Articolo in lingua originale di Widhar Dwiatmoko

Come tutti sanno, la California è uno degli Stati più famosi degli USA. La California ha molti punti di riferimento da visitare, come la famosa Hollywood, il Golden Gate Bridge, la Silicon Valley e molti altri. Pertanto, ci sono sempre persone provenienti da altri stati o dall’estero che si trasferiscono in California per lavoro, istruzione, vacanze, ecc. Con un traffico così elevato di persone che arrivano in California, aumenta anche la domanda di case. Soprattutto le persone provenienti dall’estero che conoscono poco la California, avranno difficoltà a trovare l’opzione migliore per la casa. Ho quindi cercato di creare un modello di machine learning per aiutare l’utente finale a scegliere la casa migliore in base ad alcuni attributi.
Diagramma di flusso del pre-processing e EDA
ANALISI UNIVARIATA
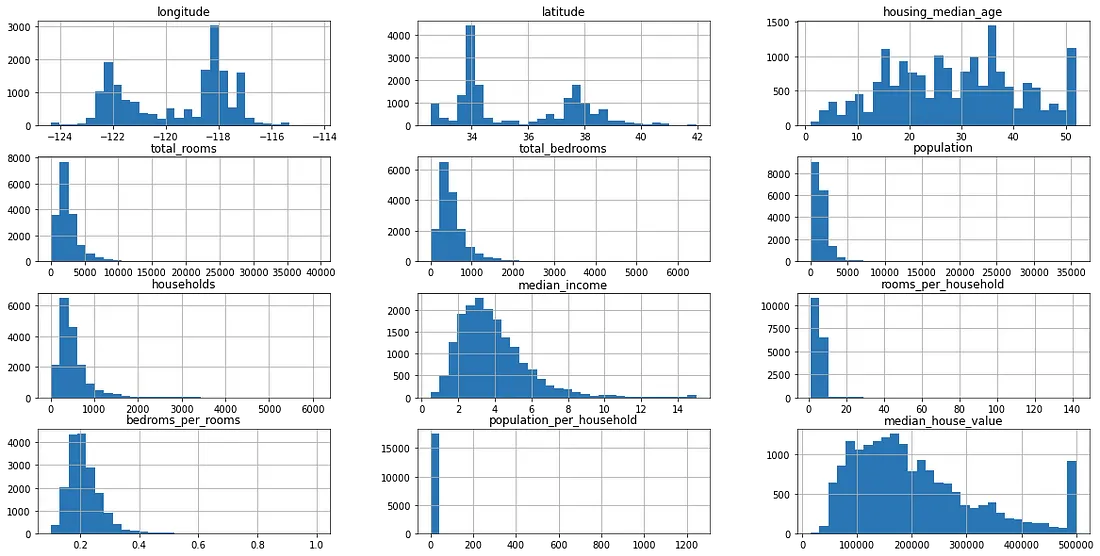
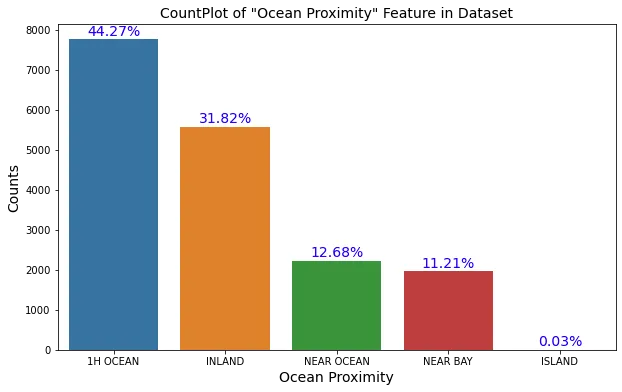

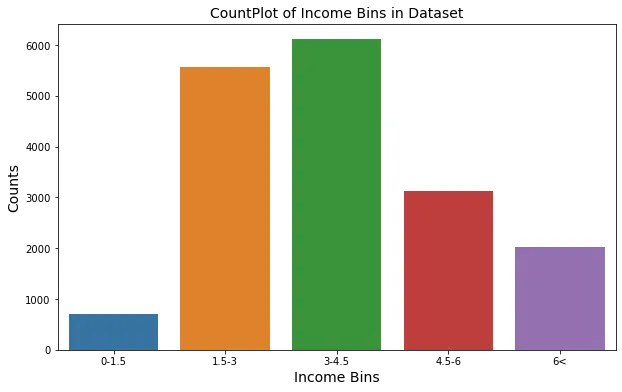
