2019, 3 ottobre – Aggiornamento: pubblichiamo il documento del workshop NeurIPS 2019 che descrive il nostro approccio su DistilBERT con risultati migliori: 97% delle prestazioni di BERT su GLUE (i risultati del documento sono superiori a quelli presentati qui). L’approccio è leggermente diverso da quello spiegato in questo blog post, quindi questo blog post dovrebbe essere un buon punto di ingresso al paper! Abbiamo applicato lo stesso metodo a GPT2 e stiamo rilasciando DistilGPT2! Il codice di addestramento e i pesi pre-addestrati per DistilBERT e DistilGPT2 sono disponibili qui. 🤗
Negli ultimi 18 mesi, l’apprendimento per trasferimento da modelli linguistici su larga scala ha migliorato significativamente lo stato dell’arte in quasi tutte le attività di elaborazione del linguaggio naturale.
Solitamente basati sull’architettura Transformer di Vaswani et al., questi modelli linguistici pre-addestrati continuano a diventare sempre più grandi e ad essere addestrati su set di dati più grandi. L’ultimo modello di Nvidia ha 8,3 miliardi di parametri: 24 volte più grande di BERT-large, 5 volte più grande di GPT-2, mentre RoBERTa, l’ultimo lavoro di Facebook AI, è stato addestrato su 160 GB di testo 😵
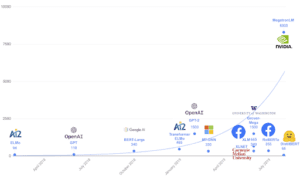
Some people in the community question the relevance of keeping on training larger and larger Transformer especially when you take into account the financial and environmental cost of training. Here’s are some of the latest large models and their size in millions of parameters.
In Hugging Face abbiamo sperimentato in prima persona la crescente popolarità di questi modelli, dato che la nostra libreria di PNL – che ne racchiude la maggior parte – è stata installata più di 400.000 volte in pochi mesi.
Tuttavia, mentre questi modelli raggiungevano una comunità NLP più ampia, ha iniziato a emergere una domanda importante e impegnativa. Come possiamo mettere in produzione questi mostri? Come possiamo utilizzare modelli così grandi con vincoli di bassa latenza? Abbiamo bisogno di (costosi) server GPU per servire in scala?
Per molti ricercatori e sviluppatori, questi possono essere problemi che rompono le righe 💸
Per costruire sistemi più rispettosi della privacy, abbiamo notato una crescente necessità di far funzionare i sistemi di apprendimento automatico sul bordo piuttosto che chiamare un’API del cloud e inviare dati eventualmente privati ai server. L’esecuzione di modelli su dispositivi come lo smartphone 📲 richiede inoltre modelli leggeri, reattivi ed efficienti dal punto di vista energetico!
Infine, ma non per questo meno importante, siamo sempre più preoccupati dei costi ambientali legati alla scalabilità esponenziale dei requisiti di calcolo di questi modelli.
Quindi, come possiamo ridurre le dimensioni di questi modelli mostruosi?
Ci sono molte tecniche disponibili per affrontare le domande precedenti. Gli strumenti più comuni includono la quantizzazione (approssimazione dei pesi di una rete con una precisione minore) e la potatura dei pesi (rimozione di alcune connessioni nella rete). Per queste tecniche, potete dare un’occhiata all’eccellente post di Rasa sulla quantizzazione di BERT. In ogni caso, anche noi abbiamo dei corsi (interamente in Italiano) su questi argomenti e sul NLP in generale
Abbiamo deciso di concentrarci sulla distillazione: una tecnica che si può utilizzare per comprimere un modello di grandi dimensioni, chiamato insegnante, in un modello più piccolo, chiamato studente.
La distillazione della conoscenza (talvolta definita anche apprendimento insegnante-allievo) è una tecnica di compressione in cui un modello di piccole dimensioni viene addestrato per riprodurre il comportamento di un modello più grande (o di un insieme di modelli).
È stata introdotta da Bucila et al. e generalizzata da Hinton et al. qualche anno dopo. Noi seguiremo quest’ultimo metodo.
