Articolo in lingua originale di Harshvardhan Gupta
Questo articolo assume che ci sia familiarità con le reti neurali.
Questo articolo rappresenta la prima parte, potete trovare la seconda qui.
Le reti neurali profonde sono l’algoritmo di riferimento per la classificazione delle immagini. Ciò è dovuto in parte al fatto che possono avere un numero arbitrariamente elevato di parametri addestrabili. Tuttavia, questo ha il costo di richiedere una grande quantità di dati, che a volte non sono disponibili. In questo articolo parleremo di un metodo di apprendimento, il One Shot Learning, che mira a mitigare questo problema. Nella seconda parte dell’articolo affronteremo, inoltre, come implementare in PyTorch una rete neurale in grado di utilizzare questo metodo di apprendimento.
Questo articolo prende spunto da questo paper.
Le reti siamesi rappresentano un tipo speciale di architettura di reti neurali. Invece che un modello che apprende come classificare gli input che riceve, queste reti neurali imparano a distinguere tra due input, imparano la somiglianza tra di essi.
Architettura
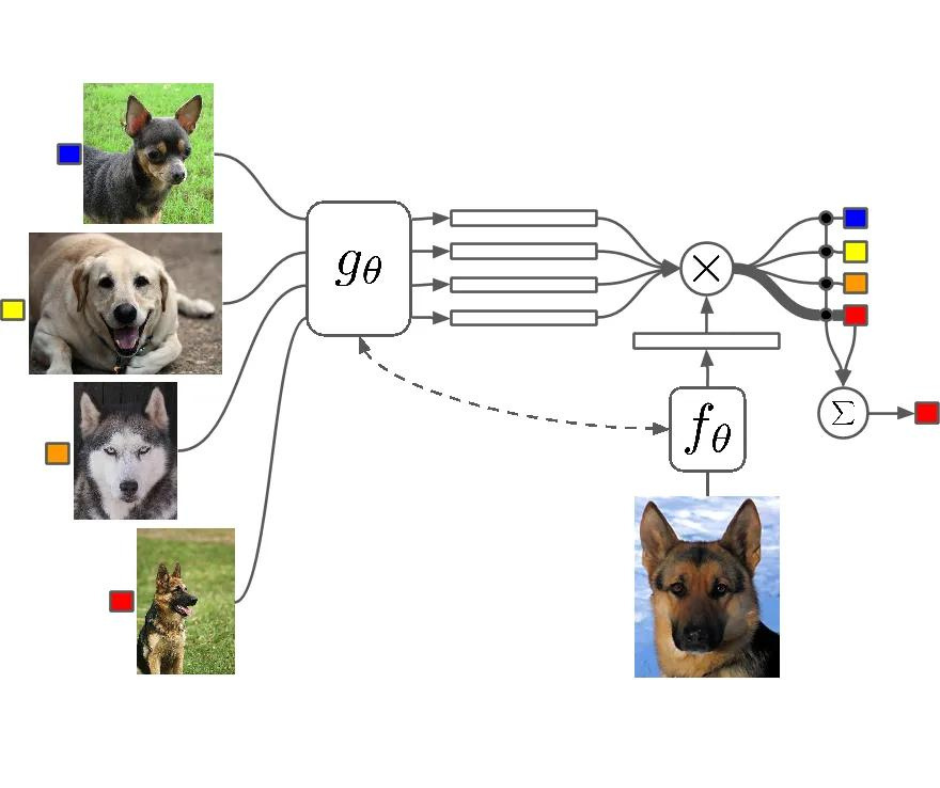
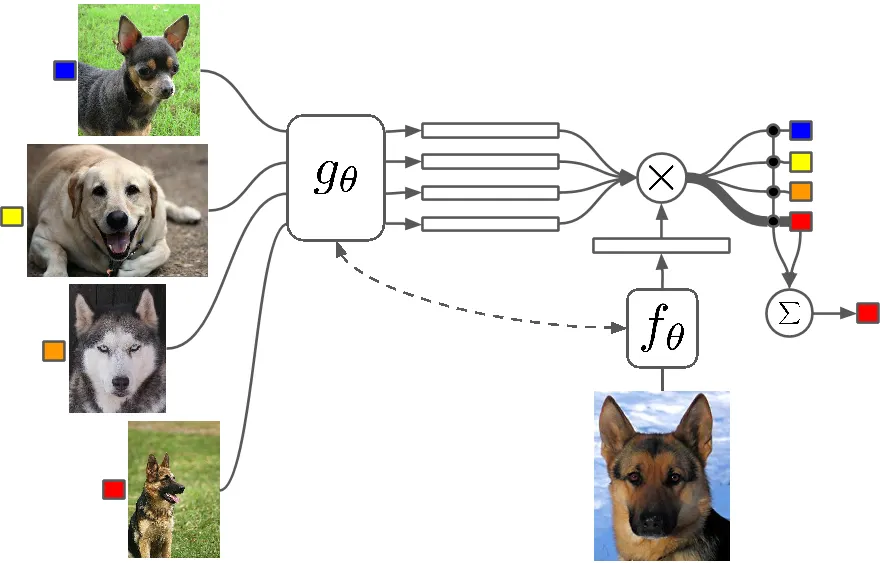
Le reti siamesi sono due reti neurali identiche, ciascuna di esse prende in input due immagini. Gli ultimi livelli delle reti rappresentano poi l’input di una funzione di perdita di paragone che calcola la somiglianza tra le due immagini. Ho realizzato un’immagine che può aiutare a capire quest’architettura:
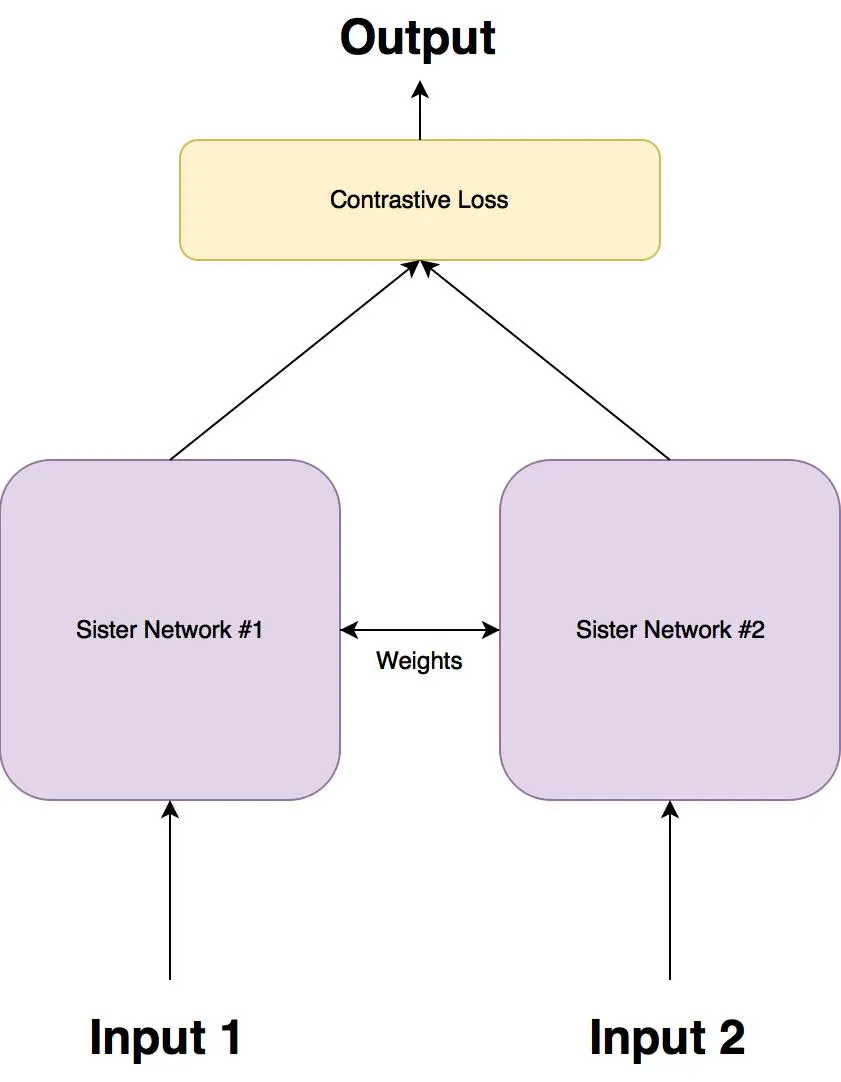
Ci sono due reti sorelle, che sono reti neurali identiche, esattamente con gli stessi pesi. Ciascun immagine nella coppia di immagini viene inviata come input a queste reti. Le reti sono ottimizzate utilizzando una funzione di perdita di paragone (arriveremo poi alla funzione esatta).
