Articolo originale in lingua inglese di Kerem Turgutlu
Qui ancora scrivendo al mio 6 mesi fa sé…
In questo post mi concentrerò principalmente sulla segmentazione semantica, un compito di classificazione pixel-wise e un particolare algoritmo per esso. Fornirò una panoramica di alcuni dei casi che ho avuto e su cui ho lavorato ultimamente.
Per definizione, la segmentazione semantica è la partizione di un’immagine in parti coerenti. Ad esempio, classificare ogni pixel che appartiene a una persona, un’auto, un albero o qualsiasi altra entità nel nostro set di dati.
Segmentazione semantica vs. Segmentazione di esempio
La segmentazione semantica è relativamente più semplice rispetto al suo fratello maggiore, la segmentazione delle istanze.
Ad esempio la segmentazione, il nostro obiettivo non è solo quello di fare previsioni pixel-wise per ogni persona, auto o albero, ma anche di identificare ogni entità separatamente come persona 1, persona 2, albero 1, albero 2, auto 1, auto 2, auto 3 e così via. L’algoritmo allo stato attuale dell’arte per esempio la segmentazione è Mask-RCNN: un approccio a due stadi con più sottoreti funzionanti together: RPN (Region Proposal Network), FPN (Feature Pyramid Network) e FCN (Fully Convolutional Network) [5, 6, 7, 8].


La Data Science Bowl 2018 si è appena conclusa e ho imparato molto. Forse la lezione più importante che ho imparato è stata, anche con l’apprendimento profondo, una tecnica più automatizzata rispetto ai tradizionali ML, pre e post elaborazione potrebbe essere cruciale per ottenere buoni risultati. Queste sono competenze importanti per un professionista per ottenere e definiscono il modo in cui si struttura e modello il problema.
Non passerò in rassegna ogni piccolo dettaglio e spiegazione su questo particolare concorso in quanto vi è grande quantità di discussione e spiegazione sia sul compito stesso e dei metodi utilizzati in tutto il concorso qui. Tuttavia menzionerò brevemente la soluzione vincente in quanto è legata alle fondamenta di questo post. [13]
Data Science Bowl 2018 proprio come altre Data Science Bowl in passato è stato organizzato da Booz Allen Foundation. Il compito di quest’anno era quello di identificare i nuclei di cellule in una data immagine di microscopia e di fornire maschere per ogni nucleo in modo indipendente.
Ora, prenditi un momento o due per indovinare quale tipo di segmentazione richiede questo compito; semantico o istanza ?
Qui è un’immagine mascherata del campione ed è immagine grezza di microscopia.
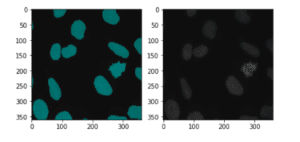
Anche se può sembrare un compito di segmentazione semantica in un primo momento, il compito qui è la segmentazione di istanza. Dobbiamo trattare ogni nucleo nell’immagine in modo indipendente e identificarli come nuclei 1, nuclei 2, nuclei 3, … simile all’esempio che abbiamo avuto per auto 1, auto 2, persona 1 e così via. Forse la motivazione per questo compito è quello di tracciare le dimensioni, i conteggi e le caratteristiche dei nuclei da un campione della cella col tempo. È molto importante automatizzare questo processo di monitoraggio e accelerare ulteriormente la sperimentazione dell’esecuzione di diversi trattamenti per la cura di varie malattie.
Ora, potresti pensare che se questo articolo riguarda la segmentazione semantica e se Data Science Bowl 2018 è un esempio di attività di segmentazione delle istanze, allora perché continuo a parlare di questa particolare competizione. Se stai pensando a questo, allora hai sicuramente ragione e in effetti l’obiettivo finale di questa competizione non era un esempio di segmentazione semantica. Ma come andremo avanti vedrete come si può effettivamente trasformare questo problema di segmentazione istanza in un compito di segmentazione semantica multiclasse. Questo è stato l’approccio che ho provato, ma non è riuscito nella pratica, ma anche si è rivelato essere la motivazione di alto livello per la soluzione vincente troppo.
Durante questo periodo di 3 mesi del concorso c’erano solo due modelli (o varianti di essi) che erano condivisi o almeno esplicitamente discussi in tutti i forum; Mask-RCNN e U-Net. Come ho accennato in precedenza Mask-RCNN è l’algoritmo all’avanguardia per il rilevamento di oggetti che rileva singoli oggetti e ne predice le maschere, come ad esempio la segmentazione. L’implementazione e la formazione di Mask-RCNN è più difficile poiché impiega un approccio di apprendimento in due fasi, in cui prima si ottimizza per un RPN (Region Proposal Network) e quindi si prevedono caselle di delimitazione, classi e maschere contemporaneamente.