Sembra che la colonna (<1H ocean) rappresenti circa la metà del set di dati e che i dati siano distorti verso questa categoria; si può pensare di dividere i dati in base a questa colonna usando il metodo stratificato se si scopre che questa colonna è molto importante, ne parleremo più avanti. Sembra che la distribuzione della maggior parte delle caratteristiche sia skewed verso destra (distribuzione esponenziale) ed è noto che la migliore distribuzione da passare al modello è la distribuzione normale. Andremo avanti con queste caratteristiche per sapere come trattare queste distribuzioni skewed più tardi. Inoltre, la maggior parte della feature house_value si trova tra i 100k e i 200k. La maggior parte del median_income è tra 3 e 4.5. Qualcuno potrebbe cambiare idea e dividere il dataset utilizzando il metodo stratificato in base alla caratteristica più importante che è median_income. Tuttavia, questa feature è numerica, si potrebbe quindi utilizzare income_bins come riferimento per il metodo stratificato che richiede feature categoriche e non numeriche.
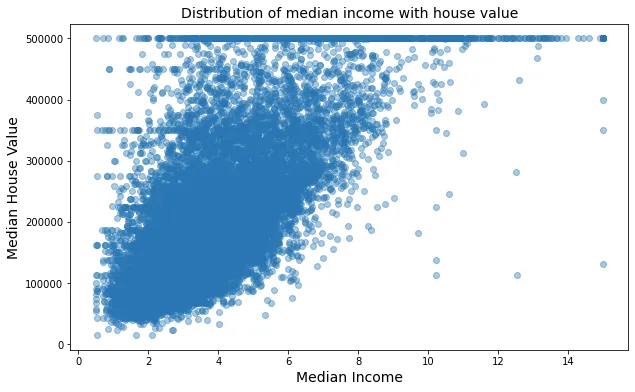
ANALISI BIVARIATA
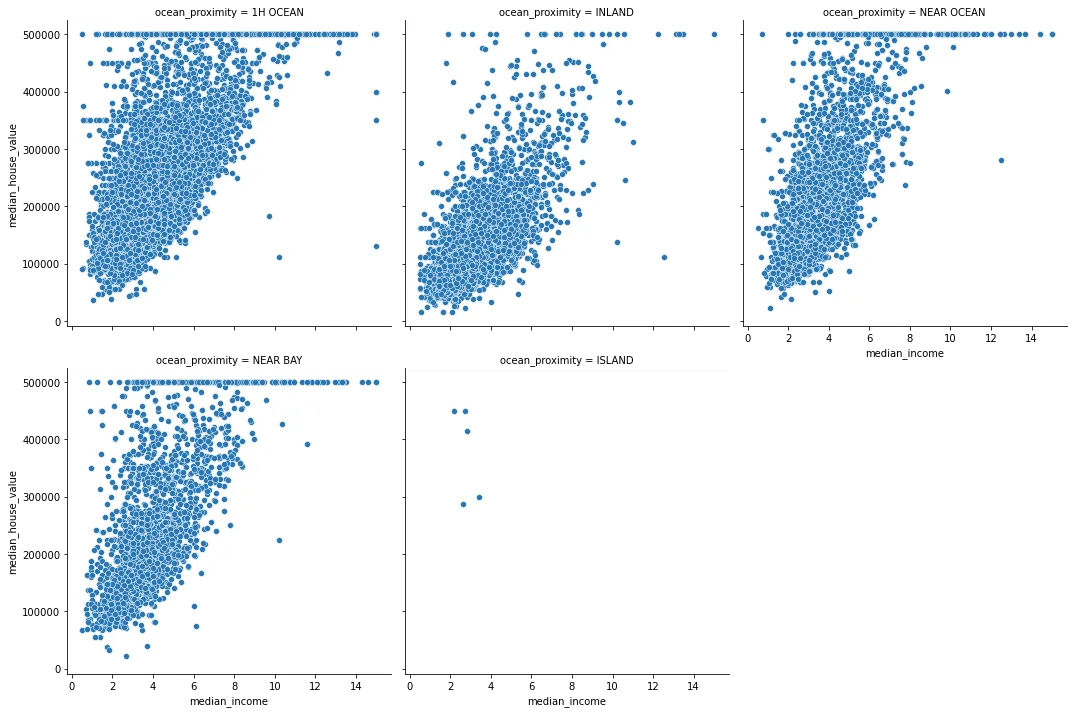
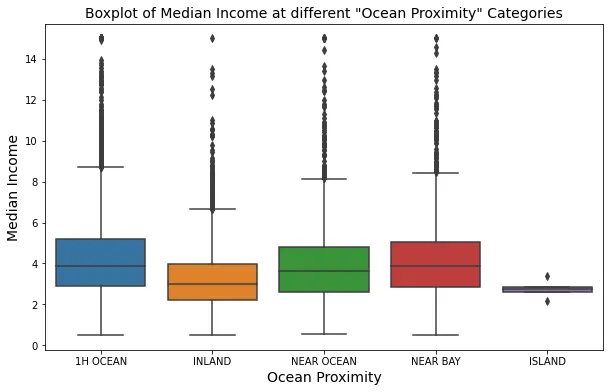
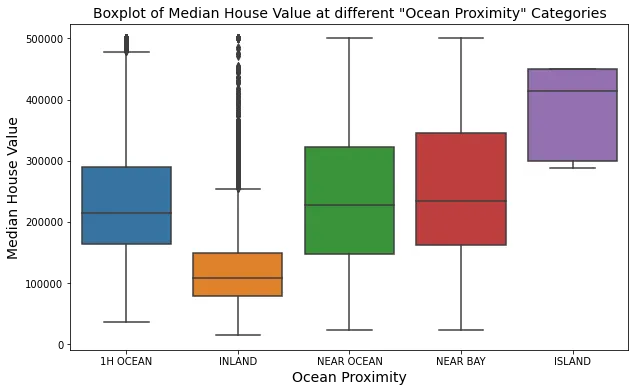
La distribuzione di median_income è quasi la stessa in tutte le categorie ocean_proximity. Tuttavia median_income e median_house per ISLAND risultano diversi.
ANALISI MULTIVARIATA
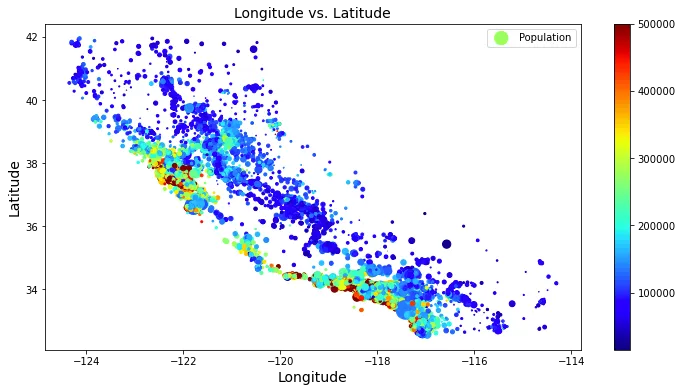
I prezzi sono più alti vicino all’oceano che in altre zone, inoltre queste aree hanno anche una popolazione più alta.
Dopo aver svolto EDA, otteniamo informazioni base sui nostri dati da cui possiamo partire. Ora è tempo di elaborare i dati. Per questo dataset controllo i valori nulli, gli outliers e la correlazione tra le features. Dopo aver svolto questi passaggi, utilizzo i dati puliti per elaborarli con la feature engineering.