Nell’apprendimento supervisionato, un modello di classificazione viene generalmente addestrato a prevedere una classe d’oro massimizzando la sua probabilità (softmax di logits) utilizzando il segnale di log-likelihood. In molti casi, un modello dalle buone prestazioni predirà una distribuzione di output con la classe corretta ad alta probabilità, lasciando le altre classi con probabilità prossime allo zero.
Tuttavia, alcune di queste probabilità “quasi zero” sono più grandi delle altre e questo riflette, in parte, le capacità di generalizzazione del modello.
Ad esempio, una sedia da scrivania potrebbe essere confusa con una poltrona, ma di solito non dovrebbe essere confusa con un fungo. Questa incertezza viene a volte definita “conoscenza oscura” 🌚
Un altro modo di intendere la distillazione è che impedisce al modello di essere troppo sicuro della sua previsione (in modo simile allo smoothing delle etichette).
Ecco un esempio per vedere questa idea nella pratica. Nella modellazione linguistica, possiamo osservare facilmente questa incertezza osservando la distribuzione del vocabolario. Ecco le prime 20 ipotesi di BERT per il completamento di questa famosa citazione dal film Casablanca:
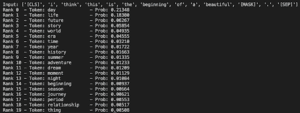
The top 20 guesses from BERT (base) for the masked token. The Language model identified two highly probable tokens (day & life) followed by a long tail of valid tokens.
Nell’addestramento insegnante-studente, addestriamo una rete studente a imitare l’intera distribuzione di output della rete insegnante (la sua conoscenza).
Stiamo addestrando lo studente a generalizzare nello stesso modo dell’insegnante, facendo corrispondere la distribuzione dei risultati.
Invece di addestrare con un’entropia incrociata sugli hard target (codifica one-hot della classe gold), trasferiamo la conoscenza dall’insegnante allo studente con un’entropia incrociata sui soft target (probabilità dell’insegnante). La nostra perdita di formazione diventa quindi:
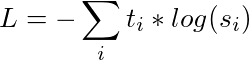
Con t i logits dell’insegnante e s i logits dello studente.
Questa perdita rappresenta un segnale di addestramento più ricco, poiché un singolo esempio impone molti più vincoli di un singolo obiettivo rigido.
Per esporre ulteriormente la massa della distribuzione sulle classi, Hinton et al. introducono una temperatura softmax:
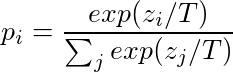
T è il parametro della temperatura.
Quando T → 0, la distribuzione diventa una Kronecker (ed è equivalente al vettore target one-hot), quando T →+∞, diventa una distribuzione uniforme. Lo stesso parametro di temperatura viene applicato sia allo studente che all’insegnante al momento dell’addestramento, rivelando ulteriormente più segnali per ogni esempio di addestramento. Al momento dell’inferenza, T viene impostato a 1 e si recupera il Softmax standard.
Vogliamo comprimere un modello linguistico di grandi dimensioni usando la distillazione. Per la distillazione, utilizzeremo la perdita di Kullback-Leibler, poiché le ottimizzazioni sono equivalenti:
![]()
Quando si calcolano i gradienti rispetto a q (la distribuzione di Student) si ottengono gli stessi gradienti. Questo ci permette di sfruttare l’implementazione di PyTorch per un calcolo più veloce:
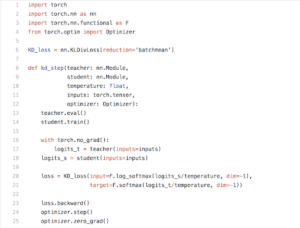
A Knowledge distillation training step in PyTorch. Copy the gist from here.
Utilizzando il segnale dell’insegnante, siamo in grado di addestrare un modello linguistico più piccolo, che chiamiamo DistilBERT, dalla supervisione di BERT 👨👦 (abbiamo utilizzato la versione inglese bert-base-uncased di BERT).
Seguendo Hinton et al., la perdita di addestramento è una combinazione lineare della perdita di distillazione e della perdita di modellazione del linguaggio mascherato. Il nostro studente è una versione ridotta di BERT in cui abbiamo rimosso le incorporazioni di tipo token e il pooler (utilizzato per il successivo compito di classificazione delle frasi) e abbiamo mantenuto identico il resto dell’architettura, riducendo il numero di strati di un fattore due.
