Questo articolo tratta di:
- Perché un altro tutorial sulle pipeline?
- Creare un trasformatore personalizzato da zero, da includere nella pipeline.
- Modificare e parametrizzare i trasformatori.
- Trasformazione personalizzata del target tramite TransformedTargetRegressor.
- Concatenare tutto in un’unica pipeline.
- Link per scaricare il codice completo da GitHub.
Alla fine c’è un video che illustra il codice per chi preferisce il formato. Personalmente, mi piacciono i tutorial scritti, ma in passato ho ricevuto richieste di versioni video, quindi eccoli qui.

Visto che siete qui, è molto probabile che sappiate già che le pipeline vi semplificano la vita preelaborando i dati. L’ho sentito dire anch’io e ho cercato di implementarne una nel mio codice.
Un saluto ai pochi ottimi tutorial che sono riuscito a trovare sull’argomento! Vi consiglio di sfogliarli, prima o dopo l’articolo in corso:
- https://towardsdatascience.com/custom-transformers-and-ml-data-pipelines-with-python-20ea2a7adb65
- https://machinelearningmastery.com/how-to-transform-target-variables-for-regression-with-scikit-learn
iii. http://zacstewart.com/2014/08/05/pipelines-of-featureunions-of-pipelines.html
È andato tutto bene quando ho seguito i tutorial e ho usato imputazione standard, scalatura, trasformazioni di potenza, ecc. Ma poi ho voluto scrivere una logica specifica da applicare ai dati e non ero molto sicuro di cosa venisse chiamato dove?
Ho provato a cercare una spiegazione lucida su quando vengono effettivamente richiamate le funzioni constructor, fit(), transform(), ma non sono riuscito a trovare un esempio semplice. Ho quindi deciso di analizzare il codice un po’ alla volta e di presentare la mia comprensione a chiunque voglia capirlo da zero.
Cominciamo allora!
Creare un trasformatore personalizzato da zero, da includere nella pipeline
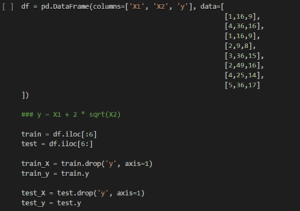
Per capire meglio gli esempi, creeremo un set di dati che ci aiuterà a esplorare meglio il codice.
Il codice precedente crea dati che seguono l’equazione y = X1 + 2 * sqrt(X2). Questo fa sì che un semplice modello di regressione lineare non sia in grado di adattarsi perfettamente.
Vediamo quali sono i risultati delle previsioni:
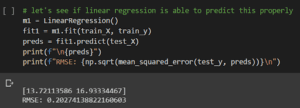
Una previsione perfetta sarebbe 14 e 17. Le previsioni non sono male, ma possiamo fare qualche calcolo sulle caratteristiche di input per migliorarle?
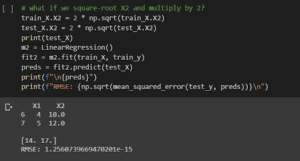
Le manipolazioni dell’input fanno sì che si adatti a un trend lineare perfetto (y=X1+X2 ora) e quindi a previsioni perfette. Ora, questo è solo un esempio, ma supponiamo che per un set di dati l’analisi indichi che una tale trasformazione degli input sarebbe buona, come si fa a farlo in modo sicuro tramite le Pipeline.
Vediamo un modello di base di LinearRegression() adattato utilizzando una Pipeline.
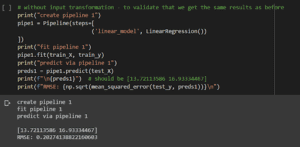
Come previsto, otteniamo le stesse previsioni del primo tentativo. La sintassi a questo punto è piuttosto semplice: – La sintassi è la stessa.
- Dichiariamo una variabile pipe1 utilizzando la classe Pipeline con un array di passi al suo interno. Il nome del passo (in questo caso linear_model) può essere qualsiasi cosa di propria scelta. È seguito da un trasformatore o stimatore vero e proprio (in questo caso, il nostro modello LinearRegression()).
- Come qualsiasi altro modello, viene applicato ai dati di allenamento, ma utilizzando la variabile pipe1.
- Usare pipe1 per predire sul set di test, come si farebbe con qualsiasi altro modello.
