Articolo in lingua originale di Kirill Dubovikov
In questo post voglio esaminare alcune delle somiglianze e differenze chiave tra due framework popolari di deep learning: Pytorch e Tensorflow. Perché questi due e non altri? Esistono molti frameework per il deep learning e molti di questi sono strumenti validi, ho scelto questi due solo perché ero interessato a confrontarli in modo specifico.

TensorFlow è sviluppato da Google Brain e utilizzato attivamente da Google sia per la ricerca che per la produzione. Il suo predecessore closed-source si chiama DistBelief.
PyTorch è un cugino del framework Torch basato su lua, sviluppato e utilizzato da Facebook. Tuttavia, PyTorch non è un semplice insieme di wrapper per supportare un linguaggio popolare, ma è stato riscritto e adattato per essere veloce e per dare l’impressione di essere nativo.
Il modo migliore per confrontare due framework è scrivere codice con entrambi. Ho scritto un notebook jupyter per questo post e potete trovarlo qui. Tutto il codice sarà fornito anche nel post.
Per prima cosa scriviamo in entrambi i framework il codice di un semplice approssimatore per la seguente funzione:
![]()
Proveremo a trovare il parametro non-noto phi dato un campione di dati x e una funzione f(x). Certo, l’uso della discesa stocastica del gradiente per questo è eccessivo e la soluzione analitica può essere trovata facilmente, ma questo problema servirà al nostro scopo come semplice esempio.
Risolviamolo prima con Pytorch:
import torch
from torch.autograd import Variable
import numpy as np
def rmse(y, y_hat):
"""Compute root mean squared error"""
return torch.sqrt(torch.mean((y - y_hat).pow(2).sum()))
def forward(x, e):
"""Forward pass for our fuction"""
return x.pow(e.repeat(x.size(0)))
# Let's define some settings
n = 100 # number of examples
learning_rate = 5e-6
target_exp = 2.0 # real value of the exponent will try to find
# Model definition
x = Variable(torch.rand(n) * 10, requires_grad=False)
# Model parameter and it's true value
exp = Variable(torch.FloatTensor([target_exp]), requires_grad=False)
exp_hat = Variable(torch.FloatTensor([4]), requires_grad=True) # just some starting value, could be random as well
y = forward(x, exp)
# a couple of buffers to hold parameter and loss history
loss_history = []
exp_history = []
# Training loop
for i in range(0, 200):
print("Iteration %d" % i)
# Compute current estimate
y_hat = forward(x, exp_hat)
# Calculate loss function
loss = rmse(y, y_hat)
# Do some recordings for plots
loss_history.append(loss.data[0])
exp_history.append(y_hat.data[0])
# Compute gradients
loss.backward()
print("loss = %s" % loss.data[0])
print("exp = %s" % exp_hat.data[0])
# Update model parameters
exp_hat.data -= learning_rate * exp_hat.grad.data
exp_hat.grad.data.zero_()
Se avete un po’ di esperienza con i framework di deep learning, avrete notato che stiamo implementando la discesa del gradiente a mano. Non è molto comodo, eh? Fortunatamente, PyTorch dispone del modulo optimize, che contiene le implementazioni degli algoritmi di ottimizzazione più diffusi, come RMSProp o Adam. Utilizzeremo SGD con momentum.