Complessivamente, il nostro modello distillato, DistilBERT, ha circa la metà del numero totale di parametri di BERT base e mantiene il 95% delle prestazioni di BERT nel benchmark di comprensione del linguaggio GLUE.
❓Nota 1 – Perché non ridurre anche la dimensione nascosta?
Ridurla da 768 a 512 ridurrebbe il numero totale di parametri di ~2. Tuttavia, nei framework moderni, la maggior parte delle operazioni è altamente ottimizzata e le variazioni sull’ultima dimensione del tensore (dimensione nascosta) hanno un impatto minimo sulla maggior parte delle operazioni utilizzate nell’architettura di Transformer (strati lineari e normalizzazione degli strati). Nei nostri esperimenti, il numero di strati è stato il fattore determinante per il tempo di inferenza, più della dimensione nascosta.
Una dimensione minore non implica necessariamente una maggiore velocità…
❓Nota 2 – Alcuni lavori sulla distillazione, come Tang et al. utilizzano la distanza L2 come perdita di distillazione direttamente sui compiti a valle.
I nostri primi esperimenti hanno suggerito che la perdita di entropia incrociata porta a prestazioni significativamente migliori nel nostro caso. Abbiamo ipotizzato che in una configurazione di modellazione linguistica, lo spazio di output (vocabolario) sia significativamente più grande della dimensione dello spazio di output del compito a valle. I loghi possono quindi compensarsi a vicenda nella perdita L2.
L’addestramento di una sottorete non riguarda solo l’architettura. Si tratta anche di trovare l’inizializzazione giusta per far convergere la sotto-rete (si veda ad esempio l’ipotesi del biglietto della lotteria). Abbiamo quindi inizializzato il nostro studente, DistilBERT, a partire dal suo insegnante, BERT, eliminando uno strato su due, sfruttando la dimensione nascosta comune tra studente e insegnante.
Abbiamo anche utilizzato alcuni trucchi per l’addestramento tratti dal recente lavoro di RoBERTa, che ha mostrato come il modo in cui BERT viene addestrato sia cruciale per le sue prestazioni finali.
. Seguendo RoBERTa, abbiamo addestrato DistilBERT su lotti molto grandi, sfruttando l’accumulo di gradienti (fino a 4000 esempi per lotto), con mascheramento dinamico e rimuovendo l’obiettivo di predizione della frase successiva.
La nostra configurazione di addestramento è volontariamente limitata in termini di risorse. Abbiamo addestrato DistilBERT su otto GPU V100 da 16 GB per circa tre giorni e mezzo, utilizzando la concatenazione del Toronto Book Corpus e di Wikipedia inglese (gli stessi dati del BERT originale).
Il codice di DistilBERT è adattato in parte dal codice di Facebook XLM e in parte dalla nostra versione PyTorch di Google AI Bert ed è disponibile nella nostra libreria pytorch-transformers 👾 insieme a diverse versioni addestrate e messe a punto di DistilBert e al codice per riprodurre l’addestramento e la messa a punto.
Confrontiamo le prestazioni di DistilBERT sui set di sviluppo del benchmark GLUE con due modelli di base: BERT base (il maestro di DistilBERT) e un modello di base forte e non trasformatore della NYU: due BiLSTM in cima a ELMo. Utilizziamo la libreria jiant della NYU per le baseline ELMo e pytorch-transformers per la baseline BERT.
Come mostrato nella tabella seguente, le prestazioni di DistilBERT si confrontano favorevolmente con quelle delle linee di base, pur avendo rispettivamente circa la metà e un terzo del numero di parametri (maggiori informazioni in seguito). Tra i 9 compiti, DistilBERT è sempre alla pari o in miglioramento rispetto alla linea di base ELMo (fino a 14 punti di precisione su QNLI). DistilBERT si confronta sorprendentemente bene anche con BERT: siamo in grado di mantenere più del 95% delle prestazioni pur avendo il 40% di parametri in meno.