Per eseguire i calcoli e le trasformazioni dell’input, progetteremo un trasformatore personalizzato.
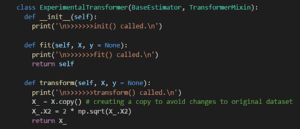
Creiamo una classe e la chiamiamo ExperimentalTransformer. Tutti i trasformatori che progettiamo erediteranno dalle classi BaseEstimator e TransformerMixin, che ci forniscono gratuitamente i metodi preesistenti. Potete leggere di più su di esse nei link agli articoli che ho fornito sopra.
Ci sono 3 metodi di cui occuparsi:
- __init__ : Questo è il costruttore. Viene chiamato quando la pipeline viene inizializzata.
- fit() : Richiamato quando si adatta la pipeline.
- transform() : Chiamato quando si usa fit o transform sulla pipeline.
Per il momento, mettiamo i messaggi print() in __init__ e fit() e scriviamo i nostri calcoli in transform().
Come si vede sopra, i valori modificati vengono restituiti lì. Tutte le caratteristiche in ingresso saranno passate in X quando viene richiamato fit() o transform().
Inseriamo il tutto in una pipeline per vedere l’ordine di chiamata di queste funzioni.
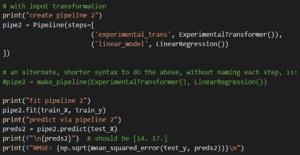
Come si può vedere nei commenti al codice qui sopra, si può anche usare la sintassi make_pipeline(), che è più breve, per creare pipeline.
Ora l’output:
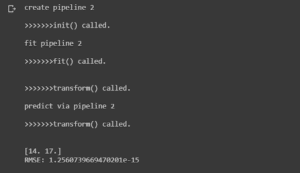
3 cose importanti da notare:
- __init__ è stato chiamato nel momento in cui abbiamo inizializzato la variabile pipe2.
- Sia fit() che transform() del nostro ExperimentalTransformer sono stati chiamati quando abbiamo applicato la pipeline ai dati di allenamento. Questo ha senso, perché è così che funziona l’adattamento del modello. Sarebbe necessario trasformare le caratteristiche di input mentre si cerca di predire train_y.
- transform() viene richiamato, come previsto, quando chiamiamo predict(test_X) – le caratteristiche di test in ingresso devono essere radicate al quadrato e raddoppiate prima di fare previsioni.
Il risultato: previsioni perfette!
Modificare e parametrizzare i trasformatori
Ma…
Nella funzione transform() del nostro ExperimentalTransformer abbiamo assunto che il nome della colonna sia X2. Non facciamo così e passiamo il nome della colonna tramite il costruttore, __init__().
Ecco il nostro ExperimentalTransformer_2:
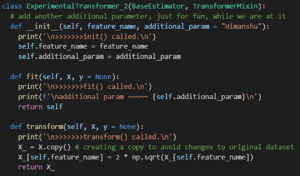
Take care to keep the parameter name exactly the same in the function argument as well as the class’ variable (feature_name or whichever name you choose). Changing that will cause problems later, when we also try to transform the target feature (y). It causes a double-call to __init__ for some reason.
I also added an additional_param with a default value, just to mix things up. It’s not really needed for anything in our case, and acts as an optional argument.
Create the new pipeline now:

Calling with new Pipeline
L’output è quello previsto:
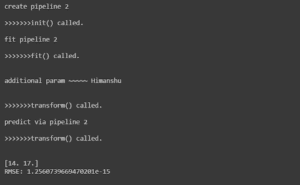
New output, same as before
Trasformazione personalizzata del target tramite TransformedTargetRegressor
Che dire di una situazione in cui è necessario effettuare alcune pre e post elaborazioni?
Consideriamo un set di dati leggermente modificato:
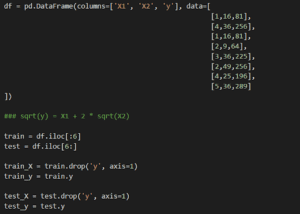
y squared in dataset
Tutto è uguale, ma ora y è stato elevato al quadrato. Per far sì che questo si adatti a un semplice modello lineare, dovremo elevare y al quadrato prima di applicare il nostro modello e, successivamente, elevare al quadrato qualsiasi previsione fatta dal modello.