Diagramma di flusso della feature engineering
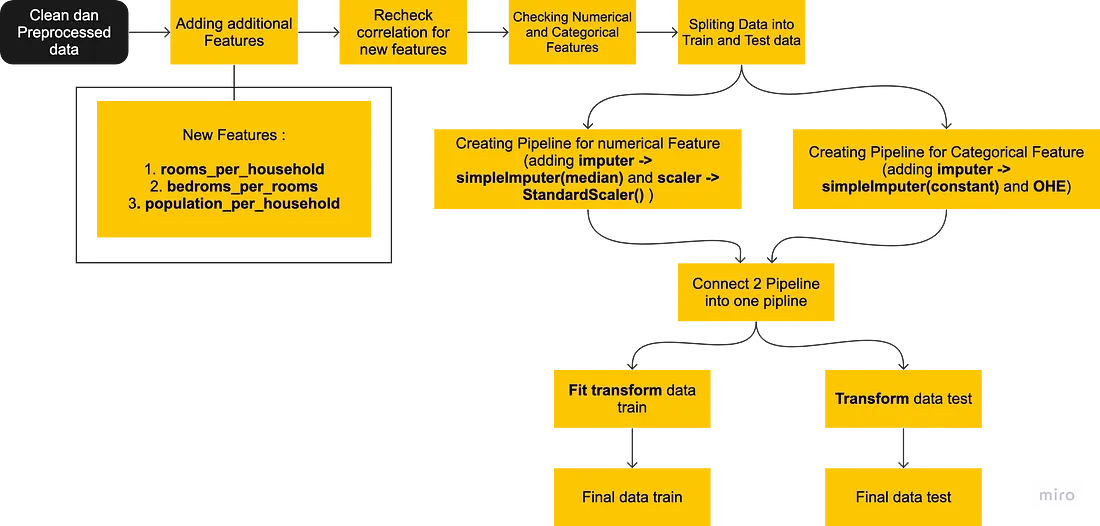
Dopo aver pulito e processato i dati è tempo di proseguire con la feature engineering. In questo caso creo 3 features aggiuntive: rooms_per_household, bedrooms_per_rooms, population_per_household. La ragione per cui creo queste 3 nuove features p che il dataset è considerato vecchio, perciò ho necessità di attribuirgli più valore e dettagli riguardo le features in modo che possano essere relazionate alla situazione attuale.
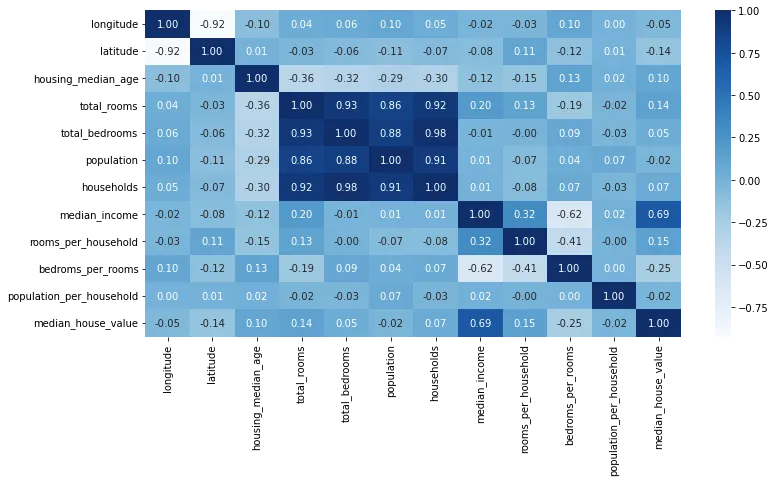
Dalla correlazione si evince che la nuova feature che ho aggiunto mostra una correlazione positiva. Dopo aver preso confidenza con il set di dati, è giunto il momento di dividere il set di dati in Train e Test.
Dopo aver diviso i dati in training e test, ho creato 2 pipeline per scalare ed imputare i dati:
- Pipeline categorica (SimpleImputer con costante, OHE come scaler)
- Pipeline numeirca (Simpleimputer con mediana, Standardscaler
Dopo aver creato le due pipeline possiamo unirle in una unica per trasformare i dati del train e del test set. Per i dati del traning utilizzo fit_transform mentre per quelli del test utilizzo transform. Termina qui la fase di feature engineering, possiamo ora utilizzare il set di training e di test per addestrare e testare il modello.
