Perché il Deep Learning funziona?
INTRODUZIONE
Il Deep Learning, un sottoinsieme del Machine Learning, è emerso come una tecnologia trasformativa nel campo dell’Intelligenza Artificiale, dimostrando un notevole successo in un’ampia gamma di applicazioni, dalla Computer Vision e dal Natural Language Processing fino ai veicoli autonomi e oltre. L’efficacia del Deep Learning non è casuale, ma è radicata in diversi principi fondamentali e progressi che interagiscono per rendere questi modelli eccezionalmente potenti. Questo saggio esplora le ragioni principali alla base del successo del Deep Learning, inclusa la sua capacità di apprendere rappresentazioni gerarchiche, l’impatto di set di dati di grandi dimensioni, i progressi nella potenza computazionale, le innovazioni algoritmiche, il ruolo del transfer learning e la sua versatilità e scalabilità.
Se vuoi imparare le basi del Deep Learning scopri i nostri corsi.
Il Deep Learning prospera sulla complessità, trasformando vasti dati in approfondimenti attraverso livelli di comprensione, proprio come sbucciare gli strati di una cipolla per svelarne il nucleo.
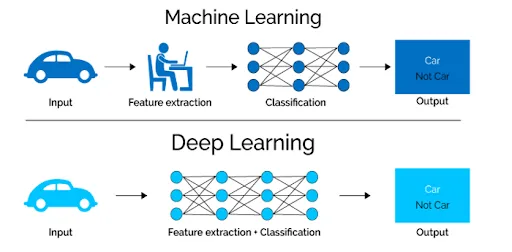
APPRENDIMENTO DELLE CARATTERISTICHE GERARCHICHE
Al centro dell’efficacia del Deep Learning c’è la sua capacità di apprendere caratteristiche gerarchiche. Le reti neurali profonde, composte da più strati, imparano a riconoscere modelli e caratteristiche a vari livelli di astrazione. I livelli iniziali potrebbero rilevare forme o trame semplici in un’immagine, mentre i livelli più profondi possono identificare oggetti o entità complesse. Questo approccio a più livelli consente ai modelli di Deep Learning di sviluppare una comprensione sfumata dei dati, proprio come il modo in cui la cognizione umana elabora le informazioni da costrutti semplici a complessi. Questo paradigma di apprendimento gerarchico è particolarmente adatto a gestire la complessità e la variabilità dei dati del mondo reale, consentendo ai modelli di generalizzare bene dai dati di addestramento a situazioni nuove.
GRANDI QUANTITA’ DI DATI
L’avvento dei big data è stato un vantaggio per il Deep Learning. Le prestazioni di questi modelli sono spesso correlate alla dimensione del set di dati su cui vengono addestrati, poiché una maggiore quantità di dati fornisce una base più ricca per apprendere i modelli sottostanti e ridurre l’overfitting. La capacità del Deep Learning di sfruttare grandi quantità di dati è stata cruciale per il suo successo, consentendo ai modelli di raggiungere e superare prestazioni di livello umano in attività come il riconoscimento delle immagini e la traduzione linguistica. Questa natura affamata di dati dei modelli di Deep Learning è stata supportata dalla digitalizzazione delle informazioni e dalla proliferazione di dispositivi e sensori generatori di dati, rendendo sempre più disponibili set di dati di grandi dimensioni per scopi di formazione.
MAGGIORE POTENZA DI CALCOLO
La fattibilità dell’addestramento di modelli di Deep Learning su larga scala è stata resa possibile in modo significativo dai progressi nell’hardware computazionale, come GPU e TPU. Queste tecnologie offrono capacità di elaborazione parallela che ben si adattano alle esigenze computazionali del Deep Learning, consentendo iterazioni e sperimentazioni più rapide. La riduzione dei tempi di formazione non solo ha accelerato il ciclo di sviluppo dei modelli di Deep Learning, ma ha anche reso possibile esplorare architetture di rete più complesse e profonde, ampliando i limiti di ciò che questi modelli possono ottenere.