Funzione di perdita di paragone
L’obiettivo dell’architettura siamese non è quello di classificare le immagini in input, ma essere in grado di distinguerle. Quindi una funzione di perdita utilizzata per la classificazione, come la Cross Entropy, per esempio, non sarebbe una scelta adatta. Invece, quest’architettura si adatta meglio all’utilizzo di una funzione di perdita di paragone. Intuitivamente, questa funzione valuta semplicemente quanto bene la rete sta distinguendo una coppia di immagini date.
Potete leggere più dettagli in questo articolo.
La funzione di perdita di paragone ha questa formula:
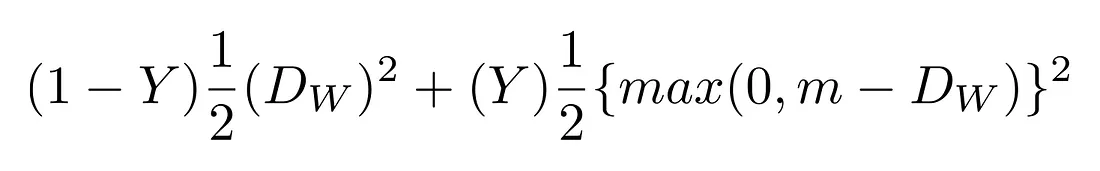
Dove Dw viene definita come la distanza euclidea tra due output delle reti siamesi. Matematicamente, la distanza euclidea si calcola come:
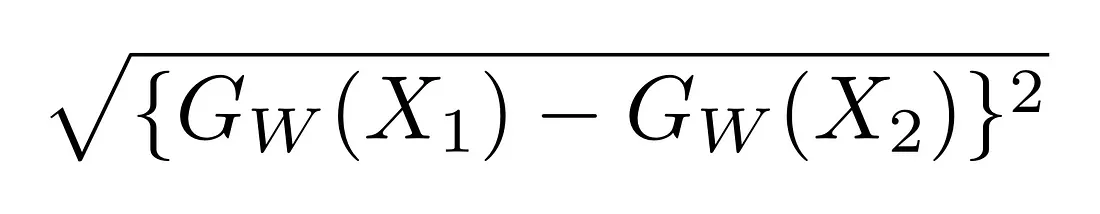
Dove Gw rappresenta l’output di una delle due reti sorelle. X1 e X2 sono la coppia di dati in input.
Spiegazione dell’equazione 1
Y può assumere valore 0 o 1. Se gli input provengono dalla stessa classe, allora Y = 0, altrimenti Y = 1.
Max() è una funzione che estrae il valore maggiore tra 0 e m-Dw, dove m è un valore margine maggiore di 0. Avere un margine significa che le coppie dissimili con un indice di somiglianza oltre il margine non contribuiscono alla funzione di perdita. Questo ha senso in quanto vorremmo ottimizzare la rete solamente basandoci sulle coppie che sono effettivamente dissimili e che la rete considera, invece, simili.
Utilizzeremo due dataset: MNIST (classico) e OmniGlot. MNIST verrà utilizzato per addestrare il modello a comprendere come distinguere i caratteri e poi testeremo il modello utilizzando OmniGlot.
Omniglot
Questo dataset consiste in campioni provenienti da 50 lingue diverse. Ciascun alfabeto ha solamente 20 campioni. Questo dataset è considerato un “trasposto” di MNIST che contiene invece 10 classi dove i campioni sono numeri. In OmniGlot c’è un numero molto grande di classi, con pochi esempi in ciascuna di esse.

OmniGlot verrà utilizzato come dataset di classificazione one shot per essere in grado di riconoscere molte classi diverse attraverso esempi alla mano.