Diagramma di flusso per il modelling e deployment
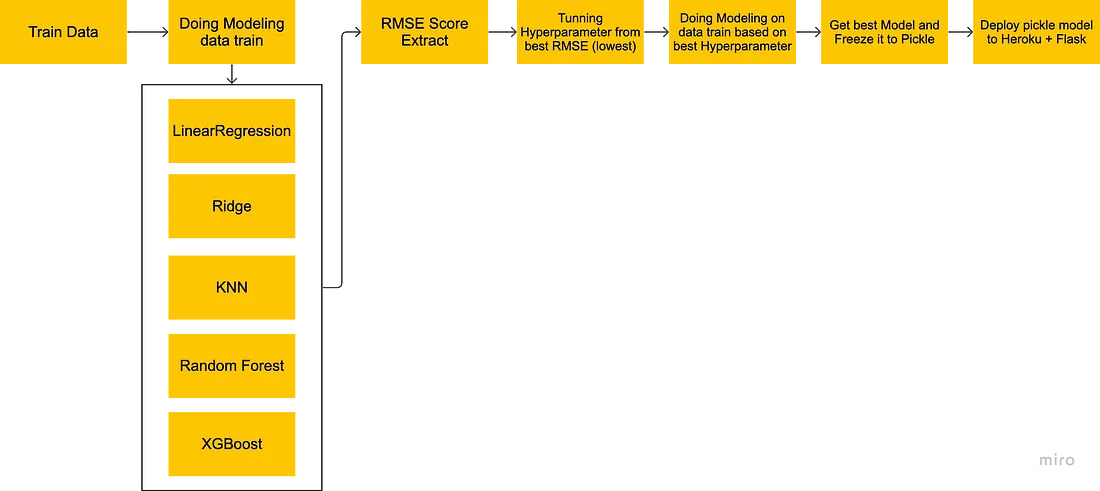
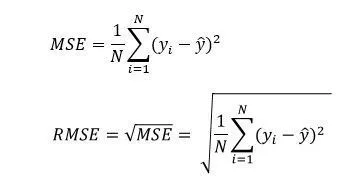
Per la modellazione, ho deciso di utilizzare l’RMSE per vedere le prestazioni del modello per tutti i modelli di machine learning che ho addestrato. Un RMSE più basso indica che il modello di machine learning ha funzionato bene. Ho provato diversi modelli: Regressione lineare, Ridge, KNN, Random Forest e XGBoost. Per raggiungere il miglior risultato ho deciso di mantenere il modello XGBoost che inizialmente aveva un RMSE di 47588,5920 ridotto a 45884,9481 dopo aver regolato l’iperparametro.
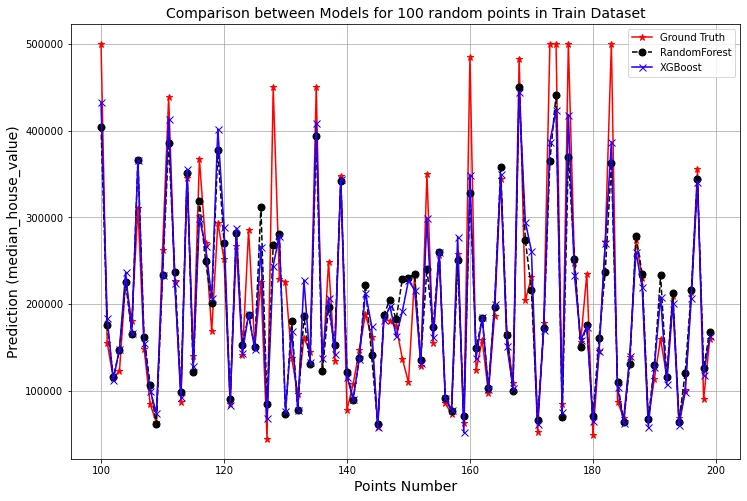
Il grafico mostra i dati attuali, le previsioni utilizzando Random Forest e quelle utilizzando XGBoost. Mostra che entrambi i modelli hanno prestazioni buone, anche se ad un certo punto XGBoost prende il sopravvento su Random Forest. Con il supporto dello score RMSE e il grafico viene mostrato che XGBoost abbia le performance migliori e più adatte ai dati attuali.
