Tutti amano la semplicità di scikit-learn e la famosissima funzione train_test_split è parte di milioni di tutorial sul machine learning. Tuttavia, il suo utilizzo in problemi reali di apprendimento automatico spesso vi spezzerà il collo! In questo breve articolo, vi spiegherò perché e vi collegherò ad alcune risorse che possono aiutarvi a scegliere saggiamente la divisione train/test.
La suddivisione casuale e l’analisi di metriche globali come l’accuratezza sono facili e veloci, ma cosa succede se ci sono 20 diversi sottogruppi di campioni che devono essere classificati correttamente per rendere fattibile il vostro caso d’uso? E se ci fossero casi limite fortemente sottorappresentati ma altrettanto importanti, ad esempio i casi in cui la macchina si guasta nel caso d’uso della manutenzione predittiva?
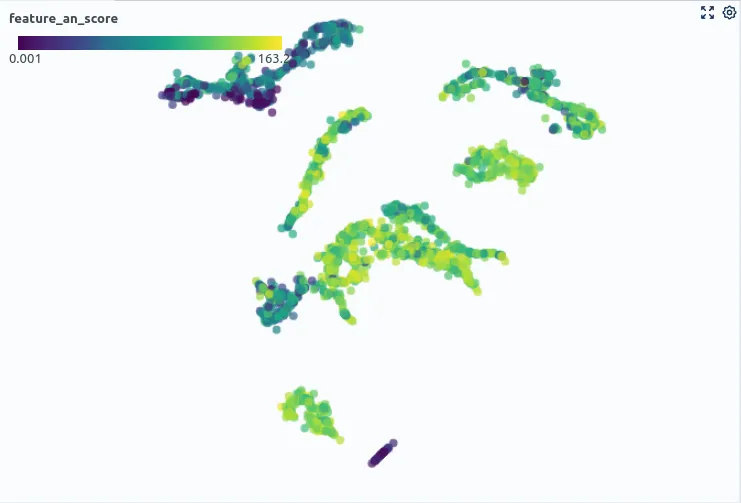
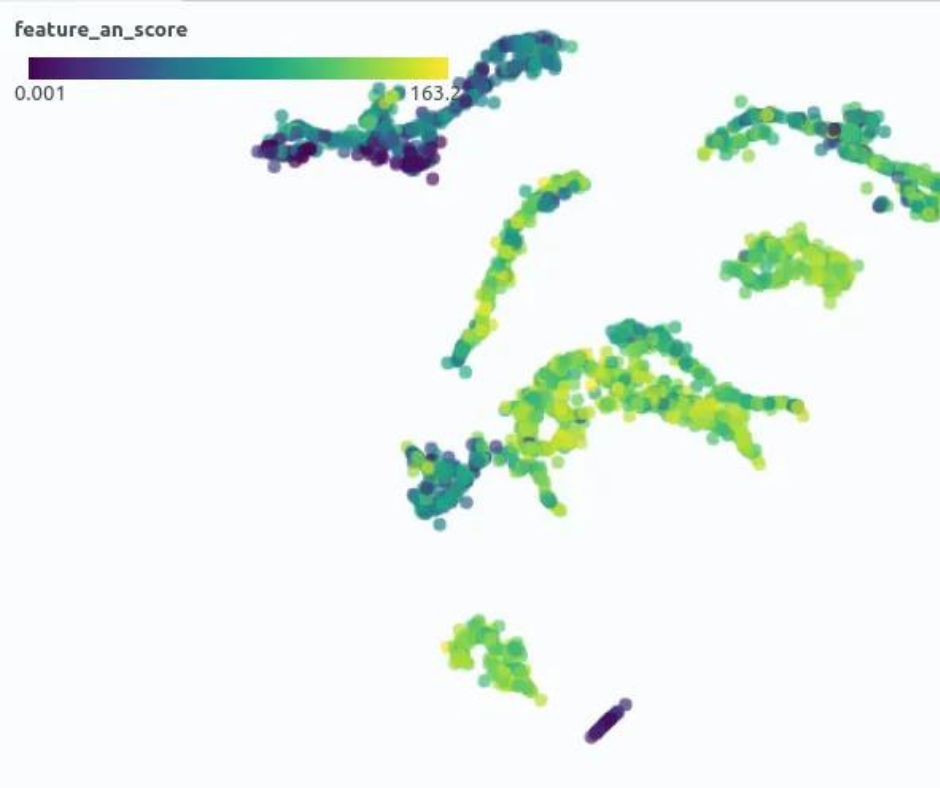
Assicuratevi di sapere quali sottogruppi esistano nei vostri dati! Con questo intendo quelli facilmente riconoscibili, ad esempio utilizzando le etichette di classe, ma anche quelli non esplicitamente indicati. In molti casi, si avranno molti gruppi diversi all’interno di una stessa classe, ad esempio, in un contesto di manutenzione predittiva, si potrebbero avere macchine normalmente funzionanti con rumore di fondo forte e silenzioso. Ecco i miei consigli principali per trattare i sottogruppi nei dati:
- Esplorate i vostri dati nel contesto del caso d’uso, ad esempio con Spotlight
- Utilizzate la riduzione della dimensionalità come modo per valutare visivamente gruppi e somiglianze tra i dati, ad esempio con UMAP
- Utilizzate l’analisi automatica dei sottogruppi ad esempio attraverso features di clustering con scikit-learn o librerie specializzate come pysubgroup
- Calcolate le metriche sui sottogruppi identificati utilizzando pacchetti come fairlearn
Inoltre, assicuratevi di identificare i casi limite e i sottogruppi meno rappresentati includendoli nel test set. Questi suggerimenti possono aiutarvi a riguardo:
- Utilizzare tecniche di riconoscimento degli outlier per trovarer campioni di dati insoliti, ad esempio con PyOD
- Per i dati non strutturati, sruttate gli strumenti EDA ce consentono di identificare pattern insoliti nei dati e di visualizzare direttamente dati non strutturati (immagini, audio, serie temporali ecc.), ad esempio Spotlight
- Quando utilizzate funzioni come train_test_split in scikit-learn, considerate di utilzizare il parametro stratify per assicurarvi che le classi più piccole siano rappresentate sia nel training che nel test (https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html)