INNOVAZIONI ALGORITMICHE
Il progresso nel Deep Learning è spinto anche dalle continue innovazioni algoritmiche. Tecniche come il dropout, la normalizzazione batch e gli ottimizzatori avanzati hanno affrontato alcune delle sfide iniziali nell’addestramento delle reti profonde, come l’overfitting e il problema del gradiente evanescente. Questi progressi hanno migliorato la stabilità, la velocità e le prestazioni dei modelli di Deep Learning, rendendoli più robusti e più facili da addestrare.
MODELLI DI TRANSFER LEARNING E PRE-TRAINED
Il Transfer Learning ha svolto un ruolo fondamentale nella democratizzazione del Deep Learning, consentendo l’applicazione di modelli di Deep Learning a problemi in cui non sono disponibili grandi set di dati etichettati. Mettendo a punto modelli pre-trained su set di dati di grandi dimensioni, ricercatori e professionisti possono ottenere prestazioni elevate con quantità di dati relativamente piccole. Questo approccio è stato particolarmente trasformativo in settori come l’imaging medico, dove l’acquisizione di grandi set di dati etichettati è impegnativa.
VERSATILITA’ E SCALABILITA’
Infine, la versatilità e la scalabilità dei modelli di Deep Learning hanno contribuito alla loro adozione diffusa. Questi modelli possono essere applicati ad un ampio spettro di compiti e aggiustati per adattarsi alla disponibilità di dati e risorse computazionali. Questa flessibilità ha reso il Deep Learning una soluzione ideale per una vasta gamma di problemi, guidando l’innovazione e la ricerca in tutte le discipline.
CODICE
Per dimostrare perché il Deep Learning funziona utilizzando un esempio di codice Python completo, creiamo un semplice set di dati sintetici, progettiamo un modello di Deep Learning di base, addestriamolo e valutiamo le sue prestazioni con metriche e grafici. Utilizzeremo le popolari librerie NumPy per la manipolazione dei dati, Tensor Flow e Keras per costruire e addestrare la rete neurale e Matplotlib per il tracciamento.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Step 1: Generate a Synthetic Dataset
X, y = make_moons(n_samples=1000, noise=0.1, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Step 2: Build a Deep Learning Model
model = Sequential([
Dense(10, input_dim=2, activation=‘relu’),
Dense(10, activation=‘relu’),
Dense(1, activation=‘sigmoid’)
])
model.compile(optimizer=Adam(learning_rate=0.01), loss=‘binary_crossentropy’, metrics=[‘accuracy’])
# Step 3: Train the Model
history = model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=100, verbose=0)
# Step 4: Evaluate the Model
predictions = model.predict(X_test) > 0.5
print(f“Accuracy: {accuracy_score(y_test, predictions)}”)
# Plotting
plt.figure(figsize=(14, 5))
# Plot decision boundary
plt.subplot(1, 2, 1)
plt.title(“Decision Boundary”)
x_span = np.linspace(min(X[:,0]) – 0.25, max(X[:,0]) + 0.25)
y_span = np.linspace(min(X[:,1]) – 0.25, max(X[:,1]) + 0.25)
xx, yy = np.meshgrid(x_span, y_span)
grid = np.c_[xx.ravel(), yy.ravel()]
pred_func = model.predict(grid) > 0.5
z = pred_func.reshape(xx.shape)
plt.contourf(xx, yy, z, alpha=0.5)
plt.scatter(X[:,0], X[:,1], c=y, cmap=‘RdBu’, lw=0)
# Plot loss over epochs
plt.subplot(1, 2, 2)
plt.title(“Training and Validation Loss”)
plt.plot(history.history[‘loss’], label=‘Train Loss’)
plt.plot(history.history[‘val_loss’], label=‘Val Loss’)
plt.legend()
Questo codice esegue le seguenti operazioni:
-
-
-
- Genera un set di dati sintetico utilizzando la funzione make_moons di sklearn, adatta a dimostrare la potenza del Deep Learning su dati non linearmente separabili.
