo nuove idee per l’architettura del modello, vogliamo inviare una nuova versione del modello e vogliamo che il sistema passi senza problemi a questa nuova versione.
Monitoraggio
Come abbiamo accennato in precedenza, le prestazioni dei nostri modelli ML distribuiti possono decadere nel tempo a causa dell’evoluzione costante dei profili dei dati e dobbiamo assicurarci che il nostro sistema stia monitorando e rispondendo a questo degrado.
Pertanto, dobbiamo tenere traccia delle statistiche riassuntive dei nostri dati e monitorare le prestazioni online del nostro modello per inviare notifiche, fare un rollback quando i valori si discostano dalle nostre aspettative o potenzialmente invocare una nuova iterazione nel processo di ML.
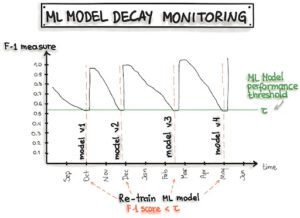
Pertanto, il monitoraggio online è fondamentale per rilevare il degrado delle prestazioni e lo stallo del modello. Funge da spunto per una nuova iterazione di sperimentazione e per la riqualificazione del modello su nuovi dati.
Il livello di automazione delle fasi appena descritte definisce la maturità del nostro sistema di ML, e riflette anche la velocità di formazione di nuovi modelli innescata dal decadimento del modello o da nuovi dati.
Un processo manuale è attualmente molto comune in molti casi d’uso. Potrebbe essere sufficiente quando i modelli vengono cambiati raramente a causa della distribuzione statica dei dati. Ma nella pratica, questo è raramente il caso. I dati sono spesso dinamici e i modelli si rompono spesso quando vengono distribuiti nel mondo reale. I modelli statici non riusciranno sicuramente ad adattarsi ai cambiamenti dei dati che descrivono l’ambiente.
Un processo manuale può anche essere pericoloso, in quanto crea una disconnessione tra la formazione e il servizio di ML. Separa i data scientist che creano il modello e gli ingegneri che lo gestiscono come servizio di predizione. Questo processo può portare al problema della distorsione del servizio di formazione.
L’obiettivo del componente di orchestrazione è quello di collegare i diversi componenti del sistema. Esegue la pipeline in sequenza e passa automaticamente da una fase all’altra in base alle condizioni definite. Questo è il primo passo verso l’automazione, in quanto ora possiamo addestrare automaticamente nuovi modelli in produzione utilizzando dati freschi basati su trigger di pipeline in tempo reale.

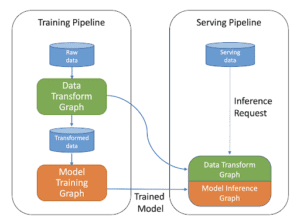
Dobbiamo prestare attenzione al fatto che in produzione non stiamo distribuendo un modello addestrato come servizio di predizione. In realtà stiamo distribuendo un’intera pipeline di addestramento, che viene eseguita automaticamente e ricorrentemente per servire il modello addestrato come servizio di predizione.
Il ruolo dello storage dei metadati della pipeline è quello di registrare tutti i dettagli sulle esecuzioni della pipeline di ML. Questo è molto importante per mantenere la discendenza tra i componenti e riprodurre i modelli distribuiti in qualsiasi momento. Inoltre, ci aiuta a eseguire il debug di qualsiasi errore riscontrato.
Ogni volta che si esegue la pipeline, lo store registra tutti i dettagli sull’esecuzione della pipeline, come ad esempio:
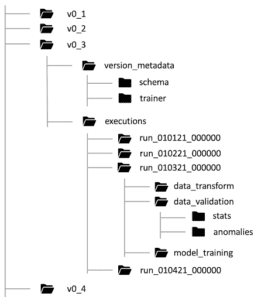
– Le versioni della pipeline e i codici sorgente dei componenti che sono stati eseguiti.
– Gli argomenti di input passati alla nostra pipeline.
– Gli artefatti/output prodotti da ciascun componente eseguito della nostra pipeline, come il percorso dei dati grezzi, i dataset trasformati, le statistiche di validazione e le anomalie, il modello addestrato…
– Le metriche di valutazione del modello e la decisione di convalida del modello in merito alla sua distribuzione, prodotta durante la componente di analisi e convalida del modello…
Finora abbiamo parlato solo di come automatizzare l’esecuzione continua della pipeline di ML per riqualificare nuovi modelli in base a fattori scatenanti come la disponibilità di nuovi dati o il decadimento del modello per catturare nuovi modelli emergenti.
Ma se volessimo testare una nuova funzionalità, una nuova architettura del modello o un nuovo iperparametro? Questo è lo scopo di una pipeline CI/CD automatizzata. Una pipeline CI/CD ci permette di esplorare rapidamente nuove idee e sperimentazioni. Ci permette di costruire, testare e distribuire automaticamente la nuova pipeline e i suoi componenti nell’ambiente previsto.
Ecco come l’automazione della pipeline CI/CD completa l’automazione della pipeline ML continua:
– Se viene fornita una nuova implementazione/codice (nuova architettura del modello, ingegneria delle funzionalità e iperparametri…), una pipeline CI/CD di successo distribuisce una nuova pipeline di ML continua.
– Se vengono forniti nuovi dati (o un trigger di decadimento del modello), una pipeline continua automatizzata di successo distribuisce un nuovo servizio di predizione. Per addestrare un nuovo modello ML con nuovi dati, la pipeline ML precedentemente distribuita viene eseguita sui nuovi dati.
Una pipeline automatizzata completa end-to-end dovrebbe avere questo aspetto:
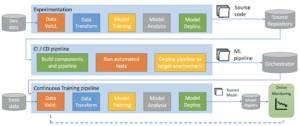
- – Proviamo iterativamente nuove idee di ML in cui alcuni componenti della nostra pipeline vengono aggiornati (l’introduzione di una nuova funzionalità, ad esempio, ci porterà ad aggiornare il componente di trasformazione dei dati…). L’output di questa fase è il codice sorgente dei nuovi componenti della pipeline ML, che viene poi inviato a un repository sorgente dell’ambiente di destinazione.
- – La presenza di un nuovo codice sorgente innesca la pipeline CI/CD che, a sua volta, costruisce i nuovi componenti e la pipeline, esegue i test unitari e di integrazione corrispondenti per assicurarsi che tutto sia codificato e configurato correttamente e, infine, distribuisce la nuova pipeline nell’ambiente di destinazione se tutti i test sono stati superati. I test unitari e di integrazione per i sistemi ML meritano un articolo a sé stante.
- – La nuova pipeline distribuita viene eseguita automaticamente in produzione in base a una pianificazione, alla presenza di nuovi dati di addestramento o in risposta a un trigger. L’output di questa fase è un modello addestrato che viene inviato al registro dei modelli e monitorato continuamente.
- Perché Tensorflow?
- In questa sezione finale, vorrei spiegare perché Tensorflow è il mio framework preferito per sviluppare un sistema di ML integrato. Naturalmente, TensorFlow potrebbe non essere adatto a tutti i casi d’uso, e a volte potrebbe essere addirittura eccessivo, soprattutto quando il deep learning non è necessario. Tuttavia, tendo a usare Tensorflow quando è possibile per i seguenti motivi:
- – Tensorflow viene fornito con Tensorflow Extended (TFX). TFX ci permette di concentrarci sull’ottimizzazione della nostra pipeline di ML, prestando meno attenzione al codice boilerplate che si ripete ogni volta. Componenti come la convalida dei dati e l’analisi del modello possono essere eseguiti facilmente senza dover sviluppare codici personalizzati che leggano i dati e rilevino le anomalie tra due esecuzioni della pipeline. Con TFX, tutto ciò può essere fatto con pochissime righe di codice, risparmiando così un’enorme quantità di tempo nello sviluppo dei componenti della pipeline. Le schermate dei componenti di validazione dei dati e di analisi del modello sono state prese da TFX. Cercherò di dedicare un articolo a TFX in futuro.
- – Possiamo progettare modelli personalizzati che costruiremmo a partire da livelli utilizzando le API TF layers, TF losses API, ….. Se stiamo costruendo qualcosa di abbastanza standard, TensorFlow ha una serie di stimatori già pronti che possiamo provare. Tensorflow 2 funziona bene con i modelli Keras.
- – Con l’aumentare dei dati e del tempo di addestramento, le nostre esigenze aumenteranno. I checkpoint ci permettono di mettere in pausa e riprendere l’addestramento quando necessario, e di continuare l’addestramento se il numero di epoche prestabilito è insufficiente.
- – Tensorflow è stato progettato con un’API per i set di dati che gestisce molto bene i set di dati fuori memoria.
- – L’addestramento del modello può richiedere ore, a volte giorni. Non possiamo addestrare il nostro modello per un lungo periodo di tempo senza verificare se funziona come previsto. Tensorboard è il toolkit di visualizzazione di TensorFlow. TensorBoard fornisce la visualizzazione e gli strumenti necessari per la sperimentazione dell’apprendimento automatico. Ci permette di visualizzare le metriche chiave di TensorFlow generate in tempo reale durante l’addestramento e di visualizzarle su entrambi gli insiemi di addestramento e di validazione per vedere se il nostro modello è configurato correttamente per convergere. Questo ci permetterà di interrompere l’addestramento se non è così.
- Possiamo distribuire TensorFlow su un cluster per renderlo più veloce. Passare da una macchina a molte potrebbe sembrare complicato, ma con Tensorflow la distribuzione è immediata. TF astrae i dettagli dell’esecuzione distribuita per l’addestramento e la valutazione, supportando al contempo un comportamento coerente tra le configurazioni locali/non distribuite e distribuite.
Articolo originale di Maggie Mhanna
https://medium.com/towards-data-science/mlops-practices-for-data-scientists-dbb01be45dd8