Secondo la documentazione di Google
👉🏻 MLOps è una metodologia per l’ingegneria ML che unifica lo sviluppo del sistema ML (l’elemento ML) con le operazioni del sistema ML (l’elemento Ops). Sostiene la formalizzazione e (quando è vantaggioso) l’automazione delle fasi critiche della costruzione di un sistema di ML. MLOps fornisce un insieme di processi e funzionalità tecnologiche standardizzate per costruire, distribuire e rendere operativi i sistemi di ML in modo rapido e affidabile.
MLOps supporta lo sviluppo e la distribuzione di sistemi di ML nello stesso modo in cui DevOps e DataOps supportano l’ingegneria delle applicazioni e dei dati (analytics). La differenza è che quando si distribuisce un servizio web, ci si preoccupa della resilienza, delle query al secondo, del bilanciamento del carico e così via. Quando si distribuisce un modello di ML, ci si deve preoccupare anche delle modifiche ai dati, delle modifiche al modello, degli utenti che cercano di aggirare il sistema e così via. È di questo che si occupa MLOps.
1. Informazioni sul set di dati:
Questo dataset è stato inizialmente pubblicato da analyticsvidhya.com e disponibile anche su Kaggle.
Questo dataset contiene circa 25k immagini di dimensioni 150×150 distribuite in 6 categorie.
{‘edifici’ -> 0,
‘foresta’ -> 1,
‘ghiacciaio’ -> 2,
‘montagna’ -> 3,
‘mare’ -> 4,
‘strada’ -> 5 }
I dati di Train, Test e Prediction sono separati in ogni file zip. Ci sono circa 14k immagini in Train, 3k in Test e 7k in Prediction.
2. Fasi di sviluppo del modello

Non entrerò nel dettaglio dello sviluppo del modello. Per questo problema di classificazione delle immagini sto usando TensorFlow. L’obiettivo è costruire il modello e automatizzare il processo di distribuzione.
– Dati non strutturati
– Classificazione di immagini -Multiclasse
– Utilizzare la libreria TensorFlow
– Caricare il dataset in un dataframe.
– Esplorare il set di dati.
– Preparare i dati.
– Aumento dei dati – Utilizzo di ImageDataGenerator
– Classificatore CNN
– Classificazione multiclasse -softmax
– perdita-categoria_crossentropia
– Ottimizzatore -Adam
Ricordarsi di scaricare il modello e di testarlo nuovamente caricandolo.
model.save(‘/content/drive/MyDrive/Files/image_intel/models/’, save_format=’tf’)
e caricare
model_loaded = tf.keras.models.load_model(‘/content/drive/MyDrive/Files/image_intel/models/models/’)
– Salva: tf.saved_model.save(model, path_to_dir)
– Carica: model = tf.saved_model.load(path_to_dir)
La cartella dei modelli salvati avrà l’aspetto di
3. Distribuzione del modello e fasi CICD
Di seguito sono riportati i passi da seguire per distribuire il modello in GCP.
Che cos’è il CICD?
Secondo la documentazione di Google
L’integrazione continua (CI) e la consegna continua (CD) consentono ai team di adottare l’automazione nella creazione, nel collaudo e nella distribuzione del software. La documentazione vi guiderà attraverso la fase della pipeline CI/CD per costruire e distribuire un’applicazione su GKE utilizzando Container Registry e Cloud Build.
Verranno eseguiti i seguenti passaggi.
- Github pronto: Creare tutti i file necessari per l’automazione e tenere pronto il repository GitHub.
- Cloudbuild: La compilazione avverrà tramite google cloudbuild.
- Test: Nessun test automatizzato in questa pipeline.
- Distribuzione: Verrà distribuito in GKE con 2 repliche.
Github, Cloudbuild e Deploy in GKE:
I passaggi dettagliati sono
- Creare un file streamlit app -python.
- Creare un file docker.
- Creare il file dei requisiti.
- Creare il file YAML di distribuzione Kubernetes.
- Creare il file YAML del servizio Kubernetes.
- Creare il file YAML di cloudbuild.
- Creare un repository GitHub sul desktop GitHub.
- Caricare e organizzare i file sul desktop Github.
- Spingere i file dal desktop a Github.
- Collegare il cloudbuild a Github e al progetto GCP.
- Creare un trigger in GCP -trigger basato sulle modifiche del codice Github.
- Ora la build viene attivata e l’applicazione viene distribuita sul motore Kubernetes.
Analizziamo in dettaglio i passaggi sopra descritti.
Ora il modello di classificazione delle immagini CNN è stato scaricato ed è pronto per essere distribuito. Stiamo per distribuire il modello nel motore Kubernetes di Google.
Secondo la documentazione di Google Cloud, Google Kubernetes Engine (GKE) fornisce un ambiente gestito per distribuire, gestire e scalare le applicazioni containerizzate utilizzando l’infrastruttura di Google. L’ambiente GKE è costituito da più macchine (in particolare, istanze di Compute Engine) raggruppate per formare un cluster.
Alcuni dei vantaggi dell’utilizzo di Kubernetes sono
– Bilanciamento del carico
– Scalabilità automatica
– Aggiornamenti automatici
– Riparazione automatica dei nodi
– Registrazione e monitoraggio.
Se non si dispone di un account GCP, è possibile crearne uno e utilizzare i 300 dollari di credito gratuito di GCP per i nuovi utenti. I dettagli sono
I nuovi clienti hanno a disposizione 300 dollari di crediti gratuiti per esplorare e valutare a fondo la Google Cloud Platform. Non vi verrà addebitato nulla fino a quando non deciderete di effettuare l’upgrade.
Vediamo tutti i passaggi in dettaglio
Streamlit:
Streamlit è un framework di app open-source per team di Machine Learning e Data Science. Crea bellissime app per i dati in poche ore, non in settimane. Tutto in puro Python.

