Articolo originale in lingua inglese di Rohit Gandhi
Computer vision è un campo interdisciplinare che ha guadagnato enormi quantità di trazione negli ultimi anni (dal CNN) e auto senza guida hanno preso il centro della scena. Un’altra parte integrante della computer vision è il rilevamento di oggetti. Gli aiuti di rilevazione dell’oggetto nella stima di posizione, nella rilevazione del veicolo, nella sorveglianza ecc. La differenza fra gli algoritmi di rilevazione dell’oggetto e gli algoritmi di classificazione è che negli algoritmi di rilevazione, proviamo a disegnare una scatola di delimitazione intorno all’oggetto di interesse per individuarlo all’interno dell’immagine. Inoltre, potrebbe non essere necessario disegnare un solo riquadro di delimitazione in un caso di rilevamento di oggetti, potrebbero esserci molte caselle di delimitazione che rappresentano diversi oggetti di interesse all’interno dell’immagine e non si saprebbe quanti in anticipo.


Il motivo principale per cui non si può procedere con questo problema costruendo una rete convoluzionale standard seguita da un livello completamente connesso è che, la lunghezza del livello di uscita è variabile – non costante, questo perché il numero di occorrenze degli oggetti di interesse non è fisso. Un approccio ingenuo per risolvere questo problema sarebbe quello di prendere diverse regioni di interesse dall’immagine, e utilizzare una CNN per classificare la presenza dell’oggetto all’interno di quella regione. Il problema con questo approccio è che gli oggetti di interesse potrebbero avere diverse posizioni spaziali all’interno dell’immagine e diversi rapporti di aspetto. Quindi, si dovrebbe selezionare un numero enorme di regioni e questo potrebbe computazionalmente esplodere. Pertanto, algoritmi come R-CNN, YOLO ecc sono stati sviluppati per trovare queste occorrenze e trovarli velocemente.
Per aggirare il problema della selezione di un numero enorme di regioni, Ross Girshick et al, ha proposto un metodo in cui usiamo la ricerca selettiva per estrarre solo 2000 regioni dall’immagine e le ha chiamate proposte regionali. Pertanto, ora, invece di cercare di classificare un numero enorme di regioni, si può semplicemente lavorare con 2000 regioni. Queste 2000 proposte di regione sono generate usando l’algoritmo di ricerca selettiva che è scritto sotto.
Selective Search: 1. Generate initial sub-segmentation, we generate many candidate regions 2. Use greedy algorithm to recursively combine similar regions into larger ones 3. Use the generated regions to produce the final candidate region proposals

Per saperne di più sull’algoritmo di ricerca selettiva, segui questo link. Queste 2000 proposte di regione candidate sono deformate in un quadrato e alimentate in una rete neurale convoluzionale che produce un vettore 4096-dimensional della caratteristica come uscita. La CNN funge da estrattore di caratteristiche e lo strato denso di output consiste delle caratteristiche estratte dall’immagine e le caratteristiche estratte sono inserite in una SVM per classificare la presenza dell’oggetto all’interno di quella proposta di regione candidata. Oltre a prevedere la presenza di un oggetto all’interno delle proposte di regione, l’algoritmo prevede anche quattro valori che sono valori offset per aumentare la precisione del riquadro di delimitazione. Per esempio, data una proposta regionale, l’algoritmo avrebbe predetto la presenza di una persona, ma il volto di quella persona all’interno di quella proposta regione avrebbe potuto essere tagliato a metà. Pertanto, i valori di offset aiutano a regolare il riquadro di delimitazione della proposta di regione

Problemi con la R-CNN
- Ci vuole ancora una quantità enorme di tempo per formare la rete, come si dovrebbe classificare 2000 proposte di regione per immagine.
- Non può essere implementato in tempo reale in quanto richiede circa 47 secondi per ogni immagine di prova.
- L’algoritmo di ricerca selettiva è un algoritmo fisso. Pertanto, in quella fase non avviene alcun apprendimento. Ciò potrebbe portare alla generazione di proposte di regioni candidate inadeguate.

Lo stesso autore del precedente articolo (R-CNN) ha risolto alcuni degli inconvenienti di R-CNN per costruire un algoritmo di rilevamento oggetti più veloce ed è stato chiamato Fast R-CNN. L’approccio è simile all’algoritmo R-CNN. Ma, invece di alimentare le proposte regionali per la CNN, alimentiamo l’immagine di input per la CNN per generare una mappa caratteristica convoluzionale. Dalla mappa delle caratteristiche convoluzionali, identifichiamo la regione delle proposte e le deformamo in quadrati e utilizzando uno strato di pooling Roi le rimoduliamo in una dimensione fissa in modo che possa essere alimentato in uno strato completamente connesso. Dal vettore della funzione Roi, usiamo un livello Softmax per prevedere la classe della regione proposta e anche i valori di offset per il riquadro di delimitazione.
Il motivo per cui “Fast R-CNN” è più veloce di R-CNN è perché non è necessario alimentare 2000 proposte regionali alla rete neurale convoluzionale ogni volta. Invece, l’operazione di convoluzione viene eseguita solo una volta per immagine e da essa viene generata una mappa caratteristica…
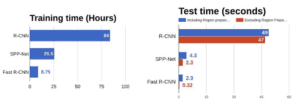
Dai grafici precedenti, si può dedurre che Fast R-CNN è significativamente più veloce nelle sessioni di allenamento e test su R-CNN. Quando si guardano le prestazioni di Fast R-CNN durante il tempo di test, comprese le proposte di regione rallenta significativamente l’algoritmo rispetto a non utilizzare le proposte di regione. Pertanto, le proposte regionali diventano strozzature nell’algoritmo Fast R-CNN che influenzano le sue prestazioni.

Entrambi gli algoritmi di cui sopra(R-CNN e Fast R-CNN) utilizzano la ricerca selettiva per scoprire le proposte regionali. La ricerca selettiva è un processo lento e lungo che influisce sulle prestazioni della rete. Pertanto, Shaoqing Ren et al, si avvicinò con un algoritmo di rilevamento oggetto che elimina l’algoritmo di ricerca selettiva e permette alla rete di imparare le proposte della regione.
Simile a Fast R-CNN, l’immagine è fornita come input per una rete convoluzionale che fornisce una mappa delle caratteristiche convoluzionali. Invece di utilizzare l’algoritmo di ricerca selettiva sulla mappa caratteristica per identificare le proposte di regione, una rete separata viene utilizzata per prevedere le proposte di regione. Le proposte di regione previste vengono poi rimodellate utilizzando uno strato di pooling Roi che viene poi utilizzato per classificare l’immagine all’interno della regione proposta e prevedere i valori di offset per i riquadri di delimitazione.
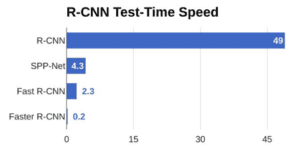
Dal grafico sopra, potete vedere che Faster R-CNN è molto più veloce dei suoi predecessori. Pertanto, può anche essere utilizzato per il rilevamento di oggetti in tempo reale.
Tutti i precedenti algoritmi di rilevamento degli oggetti usano regioni per localizzare l’oggetto all’interno dell’immagine. La rete non guarda l’immagine completa. Invece, parti dell’immagine che hanno alte probabilità di contenere l’oggetto. YOLO o You Only Look Once è un algoritmo di rilevamento oggetti molto diverso dagli algoritmi basati sulla regione visti sopra. In YOLO una singola rete convoluzionale prevede le caselle di delimitazione e le probabilità di classe per queste caselle.

Come funziona YOLO è che prendiamo un’immagine e la dividiamo in una griglia SxS, all’interno di ciascuna griglia che prendiamo m caselle di delimitazione. Per ogni riquadro di delimitazione, la rete fornisce valori di probabilità e offset di classe per il riquadro di delimitazione. Le caselle di delimitazione che hanno la probabilità di classe sopra un valore di soglia sono selezionate e utilizzate per localizzare l’oggetto all’interno dell’immagine.
YOLO è ordini di grandezza più veloce (45 fotogrammi al secondo) di altri algoritmi di rilevamento degli oggetti. La limitazione dell’algoritmo YOLO è che lotta con piccoli oggetti all’interno dell’immagine, per esempio potrebbe avere difficoltà a rilevare uno stormo di uccelli. Ciò è dovuto ai vincoli spaziali dell’algoritmo.