![]()
Confronto sui dev set del benchmark GLUE. Risultati di ELMo come riportati dagli autori. I risultati di BERT e DistilBERT sono le mediane di 5 esecuzioni con semi diversi.
In termini di tempo di inferenza, DistilBERT è più veloce del 60% e più piccolo di BERT e più veloce del 120% e più piccolo di ELMo+BiLSTM 🐎

Per analizzare ulteriormente il compromesso velocità/dimensioni di DistilBERT, nella tabella a sinistra confrontiamo il numero di parametri di ciascun modello e il tempo di inferenza necessario per eseguire un passaggio completo sul dev set STS-B su CPU (utilizzando una dimensione di batch pari a 1).
Studiamo ulteriormente l’uso di DistilBERT in compiti a valle sotto vincoli di inferenza efficienti. Utilizziamo il nostro modello linguistico compatto pre-addestrato, mettendo a punto un compito di classificazione. Un bel modo di mescolare il pre-training della distillazione e il transfer-learning!

Abbiamo scelto la IMDB Review Sentiment Classification, composta da 50.000 recensioni in inglese etichettate come positive o negative: 25.000 per l’addestramento e 25.000 per il test (con classi bilanciate). Abbiamo effettuato l’addestramento su un singolo K80 da 12 GB.
Per prima cosa, addestriamo bert-base-uncased sul nostro set di dati. Il nostro caro BERT 💋 raggiunge un’accuratezza del 93,46% (media di 6 esecuzioni) senza alcuna ricerca di iperparametri.
Successivamente addestriamo DistilBERT, utilizzando gli stessi iperparametri. Il modello compresso raggiunge un’accuratezza del 93,07% (media di 6 esecuzioni). Una differenza assoluta dello 0,4% nelle prestazioni per una riduzione del 60% della latenza e del 40% delle dimensioni 🏎!
❓Nota 3 – Come notato dalla comunità, è possibile raggiungere un punteggio comparabile o migliore nel benchmark IMDB con metodi più leggeri (dal punto di vista delle dimensioni e dell’inferenza) come ULMFiT. Vi invitiamo a fare un confronto con il vostro caso d’uso! In particolare, DistilBERT può fornire un limite inferiore ragionevole alle prestazioni di Bert, con il vantaggio di un addestramento più rapido.
Un’altra applicazione comune della PNL è la risposta alle domande. Abbiamo confrontato i risultati della versione bert-base-uncased di BERT con DistilBERT sul dataset SQuAD 1.1. Sul set di sviluppo, BERT raggiunge un punteggio F1 di 88,5 e un punteggio EM (Exact-match) di 81,2. Addestriamo DistilBERT sullo stesso insieme di iperparametri e raggiungiamo punteggi di 85,1 F1 e 76,5 EM, entro 3-5 punti dal BERT completo.
Abbiamo anche studiato la possibilità di aggiungere un’ulteriore fase di distillazione durante la fase di adattamento, perfezionando DistilBERT su SQuAD utilizzando il modello BERT perfezionato come insegnante con una perdita di distillazione della conoscenza.
In questo caso, stiamo perfezionando la distillazione di un modello di risposta alle domande in un modello linguistico precedentemente pre-addestrato con la distillazione della conoscenza! Che molti insegnanti e studenti🎓
In questo caso, siamo riusciti a raggiungere prestazioni interessanti date le dimensioni della rete: 86,2 F1 e 78,1 EM, cioè entro 3 punti dal modello completo!
Anche altri lavori hanno cercato di accelerare i modelli di risposta alle domande. In particolare, Debajyoti Chatterjee ha caricato su arXiv un interessante lavoro che segue un metodo simile per la fase di adattamento su SQuAD (inizializzando uno studente dal suo insegnante e addestrando un modello di risposta alle domande tramite distillazione). I suoi esperimenti presentano prestazioni relative simili rispetto a BERT (base uncased). La differenza principale con il nostro lavoro è che noi pre-addestriamo DistilBERT con un obiettivo generale (Masked Language Modeling) per ottenere un modello che può essere utilizzato per il transfer-learning su un’ampia gamma di compiti attraverso la messa a punto (GLUE, SQuAD, classificazione…).
