La segmentazione delle istanze consiste nell’identificare i contorni degli oggetti a livello dei pixel. Rispetto a task simili di computer vision, rappresenta uno dei compiti più difficili. Si considerino i seguenti task:

- Classificazione: c’è un palloncino nell’immagine
- Segmentazione semantica: questi sono tutti i pixel a cui corrispondono oggetti palloncino
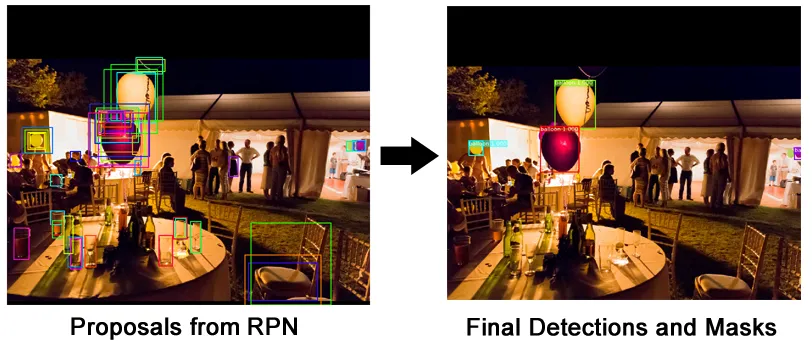
- Riconoscimento di oggetti: ci sono 7 palloncini nell’immagine in queste posizioni. Iniziamo a considerare oggetti che si sovrappongono
- Segmentazione di istanze: ci sono 7 palloncini in queste posizioni e questi sono i pixel che appartengono a ciascuno di essi separatamente
Una Mask R-CNN (regional convolutional neural network) è un framework a due livelli: il primo scannerizza l’immagine e genera i proposals (zone in cui è probabile che sia contenuto un oggetto), il secondo classifica i proposals e genera box di contorno e maschere.
E’ stata introdotta nel 2017 attraverso il paper Mask R-CNN che estende la sua predecessora, Faster R-CNN, degli stessi autori. La Faster R-CNN è un framework popolare per il riconoscimento degli oggetti, la Mas R-CNN la estende aggiungendo la segmentazione delle istanze, tra le altre cose.
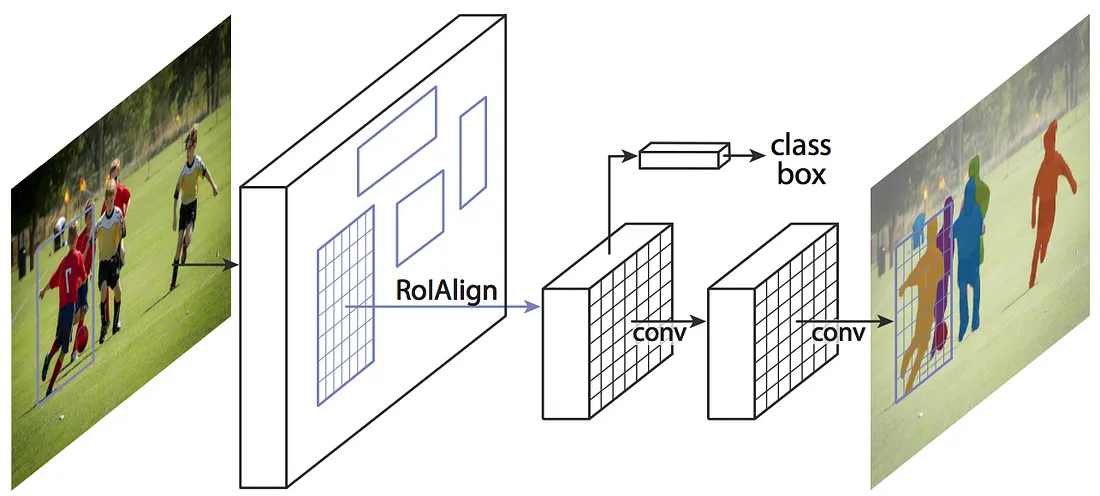
Approcciando il problema da un alto livello la Mask R-CNN è costituita dai seguenti moduli:
- Struttura
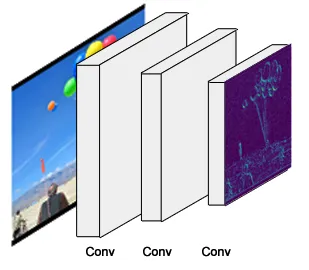
Illustrazione semplificata dello scheletro della rete Questa è una rete neurale convoluzionale standard (tipicamente ResNet50 o ResNet101) che serve come estrattore delle features. I primi livelli estraggono caratteristiche di basso livello (contorni e angoli) e i livelli successivi rilevano features ad alto livello (automobile, persone, cielo).
Passando attraverso la spina dorsale della rete, l’immagine viene convertita da 1024x1024x3 (RGB) ad una feature map di dimensioni 32x32x2048. QUesta feature map diventa l’input per i passaggi successivi.
Suggerimento per il codice: la struttura è costruita con la funzione resnet_graph(). Il codice supporta ResNet50 e ResNet101
Feature Pyramid Network
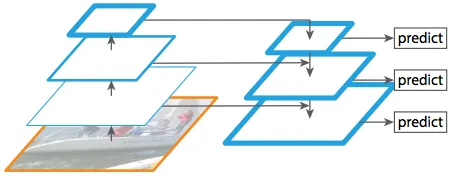
Sorgente: paper Feature Pyramid Networks Sebbene la struttura portante descritta sopra funzioni benissimo, può essere migliorata. La Feature Pyramid Network (FPN) è stata introdotta dagli stessi autori della Mask R-CNN come estensione in grado di rappresentare meglio gli oggetti a più scale.
La FPN migliora la piramide standard di estrazione delle features aggiungendo una seconda piramide che prende le features di livello più alto dalla prima piramide e le passa ai livelli più bassi. In questo modo permette alle caratteristiche ad ogni livello di avere accesso sia a quelle di livelli più bassi che più alti.
La nostra implementazione di Mask R-CNN utilizza una ResNet101 + un FPN
Suggerimento per il codice: La FPN viene creata in MaskRCNN.build(). La sezione successiva alla costruzione della ResNet. La RPN introduce complessità aggiuntive: piuttosto che una singola backbone feature map (ovvero, il livello più alto della prima piramide), in FPN c’è una feature map ad ogni livello della seconda piramide. Quella da utilizzare la scegliamo in modo dinamico in base alle dimensioni dell’oggetto. Continuerò a riferirmi alla backbone feature map come un’unica feature map, ma ricordate che utilizzando FPN stiamo in realtà ne consideriamouna delle tante durante la fase di esecuzione.
- Region proposal network (RPN)

Illustrazione semplificata che mostra 49 ancore La RPN è una rete neurale leggera che scansiona l’immagine come se vi applicasse una finestra scorrevole cercando le aree che contengono oggetti.
Le regioni su cui la RPN effettua la scansione sono chiamate ancore. Si tratta di caselle distribuite nell’area dell’immagine, come mostrato sopra. In realtà quella è una versione semplificata. In pratica, ci sono circa 200K ancore di dimensioni diverse e rapporti diversi che si sovrappongono in modo da coprire la maggior parte possibile dell’immagine.
Quanto la RPN può scannerizzare velocemente un numero così elevato di ancore? In realt, abbastanza velocemente.
La finestra scorrevole è gestita dalla natura convoluzionale della RPN, che le consente di eseguire la scansione di tutte le regioni in parallelo (su una GPU). Inoltre, la RPN non esegue una scansione diretta dell’immagine (anche se le ancore sono disegnate sull’immagine a scopo illustrativo). Al contrario, la RPN esegue la scansione sulla backbone feature map. Ciò consente alla RPN di riutilizzare in modo efficiente le caratteristiche estratte e di evitare calcoli duplicati. Con queste ottimizzazioni, l’RPN viene eseguita in circa 10 ms, secondo il paper Faster RCNN che l’ha introdotta. Nella Mask R-CNN si utilizzano generalmente immagini di dimensioni maggiori e un numero di ancore maggiore, per questo potrebbe richiedere più tempo.
Suggerimento per il codice: RPN viene creata in rpn_grap(). Le scale delle ancore e i rapporti sono controllati da RPN_ANCHOR_SCALES e RPN_ANCHOR_RATIOS in config.py
La RPN genera due output per ciascuna ancora:

3 ancore (linea con puntini) e lo spostamento/scala applicato ad esse per adattarsi con precisione all’oggetto (linea). Più ancore possono mappare lo stesso oggetto • Classe ancora: una delle due classi: primo piano o sfondo. La classe FG implica che probabilmente c’è un oggetto in quel riquadro .
• Rifinitura del riquadro di contorno: un’ancora in primo piano (ancora positiva) potrebbe non essere perfettamente centrata sull’oggetto. Per cui la RPN stima una delta (variazione % lungo x,y, larghezza e altezza) per rifinire il riquadro dell’ancora in modo da adattarlo meglio all’oggettoUtilizzando le previsioni RPN, scegliamo le ancore migliori che probabilmente contengono oggetti e ne perfezioniamo la posizione e le dimensioni. Se diverse ancore si sovrappongono troppo, teniamo quella con il punteggio di primo piano più alto e scartiamo le altre (si parla di soppressione non massima). Dopodiché otteniamo le proposte finali (regioni di interesse) e possiamo passare allo step successivo.
Suggerimento per il codice: Il ProposalLayer è un layer personalizzato di Keras che legge l’output di una RPN, estrae le ancore migliori e vi applica la rifinitura del riquadro di contorno.
- Classificatore delle ROI & Regressore dei riquadri di contornoQuesto step viene eseguito sulle regioni di interesse (ROIs) estratte con la RPN. Proprio come la RPN, genera due output per ciascuna ROI:
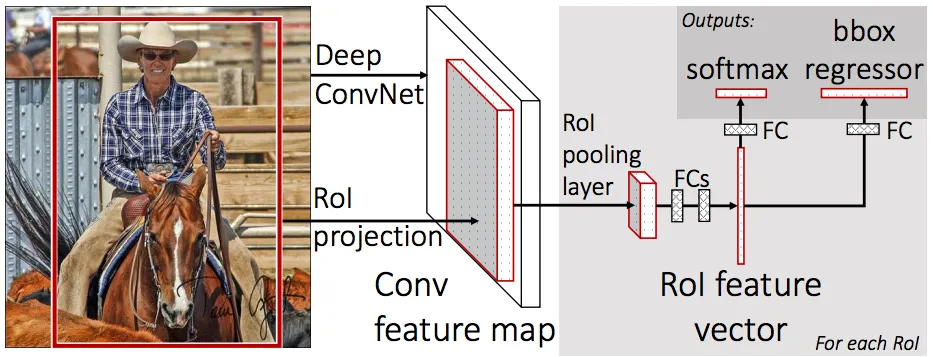
Illustrazione dello step 2. Sorgente. Fast R-CNN (https://arxiv.org/abs/1504.08083) - Classe : La classe dell’oggetto nella ROI. A differenza della RPN, che ha due classi (FG/BG), questa rete è più profonda e ha la capacità di classificare le regioni in classi specifiche (persona, auto, sedia, … ecc.). Può anche generare una classe di sfondo, che porta allo scarto della ROI.
- Rifinitura del riquadro di contorno: Molto simile a quello che avviene nella RPN, ha lo scopo di affinare ulteriormente la posizione e le dimensioni del rettangolo di selezione per incapsulare l’oggetto.
Suggerimento per il codice: Il classificatore e il regressore del riquadro di contorno sono creati in fpn_classifier_graph()
Pooling delle ROI
C’è un piccolo problema da risolvere prima di continuare. I classificatori non gestiscono molto bene le dimensioni variabili degli input. In genere richiedono una dimensione fissa dell’input. Tuttavia, a causa dello step di rifinitura del riquadro di contorno nella RPN, i riquadri delle ROI possono avere dimensioni diverse. E’ qui che entra in gioco il pooling delle ROI

La feature map proviene da un layer di basso livello, ai fini dell’illustrazione, in modo da rendere la comprensione più semplice. Il pooling delle ROI si riferisce al ritaglio di una parte della feature map e ridimensionarla a dimensione fissa. In linea di principio è simile al ritaglio di una parte di un’immagine e al suo successivo ridimensionamento (ma ci sono differenze nei dettagli di implementazione).
Gli autori di Mask R-CNN propongono un metodo che hanno chiamato ROIAlign, in cui campionano la feature map a diversi punti e vi applicano un’interpolazione bilineare. Nella nostra implementazione, abbiamo usato la funzione crop_and_resize di TensorFlow per semplicità e perché è abbastanza vicina per la maggior parte degli scopi.
Suggerimento per il codice: il pooling delle ROI è implementato nella classe PyramidROIAlign.
- Maschere di segmentazione
Se vi fermate alla fine della sezione precedente allora avete ottenuto una Faster R-CNN come framework di riconoscimento degli oggetti. La rete mask è l’aggiunta che il paper della Mask R-CNN ha introdotto.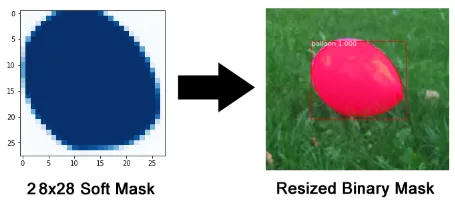
Il ramo mask è una rete convoluzionale che prende le regioni positive selezionate dal classificatore di ROI e genera maschere per esse. Le maschere generate sono a bassa risoluzione: 28×28 pixel. Sono, però, maschere soft rappresentate da numeri con la virgola, quindi contengono più dettagli di quelle binarie. La bassa dimensione della maschera aiuta a mantenere il ramo mask più leggero. Durante l’addestramento riduciamo le maschere ground-truth a 28×28 per calcolare la funzione di perdita, e durante l’inferenza scaliamo le maschere predette alla dimensione della ROI di riquadro di contorno, si ottengono così le maschere finali, una per oggetto.
Suggerimento per il codice: il ramo mask viene costruito con build_fpn_mask_graph().
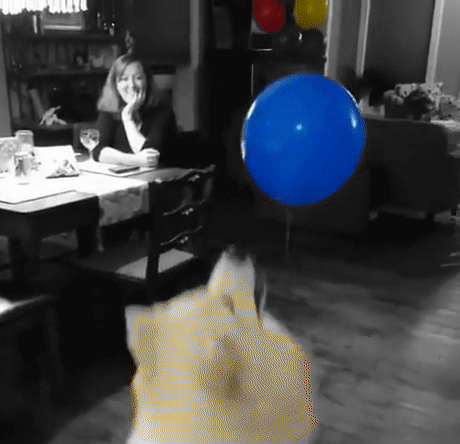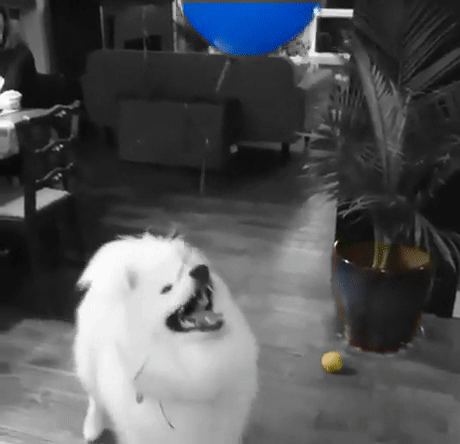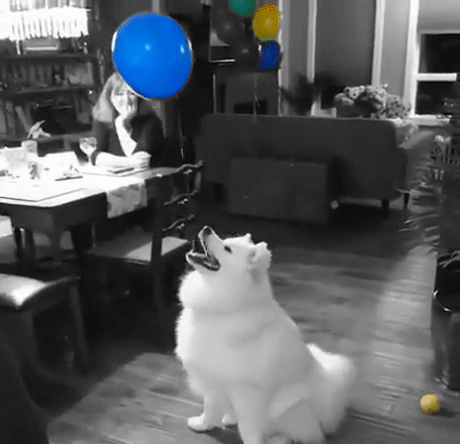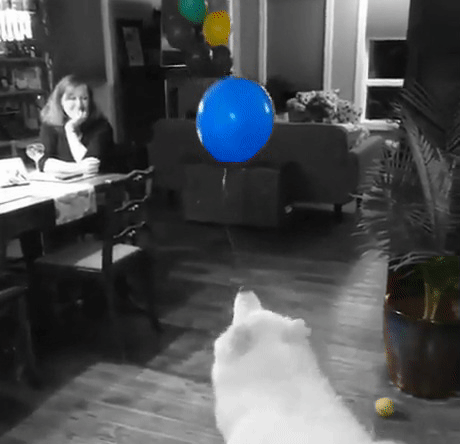
A differenza della maggior parte delle app di modifica delle immagini che includono questo filtro, il nostro filtro sarà un po’ più intelligente: trova gli oggetti automaticamente. Il che diventa ancora più utile se lo si vuole applicare ai video piuttosto che a una singola immagine.
In genere, inizierei a cercare i dataset pubblici che contengono gli oggetti di cui ho bisogno. In questo caso, però, volevo documentare l’intero ciclo e mostrare come si costruisce un dataset da zero.
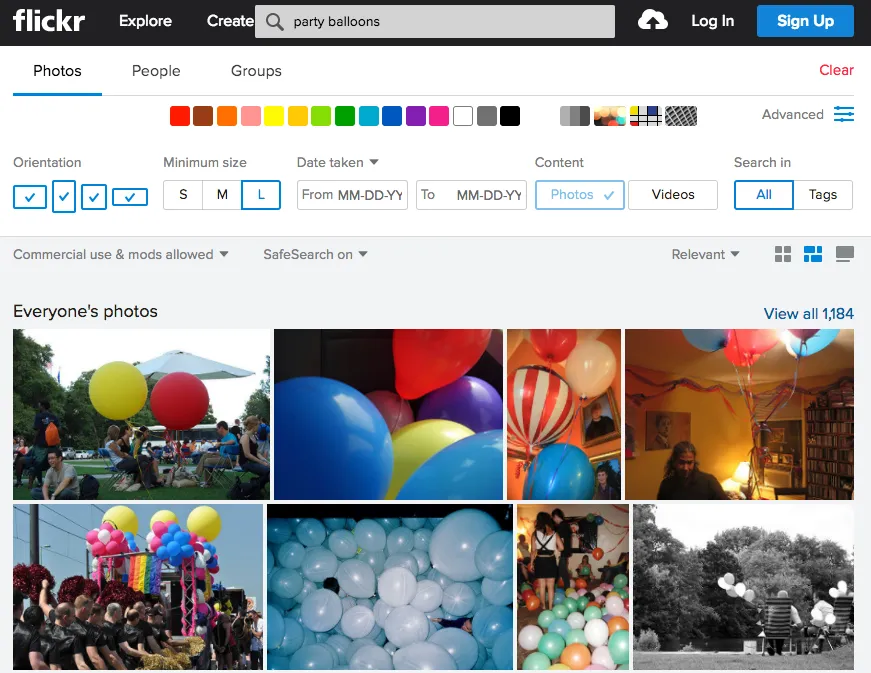
Ho cercato immagini di palloncini su flickr, limitando il tipo di licenza a “Uso commerciale e modifiche consentite”. Questo ha restituito immagini più che sufficienti per le mie esigenze. Ho scelto un totale di 75 immagini e le ho divise in training set e validation set. Trovare le immagini è facile. Annotarle è la parte difficile.
Aspettate! Non ci dovrebbero servire tipo un milione di immagini per addestrare un modello di deep learning? A volte sì, spesso però non è necessario. Mi affido a due punti principali per ridurre in modo significativo i requisiti di addestramento:
Primo, il transfer learning. Ciò significa semplicemente che, invece di addestrare un modello da zero, parto da un file di pesi che è stato addestrato sul dataset COCO (lo forniamo nel repo di github). Sebbene il dataset COCO non contenga la classe palloncini, contiene molte altre immagini (~120K), quindi i pesi addestrati hanno già appreso molte delle caratteristiche comuni nelle immagini naturali, il che aiuta molto.
Inoltre, dato il semplice caso d’uso, non pretendo un’elevata accuratezza da questo modello, quindi un dataset di dimensioni ridotte dovrebbe essere sufficiente.
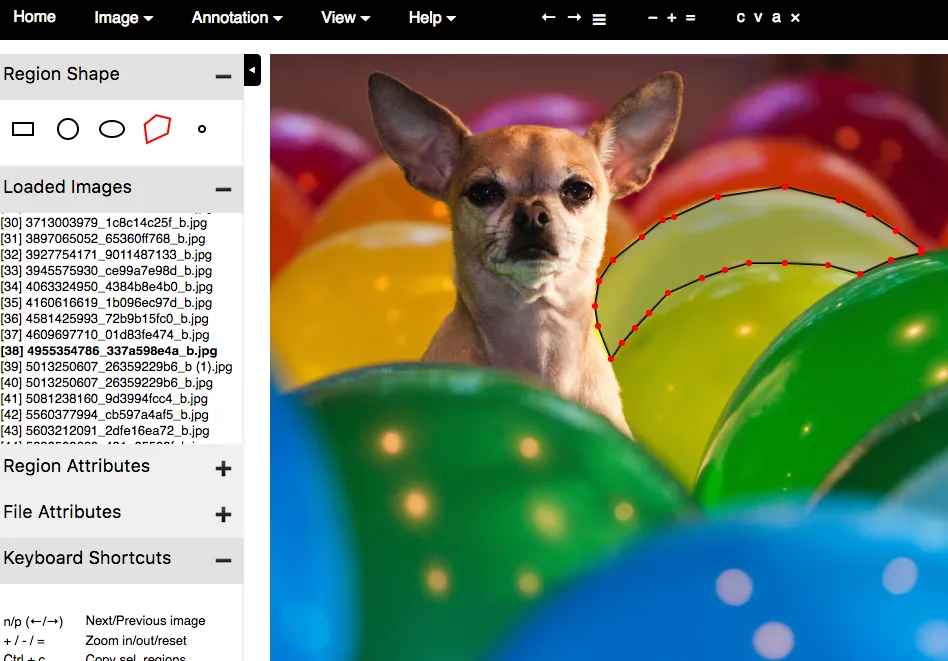
Esistono molti strumenti per annotare le immagini. Io ho scelto VIA (VGG Image Annotator) per la sua semplicità. È un singolo file HTML che si scarica e si apre in un browser. L’annotazione delle prime immagini è stata molto lenta, ma una volta abituatomi all’interfaccia utente, ho annotato circa un oggetto al minuto.
Se non vi piace VIA, ecco una lista di altri tool che ho testato:
- LabelMe: uno dei tool più conosciuti. La UI era un po’ lenta, soprattutto zoomando le immagini di grandi dimensioni.
- RectLabel: Facile e semplice da utilizzare. Funziona solo su Mac
- LabelBox: Piuttosto buono per progetti di etichettatura di grandi dimensioni, ha opzioni per diversi tipi di task di etichettatura
- VGG Image Annotator (VIA): veloce, leggero e veramente ben costruito. Questo è quello che ho utilizzato io
- COCO UI: strumento utilizzato per annotare il dataset COCO
Per verificare che il mio codice è stato implementato correttamente ho aggiunto questo notebook di Jupyter. Carica il dataset, visualizza le maschere e i riquadri di contorno e visualizza le ancore per verificare che le loro dimensioni si adattano bene alle dimensioni degli oggetti. Qui c’è un esempio di cosa dovreste aspettarvi di vedere:

Suggerimento per il codice: per creare questo notebook ho copiato inspect_data.ipynb che è stato scritto per il dataset COCO e modificato il blocco di codice iniziale per caricare il dataset Balloons.
Configurazioni
Le configurazioni per questo progetto sono simili alla configurazione di base usata per addestrare il dataset COCO, quindi ho solo avuto bisogno di sovrascrivere 3 valori. Come ho fatto con la classe Dataset, eredito dalla classe Config di base e aggiungo le mie sovrascritture:
class BalloonConfig(Config): # Give the configuration a recognizable name NAME = "balloons" # Number of classes (including background) NUM_CLASSES = 1 + 1 # Background + balloon # Number of training steps per epoch STEPS_PER_EPOCH = 100
La configurazione base utilizza immagini in input di dimensioni 1024x1024px per un’accuratezza migliore. Le ho tenute in quel modo. Le mie immagini sono un po’ più piccole, ma il modello le ridimensiona automaticamente.
Suggerimento per il codice: la classe config di base si trova in config.py. Mentre BalloonConfig è in balloons.py
Mask R-CNN è un modello piuttosto pesante. In particolare, la nostra implementazione utilizza ResNet101 e FPN. Quindi è necessaria una GPU moderna con 12 GB di memoria. Potrebbe funzionare anche con meno, ma non ho provato. Ho usato le instances P2 di Amazon per addestrare questo modello e, dato il piccolo set di dati, l’addestramento richiede meno di un’ora.
Avviare l’addestramento con questo comando, eseguito dalla directory balloon. Qui specifichiamo che l’addestramento deve partire dai pesi COCO pre-addestrati. Il codice scaricherà automaticamente i pesi dal nostro repository:
python3 balloon.py train --dataset=/path/to/dataset --model=coco
Per riprendere il training se si interrompe:
python3 balloon.py train --dataset=/path/to/dataset --model=last
Suggerimento per il codice: Oltre a balloons.py, il repository contiene altri tre esempi: train_shapes.ipynb che addestra un modello giocattolo a riconoscere le forme geometriche, coco.py che viene addestrato sul dataset COCO e nucleus che segmenta i nuclei di immagini di microscopia.
Analisi dei risultati
Il notebook inspect_balloon_model mostra i risultati generati dal modello addestrato. Controllatelo per ottenere maggiori visualizzazioni e per un’analisi passo passo della pipeline.
Suggerimento per il codice: Questo notebook è una versione semplificata di inspect_mode.ipynb che contiene codice per la visualizzazione e il debugging per il dataset COCO
Infine, ora che abbiamo le maschere, utilizziamole per applicare l’effetto color splash. Il metodo è molto semplice: creare una versione in scala di grigi dell’immagine e poi, nelle aree contrassegnate dalla maschera oggetto, ricopiare i pixel a colori dell’immagine originale. Ecco un esempio:

Suggerimento per il codice: Il codice che applica l’effetto è contenuto nella funzione color_splash(). detect_and_color_splash() si occupa dell’intero processo: caricamento dell’immagine, esecuzione della segmentazione di istanze e applicazione del filtro color splash.
FAQ
- Q: Voglio approfondire l’argomento e capire i dettagli, cosa potrei leggere? A: leggete questi paper in questo ordine: RCNN (pdf), Fast RCNN, Faster RCNN, FPN, Mask RCNN.
- Q: Dove posso chiedere altre domande? A: La pagina Issues su GitHub è attiva, potete usarla sia per domande che per riportare problemi. Ricordate di cercare le questioni già risolte nel caso in cui la vostra domanda sia già stata posta e risolta
- Q: Posso contribuire al progetto? A: Sarebbe grandioso! Le richieste sono sempre benvenute

