Nel nostro ultimo articolo abbiamo citato lo strumento per MLOps con componenti necessarie:
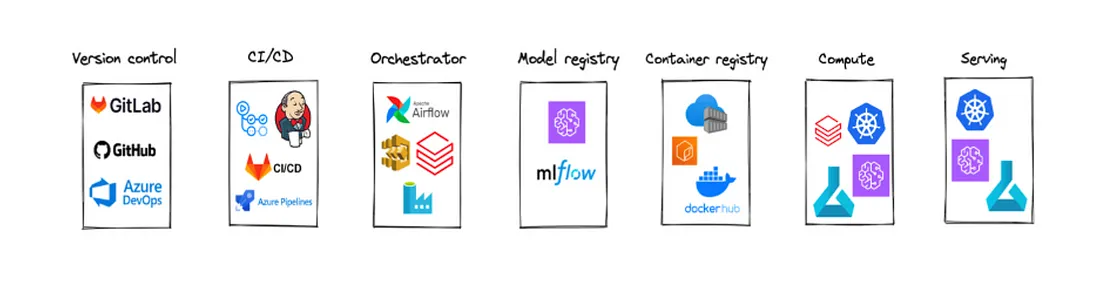
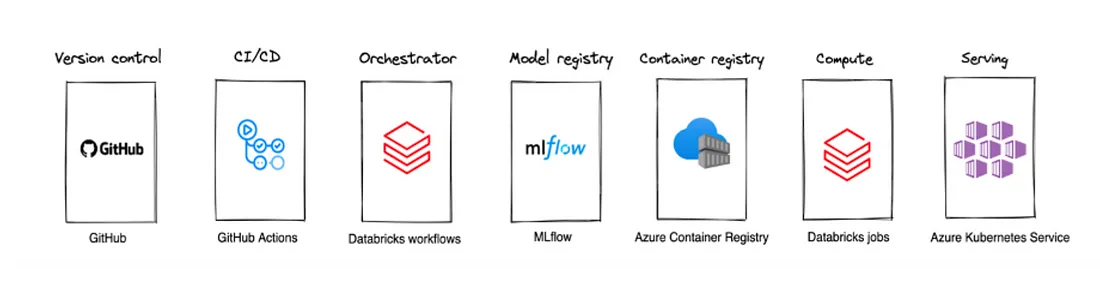
Il nostro panorama di soluzioni è composto da GitHub (controllo di versione), GitHub Actions (CI/CD), Databricks Workflows (Orchestrator), MLflow (Model registry), ACR (container registry), Databricks workflow (compute), AKS (serving).
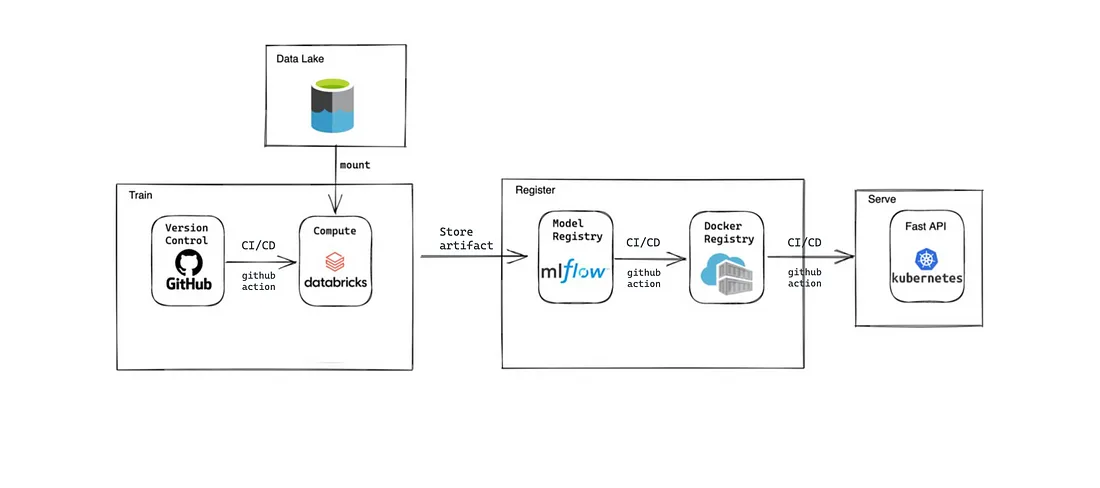
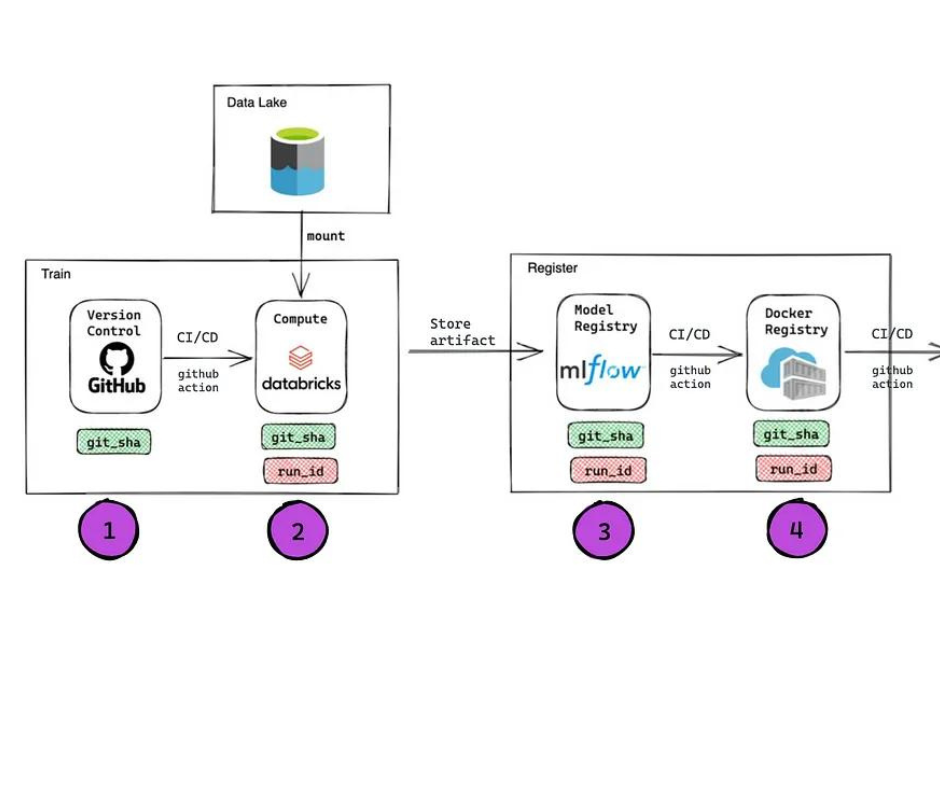
Qua sotto la nostra soluzione viene definita step by step. Le componenti di tracciabilità ad ogni step vengono descritte nella sezione successiva.
- Utilizziamo GitHUb come base per il nostro codice dove possiamo creare e rilasciare nuove versioni
- Le pipeline CI vengono attivate automaticamente quando c’è una PR nei rami principali. La pipeline CD rilascia una nuova versione, crea/aggiorna il lavoro Databricks per la formazione e/o la previsione. Azure Blob Storage è il nostro datalake e viene montato sullo spazio di lavoro di Databricks.
- Dopo l’addestramento, gli artefatti del modello vengono salvati in mlflow e viene registrata una nuova versione del modello.
- La pipeline Github action CD recupera l’artefatto del modello da mlflow e crea un’immagine docker con esso. L’immagine docker viene inviata al Azure Container Registry.
- L’ultimo passo consiste nel distribuire il container da ACR ad AKS per eseguire la nostra applicazione.

Step1: GIT_SHA permette di tracciare la versione del codice