D’altra parte U-Net è una rete molto popolare di encoder-decoder end-to-end per la segmentazione semantica [9]. È stato originariamente inventato e utilizzato per la prima volta per la segmentazione delle immagini biomediche, un compito molto simile che abbiamo avuto per Data Science Bowl. Non c’era nessun proiettile d’argento nella competizione, e nessuna di queste due architetture da sola senza post o pre-processing o modifiche minori nella progettazione architettonica hanno dimostrato di avere un punteggio top. Non ho avuto la possibilità di provare Mask-RCNN per questa competizione, così ho tenuto i miei esperimenti intorno a U-Net e ho imparato molto su di esso.
Inoltre, dal momento che il nostro argomento è la segmentazione semantica lascerò Mask-RCNN ad altri post del blog là fuori per spiegare. Ma se insisti ancora a provarli nelle tue applicazioni CV, ecco due repository Github popolari con implementazioni in Tensorflow e PyTorch. [10, 11]
Ora, possiamo continuare con U-Net e approfondire i suoi dettagli…
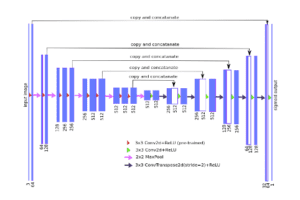
Ecco l’architettura per iniziare:
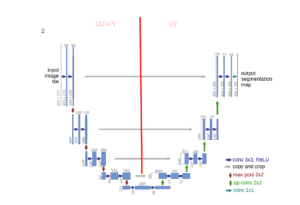
Per coloro che hanno familiarità con le reti neurali convoluzionali tradizionali, la prima parte (indicata come DOWN) dell’architettura sarà familiare. Questa prima parte viene richiamata o si potrebbe pensare che sia la parte encoder dove si applicano blocchi di convoluzione seguiti da un downsampling maxpool per codificare l’immagine di input in rappresentazioni di funzionalità a più livelli diversi.
La seconda parte della rete consiste in operazioni di upsample e concatenazione seguite da regolari operazioni di convoluzione. L’upsampling nei CNN può essere un nuovo concetto per alcuni dei lettori, ma l’idea è abbastanza semplice: stiamo espandendo le dimensioni delle funzionalità per soddisfare le stesse dimensioni con i corrispondenti blocchi di concatenazione da sinistra. Si possono vedere le frecce grigie e verdi, dove si concatenano due mappe caratteristiche insieme. Il principale contributo di U-Net in questo senso rispetto ad altre reti di segmentazione completamente convoluzionale è che, mentre il upsampling e andare più in profondità nella rete stiamo concatenando le caratteristiche di risoluzione più elevata dal basso con le caratteristiche upsampled al fine di localizzare meglio e imparare rappresentazioni con le seguenti convoluzioni. Poiché l’upsampling è un’operazione sparsa abbiamo bisogno di un buon precedente dalle fasi più iniziali per rappresentare meglio la localizzazione. Idea simile di combinare livelli corrispondenti è visto anche in FPN (Caratteristiche Reti piramidali). [7]
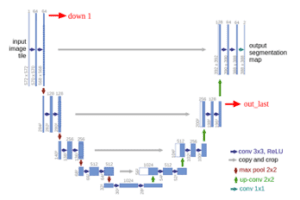
Possiamo definire un blocco di operazioni in giù parte come convoluzioni downsampling.
# a sample down block def make_conv_bn_relu(in_channels, out_channels, kernel_size=3, stride=1, padding=1): return [ nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=False), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True) ] self.down1 = nn.Sequential( *make_conv_bn_relu(in_channels, 64, kernel_size=3, stride=1, padding=1 ), *make_conv_bn_relu(64, 64, kernel_size=3, stride=1, padding=1 ), ) # convolutions followed by a maxpool down1 = self.down1(x) out1 = F.max_pool2d(down1, kernel_size=2, stride=2)
Allo stesso modo possiamo definire un blocco di operazioni nella parte superiore come convoluzioni di concatenazione upsampling.
# a sample up block def make_conv_bn_relu(in_channels, out_channels, kernel_size=3, stride=1, padding=1): return [ nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=False), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True) ] self.up4 = nn.Sequential( *make_conv_bn_relu(128,64, kernel_size=3, stride=1, padding=1 ), *make_conv_bn_relu(64,64, kernel_size=3, stride=1, padding=1 ) ) self.final_conv = nn.Conv2d(32, num_classes, kernel_size=1, stride=1, padding=0 ) # upsample out_last, concatenate with down1 and apply conv operations out = F.upsample(out_last, scale_factor=2, mode='bilinear') out = torch.cat([down1, out], 1) out = self.up4(out) # final 1x1 conv for predictions final_out = self.final_conv(out)
Ispezionando la figura più attentamente, si può notare che le dimensioni di uscita (388 x 388) non sono le stesse dell’ingresso originale (572 x 572). Se si desidera ottenere dimensioni coerenti, è possibile applicare convoluzioni riempite per mantenere le dimensioni coerenti tra i livelli di concatenazione, proprio come abbiamo fatto nel codice di esempio sopra.