- Costruisce una semplice rete neurale con due livelli nascosti, utilizzando l’attivazione ReLU per i livelli nascosti e l’attivazione sigmoide per il livello di output, per eseguire la classificazione binaria.
- Addestra il modello sul set di dati sintetico, utilizzando l’entropia incrociata binaria come funzione di perdita e l’ottimizzatore Adam.
- Valuta la precisione del modello su un set di prova e lo stampa.
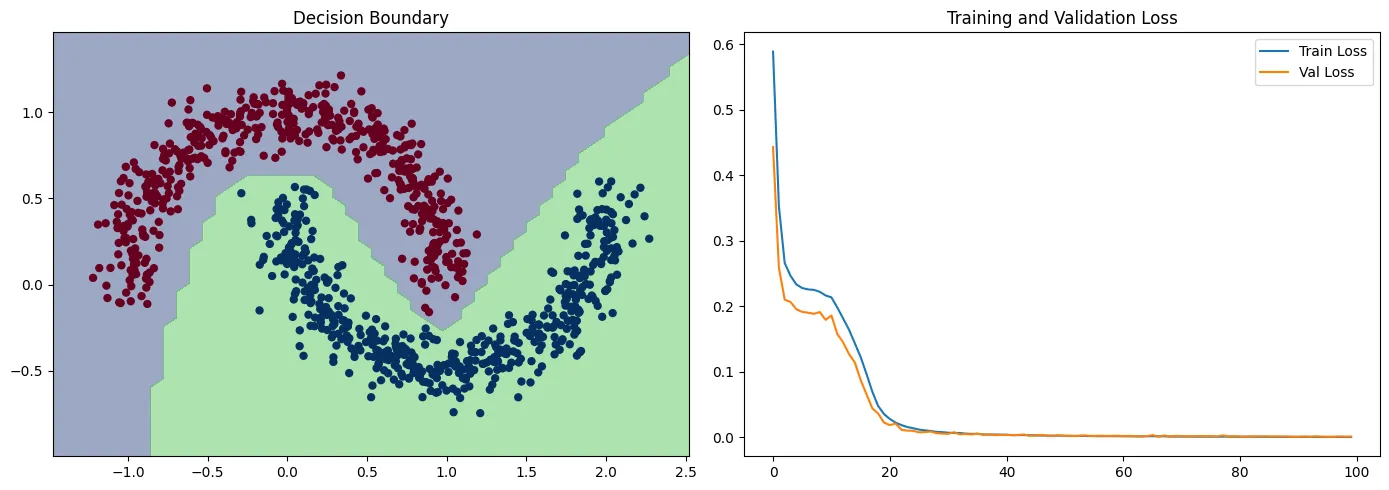
- Traccia il confine decisionale appreso dal modello per verificare visivamente quanto bene separa le due classi e traccia la perdita di formazione e convalida nel corso delle epoche per dimostrare il processo di apprendimento.
-
-
Questo esempio illustra l’efficacia del Deep Learning nell’apprendimento di modelli complessi dai dati, anche con un’architettura di rete relativamente semplice. Il diagramma dei confini della decisione mostrerà come il modello ha imparato a separare le due classi, mentre il diagramma delle perdite dimostrerà i progressi di apprendimento del modello nel tempo.
CONCLUSIONE
In conclusione, il successo del Deep Learning è attribuito al suo approccio sofisticato all’apprendimento delle funzionalità, alla disponibilità di grandi set di dati, ai progressi nell’hardware computazionale, alle innovazioni algoritmiche, all’utilità del Transfer Learning e alla sua intrinseca versatilità e scalabilità. Man mano che il settore continua ad evolversi, si prevede che ulteriori progressi nel Deep Learning sbloccheranno nuove capacità e applicazioni, continuando la sua traiettoria come tecnologia fondamentale nell’intelligenza artificiale.
Articolo ripreso da: Evertone Gomene via Medium
Share:
