La suddivisione di un dataset in training, validation e test set è un passaggio cruciale nella costruzione di un modello di machine learning poiché permette al modello di essere addestrato su un set, essere messo a punto su un altro e poi valutato su un set finale. I dataset di dimensioni maggiori beneficiano di una maggiore porzione di dati di training, mescolando e garantendo una distribuzione normale per evitare distorsioni. Durante questo processo è necessario dividere l’intero dataset per avere successo nel nostro task.

Dividere un dataset in training, validation e test non riguarda solamente le dimensioni del dataset ma anche la distribuzione statistica dei dati.
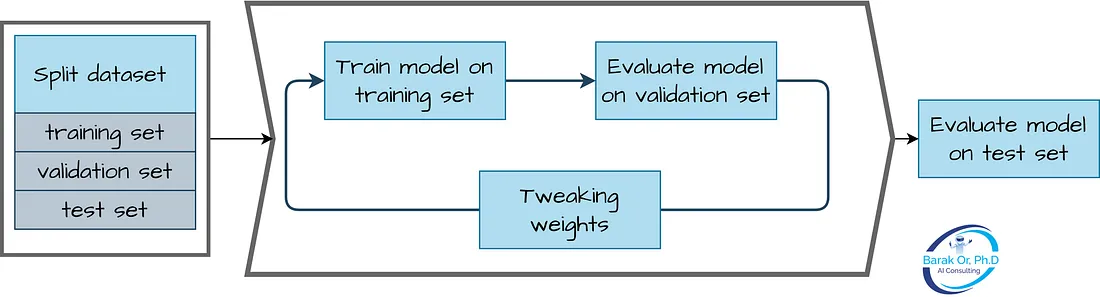
Lo scopo della suddivisione dei dati in questi set è quello di addestrare il modello sul training set, regolare gli iperparametri sul validation set e valutare le prestazioni del modello finale sul test set. Se i set di training, di validation e di test hanno distribuzioni statistiche diverse, il modello può avere buone prestazioni sui set di training e di validation ma scarse sul set di test, il che è noto come overfitting.
Pertanto, è importante assicurarsi che i set di training, validation e test abbiano distribuzioni statistiche simili. Ciò significa che la percentuale di campioni di ogni classe deve essere più o meno la stessa in tutti gli insiemi. Se il set di dati è sbilanciato, potrebbe essere necessario utilizzare tecniche come il campionamento stratificato per garantire che tutti i set abbiano una rappresentazione proporzionale di ciascuna classe.
Un’altra considerazione è quella di garantire che i campioni negli insiemi di training e di test siano selezionati in modo casuale. Ciò consente di evitare qualsiasi distorsione sistematica che potrebbe essere presente nel set di dati, come l’ordine dei campioni o la loro posizione all’interno del set di dati.
Determinare le dimensioni appropriate di training, validation e test st dipende da vari fattori come le dimensioni del dataset, la complessità, il numero delle feature e la natura del problema. In generale, dataset di dimensioni maggiori porteranno a set di training maggiori in quanto permettono al modello di comprendere relazioni complesse tra le features e la variabile target. Tuttavia, anche le dimensioni di validation e test set sono importanti in quanto permetton odi stabilire le performance del modello e la capacità di generalizzazione. Solitamente, è pratica comune dividere il dataset con una percentuale di training del 60-80%, 10-20% di validation e 10-20% di test.
La dimensione appropriata per training, validation e test set in un modello di machine learning è un fattore cruciale che spesso viene trascurato. La divisione comunemente utilizzata di 70/15/15 o addirittura 80/10/10 potrebbe non essere l’approccio migliore per i database più grandi, e la dimensione di questi set dovrebbe essere determinata in base alle dimensioni del dataset stesso.
Ad esempio, in un grande set di dati con 1.000.000 di campioni, una divisione di 98/1/1 può essere sufficiente per il testing, mentre la maggior parte dei dati viene utilizzata per l’addestramento. Tuttavia, è fondamentale rimescolare il set di dati e assicurarsi che abbia una distribuzione normale prima di dividerlo in questi insiemi.
Durante la fase di addestramento di un modello di ML, l’obiettivo è raggiungere un livello di generalizzazione che consenta al modello di ottenere buone prestazioni su dati nuovi e non visti (“capacità di generalizzazione”). Per verificare se la generalizzazione è stata raggiunta, abbiamo bisogno di un set di dati che sia statisticamente simile ai dati di addestramento. Ciò significa che la distribuzione dei dati nell’insieme di test deve essere la stessa di quella dell’insieme di addestramento.
Si pone quindi la domanda: di quanti campioni abbiamo bisogno nell’insieme di test per rappresentare accuratamente la distribuzione dei dati? Questo dipende da vari fattori, come le dimensioni del dataset e l’efficacia di tecniche come il rimescolamento e la normalizzazione. In generale, un test set più piccolo può essere sufficiente se viene selezionato correttamente e se rappresenta la stessa distribuzione statistica del set di addestramento. Tuttavia, è importante assicurarsi che l’insieme di test sia sufficientemente grande da fornire una valutazione significativa delle capacità di generalizzazione del modello.
Le ragioni alla base di questo approccio sono due. In primo luogo, i dataset di grandi dimensioni possono trarre vantaggio dall’utilizzo di una percentuale maggiore di dati per l’addestramento, in quanto ciò può aiutare il modello ad apprendere relazioni più complesse tra le caratteristiche e la variabile target. In secondo luogo, il rimescolamento del set di dati e la garanzia di una distribuzione normale prima della suddivisione possono aiutare a prevenire le distorsioni nei set risultanti, che possono influire negativamente sull’accuratezza del modello.
Comprendendo l’importanza delle dimensioni del dataset e i vantaggi del rimescolamento e della distribuzione normale, è possibile prendere decisioni informate sulle dimensioni dei set di training, validation e test nello sviluppo di modelli di machine learning.