Quando si parla di upsampling, ci si può imbattere in uno dei seguenti termini: convoluzione trasposta, upconvoluzione, deconvoluzione o upsamling. Molte persone, tra cui me e le documentazioni PyTorch, non amano il termine deconvoluzione, poiché durante la fase di upsampling stiamo effettivamente facendo operazioni di convoluzione regolari e non c’è nulla su di esso. Prima di andare oltre se non si ha familiarità con le operazioni di convoluzione di base e la loro aritmetica consiglio vivamente di visitare qui. [12]
Spiegherò i metodi di upsampling dal più semplice al più complesso. Ecco tre modi di sovracampionamento di un tensore 2D in PyTorch:
Questo è il modo più semplice per trovare i valori dei pixel mancanti quando si ridimensiona (traduce) un tensore in un tensore più grande, ad es. 2×2 a 4×4, 5×5 o 6×6.
Implementiamo questo algoritmo base di computer vision passo dopo passo usando Numpy:
from collections import Counter def nn_interpolate(A, new_size): """ Nearest Neighbor Interpolation, Step by Step """ # get sizes old_size = A.shape # calculate row and column ratios row_ratio, col_ratio = new_size[0]/old_size[0], new_size[1]/old_size[1] # define new pixel row position i new_row_positions = np.array(range(new_size[0]))+1 new_col_positions = np.array(range(new_size[1]))+1 # normalize new row and col positions by ratios new_row_positions = new_row_positions / row_ratio new_col_positions = new_col_positions / col_ratio # apply ceil to normalized new row and col positions new_row_positions = np.ceil(new_row_positions) new_col_positions = np.ceil(new_col_positions) # find how many times to repeat each element row_repeats = np.array(list(Counter(new_row_positions).values())) col_repeats = np.array(list(Counter(new_col_positions).values())) # perform column-wise interpolation on the columns of the matrix row_matrix = np.dstack([np.repeat(A[:, i], row_repeats) for i in range(old_size[1])])[0] # perform column-wise interpolation on the columns of the matrix nrow, ncol = row_matrix.shape final_matrix = np.stack([np.repeat(row_matrix[i, :], col_repeats) for i in range(nrow)]) return final_matrix def nn_interpolate(A, new_size): """Vectorized Nearest Neighbor Interpolation""" old_size = A.shape row_ratio, col_ratio = np.array(new_size)/np.array(old_size) # row wise interpolation row_idx = (np.ceil(range(1, 1 + int(old_size[0]*row_ratio))/row_ratio) - 1).astype(int) # column wise interpolation col_idx = (np.ceil(range(1, 1 + int(old_size[1]*col_ratio))/col_ratio) - 1).astype(int) final_matrix = A[:, row_idx][col_idx, :] return final_matrix
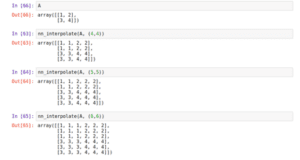
[PyTorch] F.upsample(…, mode = “nearest”)
>>> input = torch.arange(1, 5).view(1, 1, 2, 2) >>> input (0 ,0 ,.,.) = 1 2 3 4 [torch.FloatTensor of size (1,1,2,2)] >>> m = nn.Upsample(scale_factor=2, mode='nearest') >>> m(input) (0 ,0 ,.,.) = 1 1 2 2 1 1 2 2 3 3 4 4 3 3 4 4 [torch.FloatTensor of size (1,1,4,4)]
Nelle convoluzioni trasposte abbiamo pesi che impariamo attraverso la retropropagazione. Nei documenti che ho incontrato tutti questi metodi di upsampling per vari casi e anche in pratica si può cambiare la vostra architettura e provare tutti loro per vedere quale funziona meglio per il proprio problema. Personalmente preferisco le convoluzioni trasposte, dato che abbiamo più controllo su di essa, ma si può optare per l’interpolazione bilineare o il più vicino per semplicità.
[PyTorch] nn.ConvTranspose2D(…, stride=…, padding=…)

Credito va a https://github.com/vdumoulin/conv_arithmetic [12]
Se torniamo al nostro caso originale, Data Science Bowl, il principale svantaggio di utilizzare un approccio vaniglia U-Net nella competizione era la sovrapposizione dei nuclei. Come si vede nell’immagine qui sopra se create una maschera binaria e la usate come bersaglio, U-Net predirrà sicuramente qualcosa di simile a questo e avrete una maschera combinata per diversi nuclei che si sovrappongono o si trovano molto vicini l’uno all’altro.

Facendo riferimento al problema delle istanze sovrapposte, gli autori della carta U-Net hanno utilizzato l’entropia incrociata ponderata per enfatizzare l’apprendimento dei bordi delle cellule. Questo metodo li ha aiutati a separare le istanze sovrapposte. L’idea di base è di pesare di più i confini e di spingere la rete verso le lacune di apprendimento tra le istanze vicine.[9]

***(a) Immagine grezza (b) Ground Truth di colore diverso per ogni istanza (c) maschera generata di segmentazione (d) pixel-wise weight map
Un’altra soluzione a questo tipo di problema, un approccio che è stato utilizzato da molti concorrenti tra cui la soluzione vincente, è quello di convertire le maschere binarie in un target multiclasse. La cosa bella di U-Net è che è possibile strutturare la rete in uscita come molti canali come si desidera e rappresentare qualsiasi classe in qualsiasi canale utilizzando 1×1 convoluzione al livello finale.
Citando la soluzione vincente di Data Science Bowl:
2 canali maschere per reti con attivazione sigmoide i.e. (maschera – bordo, bordo) o 3 canali maschere per reti con attivazione Softmax i.e. (maschera – bordo, confine , 1 – maschera – bordo)
2 canali maschere complete i.e. (maschera, bordo)
Dopo aver fatto queste previsioni, gli algoritmi classici di elaborazione delle immagini come watershed possono essere utilizzati per il post-processing per segmentare ulteriormente i singoli nuclei. [14]

Questa è stata la prima gara ufficiale di computer vision che ho avuto il coraggio di partecipare a Kaggle ed è stato un Data Science Bowl. Anche se ho completato la competizione solo in cima 20% (che è considerato come un punteggio medio) ho sentito il piacere di partecipare a un Data Science Bowl e imparare le cose che non avrei mai potuto imparare se non stavo effettivamente partecipando e cercando da solo. L’apprendimento attivo è molto più fruttuoso di guardare o leggere approcci simili da fonti online.
Come un praticante di apprendimento profondo che ha appena iniziato a praticare mesi indietro con Fast.ai questo è stato un passo importante per me verso il mio viaggio senza fine ed è stato molto prezioso in termini di acquisire esperienza. Quindi, per coloro che si sentono intimiditi da sfide che non hai mai visto o risolto prima vi consiglio vivamente di andare dopo specificamente questo tipo di sfide al fine di sentire il grande piacere di imparare qualcosa che non sapevi prima.
Un’altra preziosa lezione che ho imparato in questa competizione è che, in una visione computerizzata (questo vale anche per la PNL) è molto importante controllare ogni singola previsione ad occhio per vedere cosa funziona e cosa no. Se i tuoi dati sono abbastanza piccoli dovresti andare a controllare ogni singolo output di sicuro. Questo vi permetterà di venire ulteriormente con idee migliori o anche il debug del codice se qualcosa non va con esso.
Finora abbiamo definito i mattoni di vaniglia U-Net e menzionato come possiamo manipolare gli obiettivi per risolvere, per esempio, la segmentazione. Ora possiamo discutere ulteriormente la flessibilità di questo tipo di reti encoder-decoder. Per flessibilità intendo la libertà che hai su di esso e la creatività che puoi mettere sul suo design.
Chiunque pratichi il deep learning ad un certo punto si imbatte nel trasferimento dell’apprendimento perché è un’idea molto potente. In breve l’apprendimento del trasferimento è il concetto di utilizzare una rete pretrained che è stata addestrata su molti campioni per un compito simile che stiamo affrontando ma manca la stessa quantità di dati. Anche con un numero sufficiente di apprendimento trasferimento dei dati può aumentare le prestazioni fino a un certo punto, non solo per le attività di visione del computer, ma anche per NLP troppo.
L’apprendimento del trasferimento si è rivelato una tecnica potente anche per le architetture U-Net. Abbiamo precedentemente definito due componenti principali di U-Net; down e up. Riformuliamo queste parti come encoder e decoder questa volta. Parte encoder prende fondamentalmente l’ingresso e lo codifica in uno spazio di funzionalità a basso dimensionale che rappresenta il nostro ingresso in una dimensione inferiore. Ora immaginate di sostituire questo encoder con il vostro vincitore ImageNet preferito; VGG, Resnet, Inception, NasNet, … che mai si desidera. Queste reti sono altamente progettati per fare una cosa comune: per codificare un’immagine naturale nel miglior modo possibile per classificare e loro pretrained pesi su ImageNet sono in attesa per voi di afferrare on-line.
Quindi perché non usare una di queste architetture come nostro encoder e costruire il decoder in modo che funzioni allo stesso modo dell’U-Net originale, ma meglio, sugli steroidi.
TernausNet che è l’architettura vincitore per Kaggle Carvana challenge utilizza la stessa idea di apprendimento del trasferimento con VGG11 come codificatore. [15, 16]