A ogni rilascio, nella pipeline delle azioni di GitHub, esportiamo GIT_SHA come variabile d’ambiente, usiamo jinja2 per aggiornare la definizione json del lavoro di Databricks in modo che diventi disponibile per i lavori python in esecuzione su Databricks. Questo indica quale versione del codice è utilizzata in quel particolare lavoro.
Distribuiamo i lavori di formazione su Databricks tramite la configurazione json utilizzando GitHub Actions.
# example of GitHub action
steps:
- name: Setup env vars
id: setup_env_vars
run: |
echo "GIT_SHA=${{ github.sha }}" >> $GITHUB_ENV
echo "DATABRICKS_TOKEN=${{ secrets.DATABRICKS_TOKEN }}" >> $GITHUB_ENV
echo "DATABRICKS_HOST=${{ secrets.DATABRICKS_HOST }}" >> $GITHUB_ENV
# example of job cluster definition in Databricks job json
"job_clusters": [
{
"job_cluster_key": "recommender_cluster",
"new_cluster": {
"spark_version": "12.2.x-cpu-ml-scala2.12",
"node_type_id": "Standard_D4s_v5",
"spark_conf": {
"spark.speculation": true
},
"azure_attributes": {
"availability": "SPOT_WITH_FALLBACK_AZURE"
},
"autoscale": {
"min_workers": 2,
"max_workers": 4
},
"spark_env_vars": {
"DATABRICKS_HOST": "{{ DATABRICKS_HOST }}",
"GIT_SHA": "{{ GIT_SHA }}",
}
}
}
]
Step2: Databricks run_id e job_id
Ogni lavoro Databricks e ogni esecuzione di lavoro ha un job_id e un run_id come identificatori univoci. run_id e job_id possono essere resi disponibili all’interno di uno script python che viene eseguito tramite un lavoro Databricks attraverso la variabile parametro del task {{run_id}}.
È anche possibile recuperare il run_id usando dbutils. Non lo usiamo perché vogliamo che lo script python sia eseguibile anche localmente.