import torch
from torch.autograd import Variable
import numpy as np
def rmse(y, y_hat):
"""Compute root mean squared error"""
return torch.sqrt(torch.mean((y - y_hat).pow(2)))
def forward(x, e):
"""Forward pass for our fuction"""
return x.pow(e.repeat(x.size(0)))
# Let's define some settings
n = 1000 # number of examples
learning_rate = 5e-10
# Model definition
x = Variable(torch.rand(n) * 10, requires_grad=False)
y = forward(x, exp)
# Model parameters
exp = Variable(torch.FloatTensor([2.0]), requires_grad=False)
exp_hat = Variable(torch.FloatTensor([4]), requires_grad=True)
# Optimizer (NEW)
opt = torch.optim.SGD([exp_hat], lr=learning_rate, momentum=0.9)
loss_history = []
exp_history = []
# Training loop
for i in range(0, 10000):
opt.zero_grad()
print("Iteration %d" % i)
# Compute current estimate
y_hat = forward(x, exp_hat)
# Calculate loss function
loss = rmse(y, y_hat)
# Do some recordings for plots
loss_history.append(loss.data[0])
exp_history.append(y_hat.data[0])
# Update model parameters
loss.backward()
opt.step()
print("loss = %s" % loss.data[0])
print("exp = %s" % exp_hat.data[0])
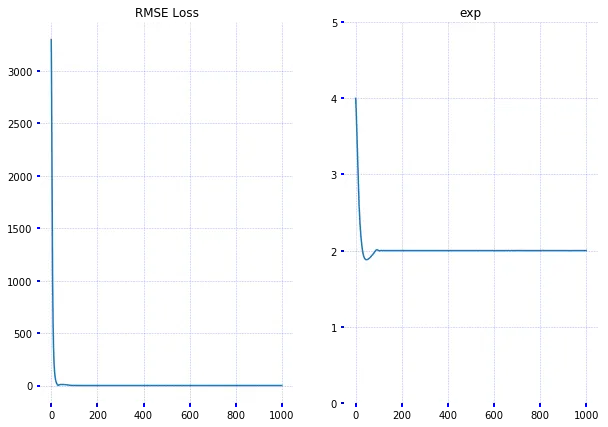
Come si può vedere, abbiamo dedotto rapidamente il vero esponente dai dati di addestramento. E ora proseguiamo con TensorFlow:
import tensorflow as tf
def rmse(y, y_hat):
"""Compute root mean squared error"""
return tf.sqrt(tf.reduce_mean(tf.square((y - y_hat))))
def forward(x, e):
"""Forward pass for our fuction"""
# tensorflow has automatic broadcasting
# so we do not need to reshape e manually
return tf.pow(x, e)
n = 100 # number of examples
learning_rate = 5e-6
# Placeholders for data
x = tf.placeholder(tf.float32)
y = tf.placeholder(tf.float32)
# Model parameters
exp = tf.constant(2.0)
exp_hat = tf.Variable(4.0, name='exp_hat')
# Model definition
y_hat = forward(x, exp_hat)
# Optimizer
loss = rmse(y, y_hat)
opt = tf.train.GradientDescentOptimizer(learning_rate)
# We will run this operation to perform a single training step,
# e.g. opt.step() in Pytorch.
# Execution of this operation will also update model parameters
train_op = opt.minimize(loss)
# Let's generate some training data
x_train = np.random.rand(n) + 10
y_train = x_train ** 2
loss_history = []
exp_history = []
# First, we need to create a Tensorflow session object
with tf.Session() as sess:
# Initialize all defined variables
tf.global_variables_initializer().run()
# Training loop
for i in range(0, 500):
print("Iteration %d" % i)
# Run a single trainig step
curr_loss, curr_exp, _ = sess.run([loss, exp_hat, train_op], feed_dict={x: x_train, y: y_train})
print("loss = %s" % curr_loss)
print("exp = %s" % curr_exp)
# Do some recordings for plots
loss_history.append(curr_loss)
exp_history.append(curr_exp)

Come si può vedere, anche l’implementazione in TensorFlow funziona (sorprendentemente 🙃). Ci sono volute più iterazioni per recuperare l’esponente, ma sono sicuro che la causa sia da ricercare nel fatto che non ho giocherellato abbastanza con i parametri dell’ottimizzatore per ottenere risultati comparabili.
Ora siamo pronti a esplorare alcune differenze.
Poiché il grafico di calcolo in PyTorch è definito in fase di esecuzione, è possibile utilizzare i nostri strumenti di debug preferiti di Python, come pdb, ipdb, il debugger di PyCharm o il caro e vecchio print.
Questo non è il caso di TensorFlow. È possibile utilizzare uno strumento speciale chiamato tfdbg che consente di valutare le espressioni di tensorflow in fase di esecuzione e di esplorare tutti i tensori e le operazioni nell’ambito della sessione. Naturalmente, non sarà possibile eseguire il debug di alcun codice python con questo strumento, quindi sarà necessario utilizzare pdb separatamente.