Per il deployment ho deciso di utilizzare Heroku come backend e Flask come Frontend. La ragione per cui scelgo questi due riguarda il mio background come sviluppatore di APP. Ho lavorato in un team di sviluppo di app web. Nella maggior parte dei casi ho utilizzato HTML combinato con Flask per costruire il frontend. Ecco come appaiono le API dal server:
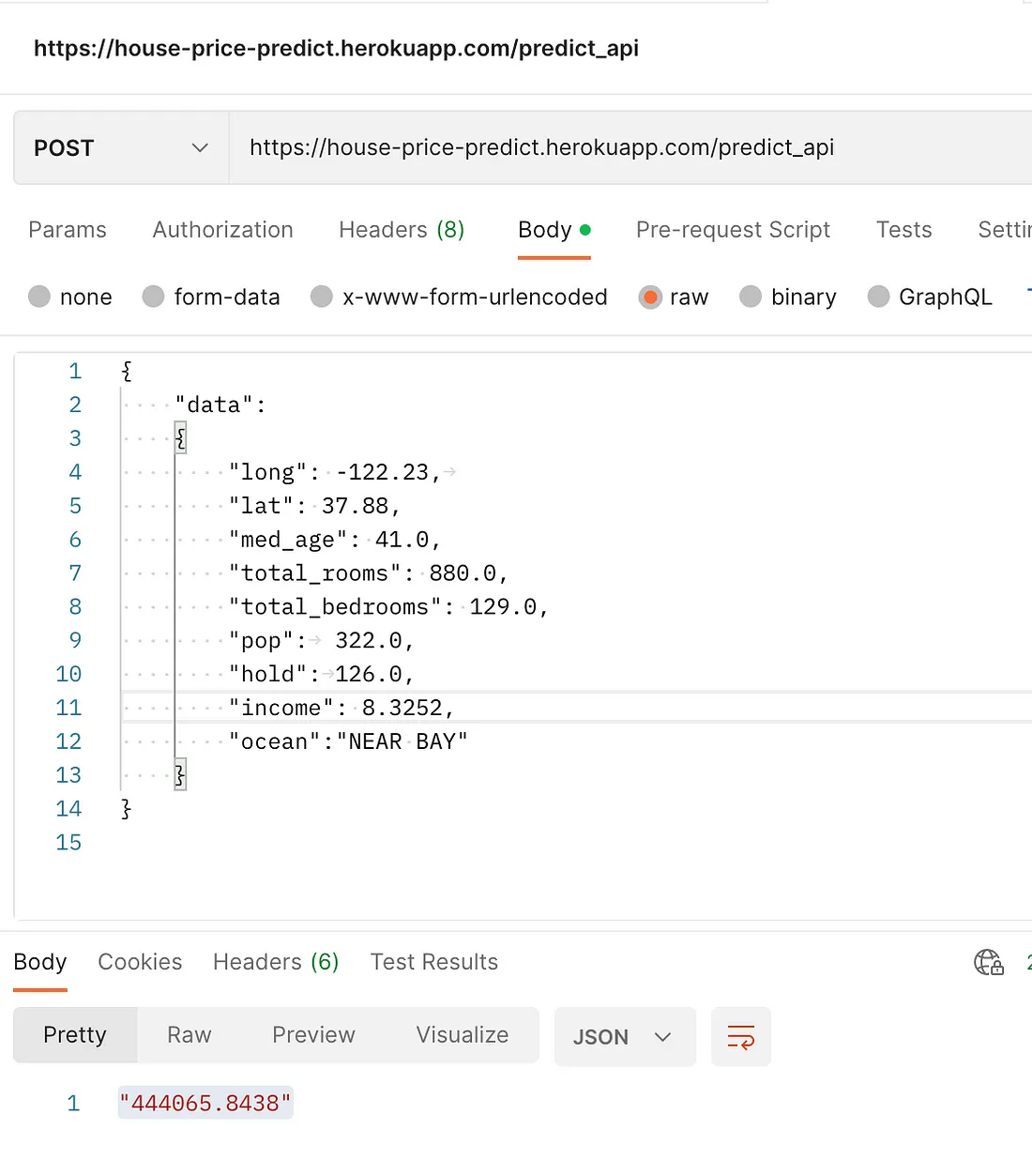
Se volete visitare la versionee live dell’API che ha già una UI frontend: https://house-price-predict.herokuapp.com