Possiamo usare TransformedTargetRegressor di scikit-learn per istruire la nostra pipeline a eseguire alcuni calcoli e calcoli inversi sulla variabile target. Scriviamo prima queste due funzioni:
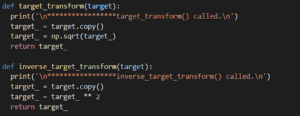
Transform and inverse-transform functions
Una radice quadrata di y e l’altra la riquadrano.
Chiamata tramite pipeline:
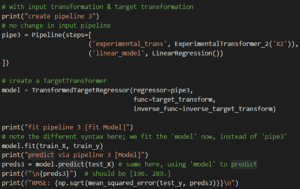
TransformedTargetRegressor call
La classe TransformedTargetRegressor accetta gli argomenti regressor, func e inverse_func che collegano la nostra pipeline a queste nuove funzioni.
Si noti che ora adattiamo il modello, non la pipeline.
L’output mostra però qualcosa di interessante e inaspettato:
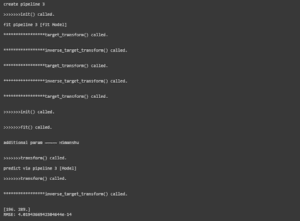
First output with TargetRegressor
The results are fine, but can you see how our target_transform() and i metodi inverse_target_transform() sono stati chiamati più volte quando è stato chiamato fit()? Questo diventerà un overhead nei grandi progetti e nelle pipeline complesse. La modifica necessaria per gestire questo problema consiste semplicemente nell’impostare il parametro check_inverse di TransformedTargetRegressor a False. Lo faremo nel prossimo passo, insieme all’esame di un altro modo di gestire la trasformazione del target, usando i parametri transformer all’interno di TransformedTargetRegressor invece di func e inverse_func.
Possiamo passare un trasformatore incorporato o il nostro trasformatore personalizzato al posto delle due funzioni che abbiamo progettato. Il trasformatore personalizzato sarà quasi identico a quello progettato in precedenza per la nostra pipeline, ma avrà una funzione inverse_transform aggiuntiva al suo interno. Ecco l’implementazione:
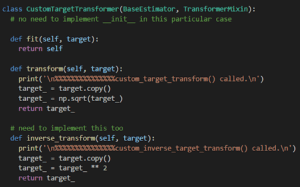
CustomTargetTransformer
È tutto, basta usarlo nella nostra chiamata a TransformedTargetRegressor:
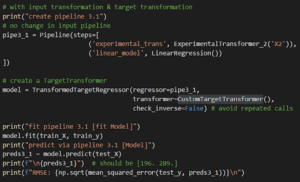
Call with transformer param
L’output sembra ora corretto:
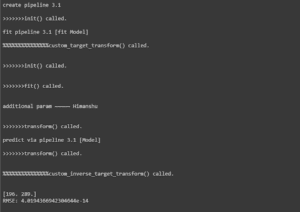
Output with no repeated calls
Un’ultima cosa da fare qui. Faremo uso della cache per preservare i calcoli e vedremo anche come ottenere o impostare i parametri della nostra pipeline dall’esterno (questo sarà necessario in seguito, se si vuole applicare GridSearch su questo).
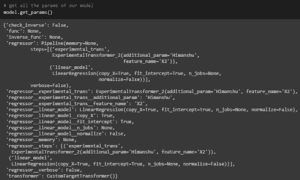
get_params()
Si noti come sia possibile accedere a ciascun parametro di ogni componente della pipeline utilizzando il suo nome seguito da un doppio trattino basso __.
Ora uniremo il tutto e proveremo anche a impostare un parametro dall’esterno: il nome della colonna X2 che abbiamo passato al costruttore.
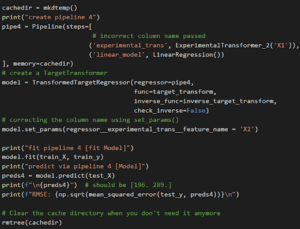
Tying it all together
Complete Code: https://github.com/HCGrit/MachineLearning-iamJustAStudent/tree/master/PipelineFoundation
Code walkthrough: https://youtu.be/mOYJCR0IDk8
Articolo originale di Himanshu Chandra
