Ho scritto questa prefazione per un libro di Machine Learning. Ho pensato che potesse interessare più persone che solo i lettori del libro. Quindi lo sto condividendo qui. In questa prefazione, avrei dovuto descrivere dove sta la convenienza nell’adottare il software KNIME per i tuoi progetti di data science.
— — — — — — —

Il successo dei data scientist al lavoro dipende in gran parte dallo strumento su cui fanno affidamento.
La conoscenza matematica degli algoritmi, l’esperienza sugli algoritmi più efficaci, la saggezza di dominio, sono tutti ingredienti di base, importanti, necessari per il successo di un progetto di data science. Tuttavia, ci sono altri fattori più contingenti che influenzano anche l’impressione finale lasciata sugli stakeholder.
Chiaramente, ogni progetto ha una scadenza, spesso è stringente che non lascia molto margine per un approccio “try and error”. Dobbiamo implementare una soluzione in breve tempo e assicurarci che sia corretta. Abbiamo bisogno di sperimentare rapidamente diverse tecniche per raggiungere e adottare la procedura migliore per il progetto. Naturalmente, ogni progetto ha anche un budget. La rapida implementazione della soluzione è spesso ulteriormente limitata da un budget ridotto.
Alcuni progetti sono piuttosto complessi e richiedono tecniche specializzate, oltre ai classici algoritmi generali di machine learning. A volte, siamo costretti ad apprendere nuove tecniche e nuovi algoritmi sul posto – cioè sul progetto – e, data la scadenza, la curva di apprendimento deve svilupparsi in breve tempo. In questo caso, più tempo abbiamo da dedicare alla teoria e alla matematica, più velocemente procederà l’apprendimento.
Infine, il passaggio dal prototipo alla produzione deve essere il più veloce (di nuovo) e il più sicuro possibile. Non possiamo correre il rischio di degradare parti della soluzione mentre la trasferiamo in produzione ed esponendola a un diverso gruppo di utenti meno esperti. Se necessario, un diverso insieme di soluzioni, con più o meno gradi di interazione, dovrebbe essere messo a disposizione del grande pubblico.
Come si vede, molti altri fattori contingenti, come la facilità di apprendimento, la velocità di implementazione del prototipo, le opzioni di debug e test per garantire la correttezza della soluzione, la flessibilità di sperimentare approcci diversi, la disponibilità di aiuto da parte di collaboratori esterni ed esperti e, infine, le capacità di automazione e sicurezza, contribuiscono tutti al successo del progetto di scienza dei dati, oltre la matematica, l’esperienza e la conoscenza del dominio. Tutti questi fattori contingenti dipendono fortemente dallo strumento utilizzato dai data scientist.
Vincoli di progetto: tempo e denaro
KNIME Analytics Platform è un software open source per tutte le tue esigenze di dati. È scaricabile gratuitamente dal sito web KNIME e gratuito, copre tutte le principali tecniche di data wrangling e machine learning e si basa sulla programmazione visiva.
Le implicazioni dell’essere open source e liberi di usare sono autoesplicative, riducendo i grattacapi legali delle licenze e l’impatto sul budget del progetto.
L’impatto della programmazione visiva potrebbe richiedere qualche parola in più di spiegazione. La programmazione visiva è diventata molto popolare negli ultimi tempi e mira a sostituire, parzialmente o completamente, la pratica della codifica. Nella programmazione visiva, un’interfaccia utente grafica (GUI) guida l’utente attraverso tutti i passaggi necessari per creare una pipeline (flusso di lavoro) di blocchi dedicati (nodi). Ogni nodo implementa un determinato compito; Ogni flusso di lavoro di nodi prende i tuoi dati dall’inizio alla fine del percorso progettato. Un flusso di lavoro sostituisce uno script; Un nodo sostituisce una o più righe di script.
In KNIME Analytics Platform, i nodi vengono creati trascinando (o facendo doppio clic) dal Node Repository nell’editor del flusso di lavoro nella parte centrale dell’ambiente di lavoro KNIME. Nodo dopo nodo, la pipeline viene rapidamente costruita, configurata, eseguita, ispezionata e documentata.
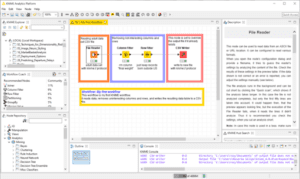
La programmazione visiva è una caratteristica chiave di KNIME Analytics Platform per la prototipazione rapida. Rende lo strumento molto facile da usare. Produrre alcuni prototipi sperimentali diversi, prima di decidere la direzione finale del progetto, è veloce e abbastanza semplice. La facilità di implementazione libera tempo per pensare più a fondo alle possibili alternative teoriche alla soluzione attuale.
Il KNIME Hub è il repository pubblico per la comunità KNIME. Qui puoi condividere i tuoi flussi di lavoro e scaricare i flussi di lavoro di altri utenti KNIME. Basta digitare le parole chiave e otterrai un elenco di flussi di lavoro, componenti, estensioni e altro correlati. È un ottimo punto di partenza con molti esempi! Ad esempio, basta digitare nella casella di ricerca “base” o “principianti” e si otterrà un elenco di flussi di lavoro di esempio che illustrano i concetti di base in KNIME Analytics Platform; digita “leggi file” e otterrai un elenco di flussi di lavoro di esempio che illustrano come leggere file CSV, file .table, file excel, ecc. Si noti che un sottoinsieme di questi flussi di lavoro di esempio è riportato anche nel server EXAMPLES nel pannello KNIME Explorer nell’angolo superiore sinistro dell’ambiente di lavoro KNIME.
Una volta isolato il flusso di lavoro di interesse, fai clic su di esso per aprire la sua pagina, quindi scaricalo o aprilo sulla tua piattaforma di analisi KNIME. Una volta nell’area di lavoro locale, puoi iniziare ad adattarla ai tuoi dati e alle tue esigenze. Seguendo la tendenza popolare nella programmazione – ovvero la ricerca di pezzi di codice pronti all’uso – puoi semplicemente scaricare, riutilizzare e riadattare i flussi di lavoro o i flussi di lavoro dall’hub KNIME al tuo problema.
Naturalmente, puoi anche condividere il tuo lavoro sul KNIME Hub per il bene pubblico. È sufficiente copiare i flussi di lavoro da condividere dall’area di lavoro locale nella cartella My-KNIME-Hub/Public nel pannello KNIME Explorer all’interno dell’ambiente KNIME.
La comunità KNIME non si ferma al KNIME Hub. È davvero molto attivo con suggerimenti e trucchi anche sul Forum KNIME. Qui puoi porre domande o cercare risposte precedenti. La comunità è molto attiva ed è molto probabile che qualcuno abbia già posto la tua domanda.
Infine, i contenuti innovativi prodotti da KNIMErs sono disponibili come post sul blog KNIME, come libri sulla KNIME Press e come video sul canale KNIME TV su YouTube.
Nota. Da giugno 2021, KNIME ha una propria pubblicazione su Medium: Low Code for Advanced Data Science. Pubblichiamo contenuti su storie di dati di successo, teoria della scienza dei dati, suggerimenti e trucchi per iniziare a utilizzare KNIME Analytics Platform e altro ancora. E la cosa migliore è che raccoglie articoli scritti dalla comunità per la comunità. Scopri come contribuire e condividere le tue storie qui.