Docker:
Un Dockerfile è un documento di testo che contiene tutti i comandi che un utente potrebbe chiamare sulla riga di comando per assemblare un’immagine

Abbiamo già creato il file docker e perché abbiamo bisogno di Kubernetes. Secondo la documentazione di Kubernetes noto anche come K8s, è un sistema open-source per automatizzare la distribuzione, il ridimensionamento e la gestione di applicazioni containerizzate.

Kubernetes è un software open-source per la gestione dei container sviluppato sulla piattaforma di Google. Aiuta a gestire un’applicazione containerizzata in vari tipi di ambienti fisici, virtuali e cloud.
Kubernetes semplifica l’implementazione e la configurazione di applicazioni containerizzate complesse e aiuta a risolvere problemi come la scalatura e il bilanciamento del carico. Kubernetes è stato creato originariamente da Google e successivamente donato alla Cloud Native Computing Foundation (CNCF). Oggi è gestito e mantenuto dalla CNCF e gode di un forte sostegno da parte della comunità e degli utenti di tutto il mondo. Google gestisce circa 2,5 miliardi di container utilizzando Kubernetes per eseguire i suoi servizi per gli utenti. Kubernetes è disponibile su diverse piattaforme cloud come Google Kubernetes Engine (GKE) di Google Cloud Platform, AWS EC2 Container Service e Microsoft Azure Container. Lo strumento CLI utilizzato per interagire con l’oggetto Kubernetes è noto come kubectl.
Le alternative a Kubernetes sono
- Amazon ECS
- RedHat OpenShift
- Docker Swarm
- Nomad
- AWS Fargate
Tutti i file di configurazione sono creati in YAML.
Verranno creati 2 file YAML
– File YAML di distribuzione
– File YAML di servizio
Per saperne di più sui file di distribuzione e di servizio, vedere il video
Il file di distribuzione è il seguente
– apiVersion – Quale versione dell’API di Kubernetes si sta utilizzando per creare questo oggetto
– kind – Il tipo di oggetto che si vuole creare
– metadati – Dati che aiutano a identificare in modo univoco l’oggetto, tra cui una stringa di nome, UID e uno spazio dei nomi opzionale
– spec – Quale stato si desidera per l’oggetto
– Il punto importante da notare è che l’immagine del contenitore usata per costruire il pod è image: gcr.io/my-vision-project-283816/myapp:v1. Questa è l’immagine costruita usando il file docker e registrata nel registro GCP.
– La porta del contenitore è 8501.Streamlit utilizza la porta 8501.
– Il deployment crea due Pod replicati, indicati dal campo .spec.replicas. Se si vuole scalare a un numero maggiore, si aumentano le repliche a un numero più alto.
Il file yaml del servizio è riportato di seguito
– Il tipo è Servizio
– Il nome dell’applicazione è imageclassfier. Lo stesso nome usato nel file di distribuzione.
– Questa specifica crea un nuovo oggetto Servizio chiamato “imageclassifier”, che punta alla porta TCP 8501 su qualsiasi Pod con l’etichetta app=iamgeclassfier.
Siamo nelle fasi finali della distribuzione automatica.
Google Cloudbuild:
Secondo la documentazione di Google
