Il meccanismo di attenzione valorizza le parti importanti dei dati in ingresso e sfuma il resto. Prendiamo l’esempio della didascalia di un’immagine. Dovrete concentrarvi sulla parte rilevante dell’immagine per generare didascalie significative. Questo è ciò che fanno i meccanismi di attenzione.
Ma perché abbiamo bisogno di attenzione e tutto il resto, le CNN sono abbastanza brave nell’estrazione di caratteristiche, giusto?
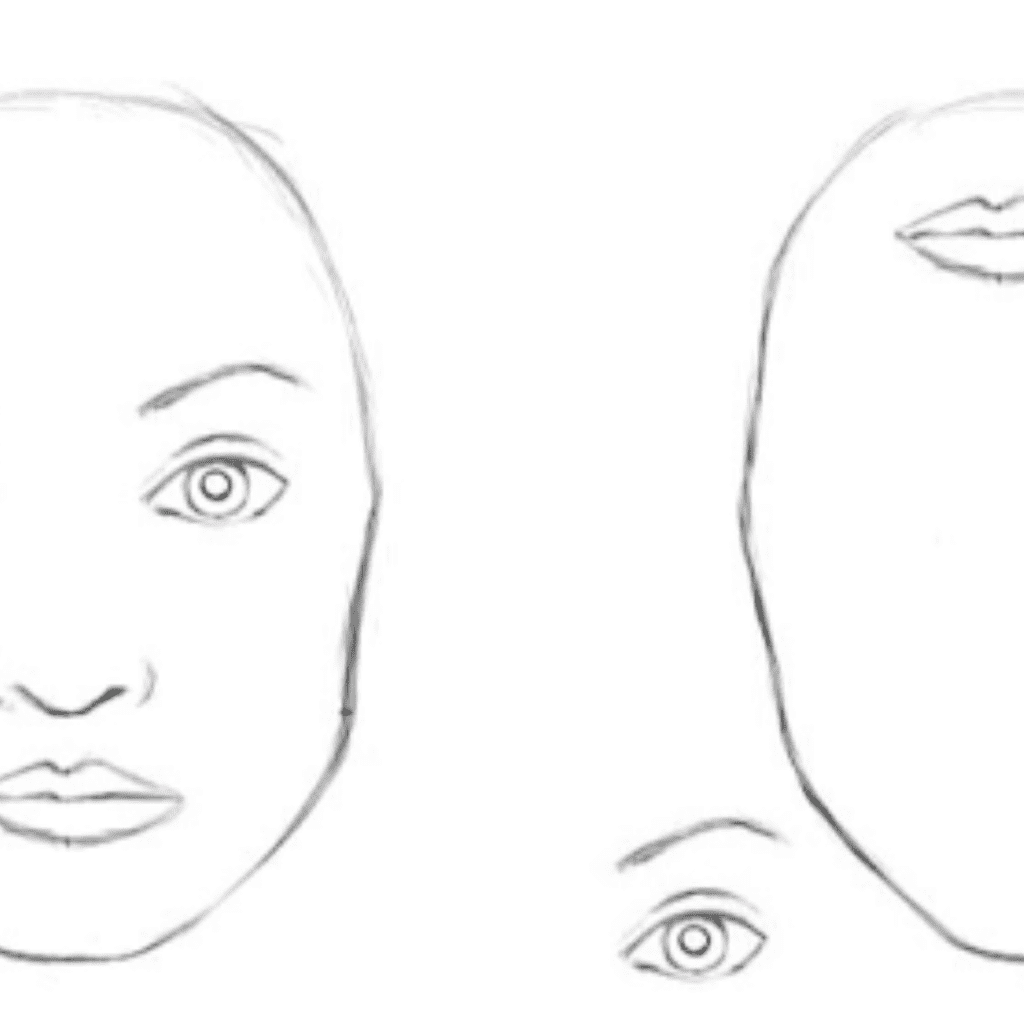
Per una CNN, entrambe le immagini sono quasi uguali. La CNN non codifica la posizione relativa delle diverse caratteristiche. Per codificare la combinazione di queste caratteristiche sono necessari filtri di grandi dimensioni. Ad esempio: per codificare l’informazione “occhi sopra il naso e la bocca” sono necessari filtri di grandi dimensioni.
I campi recettivi di grandi dimensioni sono necessari per tracciare le dipendenze a lungo raggio all’interno di un’immagine. Aumentando le dimensioni dei kernel di convoluzione si può aumentare la capacità rappresentativa della rete, ma così facendo si perde anche l’efficienza computazionale e statistica ottenuta utilizzando una struttura convoluzionale locale.
I moduli di autoattenzione, un tipo di meccanismo di attenzione, insieme alla CNN aiutano a modellare le dipendenze a lungo raggio senza compromettere l’efficienza computazionale e statistica. Il modulo di autoattenzione è complementare alle convoluzioni e aiuta a modellare le dipendenze a lungo raggio e a più livelli tra le regioni dell’immagine.

Qui si può notare che un modulo di autoattenzione sostituisce lo strato convoluzionale, in modo che ora il modello sia in grado di interagire con pixel lontani dalla sua posizione.
Più di recente, i ricercatori hanno condotto una serie di esperimenti sostituendo alcuni o tutti gli strati convoluzionali delle reti ResNet con l’attenzione, scoprendo che i modelli più performanti utilizzavano le convoluzioni nei primi strati e l’attenzione negli strati successivi.
Il meccanismo di autoattenzione è un tipo di meccanismo di attenzione che permette a ogni elemento di una sequenza di interagire con gli altri e scoprire a chi dovrebbe prestare maggiore attenzione.

Permette di catturare le informazioni a “lungo termine” e le dipendenze tra gli elementi della sequenza.
Come si può vedere dall’immagine precedente, “it” si riferisce alla “strada” e non all'”animale”. L’autoattenzione è una combinazione ponderata di tutti gli altri incorporamenti di parole. In questo caso, l’incorporazione di “it” è una combinazione ponderata di tutti gli altri vettori di incorporazione, con una maggiore ponderazione della parola “street”.
Per capire come avviene la ponderazione, guardate – https://www.youtube.com/watch?v=tIvKXrEDMhk
In sostanza, un livello di autoattenzione aggiorna ogni componente di una sequenza aggregando le informazioni globali della sequenza completa in ingresso.
Abbiamo quindi appreso come un meccanismo di attenzione come l’autoattenzione possa risolvere efficacemente alcuni dei limiti delle reti convoluzionali. Ora è possibile sostituire completamente le CNN con un modello basato sull’attenzione come i Transformers?
I trasformatori hanno già sostituito gli LSTM nel campo dell’NLP. Qual è la possibilità che i trasformatori sostituiscano le CNN nella computer vision? Quali sono gli approcci basati sull’attenzione che hanno superato le CNN? Vediamo di approfondire questo aspetto!
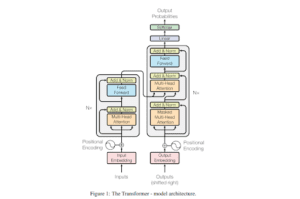
Il modello Transformer è stato proposto per la prima volta per risolvere compiti di PNL, principalmente la traduzione linguistica. Il modello Transformer proposto ha una struttura encoder-decoder. L’immagine a sinistra mostra un encoder e quella a destra un decoder. Sia il codificatore che il decodificatore hanno strati di autoattenzione, strati lineari e connessioni residue, come mostrato.
Nota: nelle reti convoluzionali, l’aggregazione e la trasformazione delle caratteristiche vengono eseguite simultaneamente (ad esempio, con uno strato di convoluzione seguito da una non linearità), mentre nel modello Transformer queste due fasi vengono eseguite separatamente, ossia lo strato di autoattenzione esegue solo l’aggregazione, mentre lo strato feed-forward esegue la trasformazione.
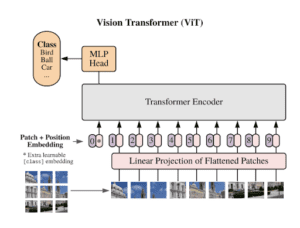
Vision Transformer è un approccio per sostituire interamente le convoluzioni con un modello Transformer.
Transformer opera sempre su sequenze, per questo motivo dividiamo le immagini in patch e appiattiamo ogni “patch” in un vettore. D’ora in poi chiamerei una “patch” come un token. Quindi ora abbiamo una sequenza di token.
L’autoattenzione, per sua natura, è invariante rispetto alla permutazione. L’autoattenzione “generalizza” l’operazione di somma in quanto esegue una somma ponderata di diversi vettori di attenzione.
L’invarianza rispetto alle permutazioni significa che se si presenta un vettore come input, ad esempio [A, B, C, D], la rete dovrebbe produrre lo stesso risultato che avrebbe ottenuto se si fosse inserito [A, C, B, D], ad esempio, o qualsiasi altra permutazione di elementi del vettore.
Quindi, l’informazione posizionale viene aggiunta a ciascun token prima di passare l’intera sequenza al modulo di autoattenzione. L’aggiunta di informazioni posizionali aiuterà il trasformatore a capire la posizione relativa di ciascun token nella sequenza. In questo caso, le codifiche posizionali vengono apprese invece di utilizzare le codifiche standard.

Infine, l’output del trasformatore dalla prima posizione viene utilizzato per un’ulteriore classificazione da parte di un MLP.
L’addestramento dei trasformatori da zero richiede molti più dati rispetto alle CNN. Questo perché le CNN codificano conoscenze pregresse sul dominio dell’immagine, come l’equivarianza traslazionale. I trasformatori, invece, devono imparare queste proprietà dai dati forniti.
L’equivarianza traslazionale è una proprietà degli strati convoluzionali, in cui lo strato delle caratteristiche avrà un’attivazione spostata verso destra, se spostiamo l’oggetto a destra nell’immagine. Ma in realtà si tratta della stessa rappresentazione.
Vision Transformer, fornisce interamente il bias induttivo convoluzionale (ad esempio, l’equivarianza) eseguendo l’autoattenzione su patch di pixel. Lo svantaggio è che richiedono una grande quantità di dati per imparare tutto da zero.
Le CNN funzionano meglio nei regimi con pochi dati grazie al loro bias induttivo. Quando invece sono disponibili molti dati, i bias induttivi (forniti dalle CNN) limitano la capacità complessiva del modello.
È quindi possibile ottenere i vantaggi dell’hard bias induttivo delle CNN in regimi di dati bassi senza soffrire dei suoi limiti in regimi di dati grandi?
L’idea è quella di introdurre un meccanismo di autoattenzione posizionale (PSA) che permetta al modello di agire come strati convoluzionali, se necessario. Sostituiamo semplicemente alcuni dei livelli di autoattenzione con giocatori PSA.
Sappiamo che l’informazione posizionale viene sempre aggiunta alle patch, poiché altrimenti le SA sono invarianti di permutazione. Invece di aggiungere alcune informazioni posizionali all’input al momento dell’embedding prima di propagarle attraverso gli strati di autoattenzione (come in Vit), sostituiamo l’autoattenzione vanilla con l’autoattenzione posizionale (PSA).
In PSA, i pesi dell’attenzione sono calcolati utilizzando le codifiche posizionali relative (r) e un embedding addestrabile (v). Le codifiche posizionali relative(r) dipendono solo dalla distanza tra i pixel.
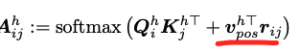
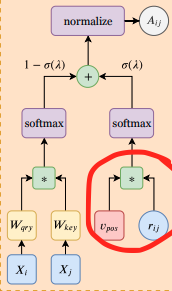
Questi strati PSA multitesta con codifiche posizionali relative apprendibili possono esprimere qualsiasi strato convoluzionale.
Non stiamo quindi combinando CNN e meccanismi di attenzione. Utilizziamo invece strati PSA che hanno la capacità di agire come strati convoluzionali regolando alcuni parametri. Utilizziamo questa potenza degli strati PSA al momento dell’inizializzazione. In regimi di dati piccoli, questo può aiutare il modello a generalizzare bene. Mentre nei regimi di dati di grandi dimensioni, gli strati PSA possono abbandonare la loro natura convoluzionale, se necessario.