Cloud Build è un servizio che esegue le build sull’infrastruttura di Google Cloud Platform. Cloud Build può importare il codice sorgente da Cloud Storage, Cloud Source Repositories, GitHub o Bitbucket, eseguire una build secondo le vostre specifiche e produrre artefatti come container Docker o archivi Java. Per saperne di più
Cloud Build esegue la vostra build come una serie di passi di build, dove ogni passo di build viene eseguito in un contenitore Docker. Un passo di compilazione può fare tutto ciò che può essere fatto da un contenitore, indipendentemente dall’ambiente. Per eseguire le attività, è possibile utilizzare i passi di compilazione supportati forniti da Cloud Build o scrivere i propri passi di compilazione.
Altri prodotti simili a google cloud build sono
– AWS CodePipeline.
– CircleCI.
– Jenkins.
– GitHub.
– Postman.
– GitLab.
– CloudBees CI.
– Servizio Contenitori Elastici di Amazon (Amazon ECS).

È necessario creare un file yaml.
Il file yaml di cloudbuild è riportato di seguito
– Il primo passo è costruire l’immagine docker.
– Assicurarsi di indicare la posizione del registro.
– Il secondo passo è responsabile del push dell’immagine Docker costruita al primo passo nel registro dei container.
– Il terzo passo consiste nel distribuire il pod in Kubernetes. Il nome del file K8s conterrà il file YAML di distribuzione e il file YAML del servizio.
– Indicare anche il nome del cluster Kubernetes creato. Posizione e nome del cluster.
– Si utilizza la variabile ${PROJECT_ID}
Finora abbiamo creato il
– Modello di taccuino jupyter
– File python Streamlit
– File di testo dei requisiti
– file Docker
– file YAML della distribuzione k8s
– File YAML del servizio k8s
– file YAML di Cloudbuild.
Prima di impostare il trigger, è necessario eseguire alcuni passaggi manuali aggiuntivi.
Creare il progetto GCP:
I passi seguenti sono tratti dalla documentazione di Google
– Aprire la Google Cloud Console.
– Accanto a “Google Cloud Platform”, fare clic sulla freccia giù. Viene visualizzata una finestra di dialogo che elenca i progetti correnti.
– Fare clic su Nuovo progetto. Viene visualizzata la schermata Nuovo progetto.
– Nel campo Nome progetto, inserire un nome descrittivo per il progetto. Se si sta eseguendo un avvio rapido, utilizzare “Avvio rapido”.
– Per modificare l’ID progetto, fare clic su Modifica. L’ID del progetto non può essere modificato dopo la creazione del progetto, quindi scegliete un ID che soddisfi le vostre esigenze per tutta la durata del progetto.
– Fare clic su Organizzazione e selezionare l’organizzazione. Nel campo Posizione, fare clic su Sfoglia per visualizzare le posizioni potenziali per il progetto. Fare clic su una località e fare clic su Seleziona. Fare clic su Crea. La console passa alla pagina Dashboard e il progetto viene creato in pochi minuti.
Attivare le API:
In GCP è necessario attivare le seguenti API
– Google Kubernetes Engine
– Google Cloudbuild
– Registro dei contenitori di Google
Creare il cluster di K8:
È necessario creare il cluster Kubernetes in GCP.
Possiamo creare il cluster utilizzando l’interfaccia della riga di commando

– Numero di nodi 1 – cluster di base
Assicurarsi di dare il nome del cluster correttamente nel file YAML di google cloudbuild.
Github Desktop:
– Creare un nuovo repository.
– Organizzare i file
– Inviarlo a GitHub.
Creare il trigger di Cloudbuild:
Siamo all’ultima fase dell’automazione.
- Collegare il repository Github e Cloudbuild: Preparare il codice sorgente in un repository GitHub.
Consultare la documentazione sottostante che contiene i passaggi per collegare il repository GitHub a Cloudbuild.
- Dopo aver collegato cloudbuild e il repository GitHub, creare il trigger. Consultare la documentazione su come creare un trigger.
Il trigger è stato creato ora

Test e impostazione della pipeline CICD:
Il trigger di cloudbuild sarà attivato se facciamo un push al repository. Basta apportare alcune modifiche al file Read e fare il push. Ora si può vedere che l’attivazione di Cloudbuild è stata attivata?
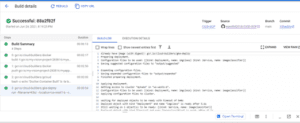
Il completamento richiede circa 5-6 minuti. È possibile controllare il registro. Mostrerà che l’immagine docker del passo 1 è stata creata e poi inviata al registro dei container. Si noti che è possibile vedere l’output per ciascuna delle fasi di creazione definite nel file YAML di cloudbuild.
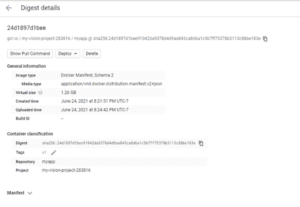
Una volta completata la compilazione, si può vedere lo stato
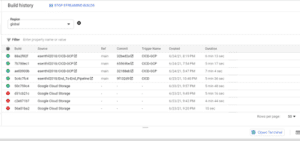
Se non riesce, controllare il log e risolvere il problema. Non ho indicato correttamente il nome della cartella dei file ed è fallito una volta. Una volta ho dato il nome del cluster GKE in modo errato. Quindi, se ci sono errori, controllare il log e correggerli, quindi eseguire di nuovo il trigger.
Dopo il successo della creazione, si può vedere il pod installato. Poiché nel file di distribuzione sono state indicate 2 repliche, si vedono 2 pod creati.
Il punto finale viene creato
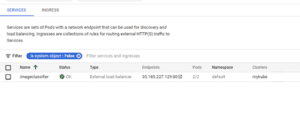
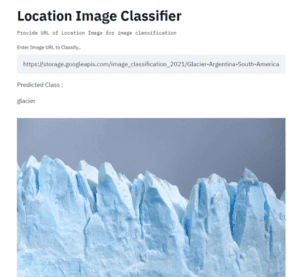
Ora è possibile testare l’applicazione
Pulizia:
Assicuratevi di eliminare le risorse dopo aver terminato il progetto. Eliminare quanto segue
– Pod, servizi ed endpoint creati.
– Cluster Kubernetes
– Immagini del registro dei contenitori
– Secchi di memoria
– Trigger di build nel cloud
Assicuratevi di eliminare tutti gli oggetti creati in modo che non vi vengano addebitati. Cercate di utilizzare il credito di 300 dollari fornito da GCP.