{{job_id}} : Identificativo univoco assegnato a un lavoro.
{{run_id}} : Identificativo univoco assegnato a un lavoro in esecuzione
{{parent_run_id}} : Identificativo univoco assegnato all’esecuzione di un lavoro con più task.
{{task_key}} : Il nome univoco assegnato a un’attività che fa parte di un lavoro con più attività.
Parametri dell’attività Databricks
"spark_python_task": {
"python_file": "recommender/train_recommender.py",
"parameters": [
"--job_id",
"{{job_id}}",
"--run_id",
"{{parent_run_id}}"
]
}
Esempio di codice python per recuperare run_id e job_id dall’esecuzione di un lavoro Databricks:
import argparse
import os
def get_arguments():
parser = argparse.ArgumentParser(description=’reads default arguments’)
parser.add_argument('--run_id', metavar='run_id', type=str, help='Databricks run id')
parser.add_argument('--job_id', metavar='job_id', type=str, help='Databricks job id')
args = parser.parse_args()
return args.run_id, args.job_id
run_id, job_id = get_arguments()
git_sha = os.environ['GIT_SHA']
project_name = 'amazon-recommender'
Step3: Registrare il modello in MLflow in modo che possa essere recuperato da uno specifico run id
Quando si registrano i modelli nel registro dei modelli di mlflow, si aggiungono gli attributi GIT_SHA, DBR_RUN_ID, DBR_JOB_ID come tag.
import mlflow
mlflow.set_experiment(experiment_name='/Shared/Amazon_recommender')
with mlflow.start_run(run_name="amazon-recommender") as run:
recom_model = AmazonProductRecommender(spark_df=spark_df).train()
wrapped_model = AmazonProductRecommenderWrapper(recom_model)
mlflow_run_id = run.info.run_id
tags = {
"GIT_SHA": git_sha,
"MLFLOW_RUN_ID": mlflow_run_id,
"DBR_JOB_ID": job_id,
"DBR_RUN_ID": run_id,
}
mlflow.set_tags(tags)
mlflow.pyfunc.log_model("model", python_model=wrapped_model)
model_uri = f"runs:/{mlflow_run_id}/model"
mlflow.register_model(model_uri, project_name, tags=tags)
Il modello registrato con i tag appare così:
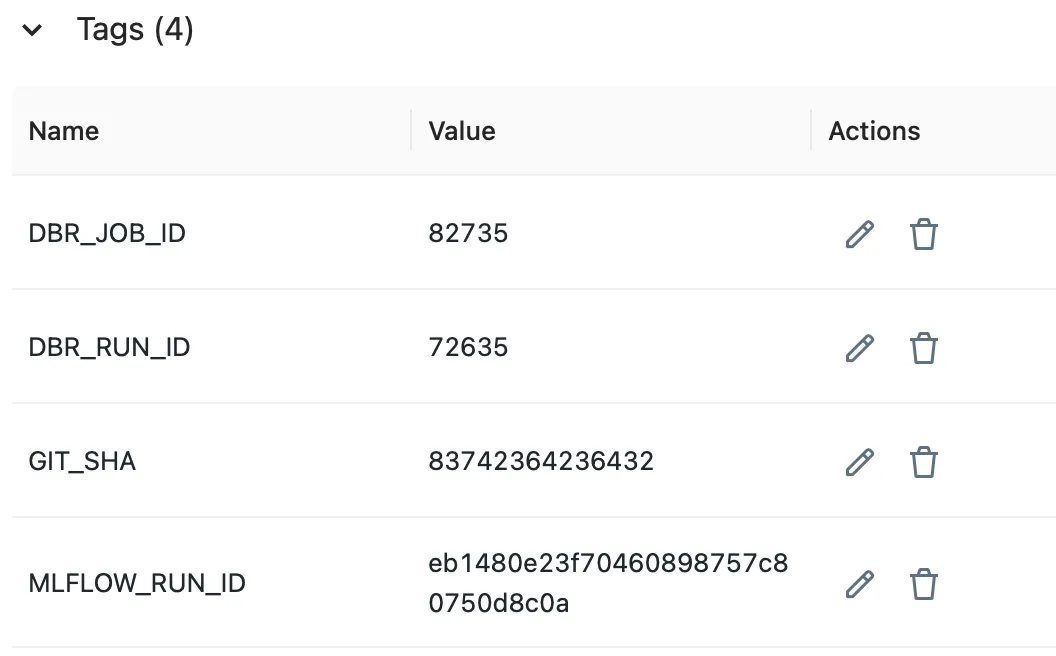
Step4: incorporare il modello nell’immagine docker tramite run_id
Il modello può essere scaricato dal registro di MLflow tramite run id e copiato all’immagine docker nello step di costruzione del docker.
Codice di esempio:
from mlflow.tracking.client import MlflowClient
from mlflow.store.artifact.models_artifact_repo import ModelsArtifactRepository
client = MlflowClient()
model_version = client.search_model_versions(
f"name='{project_name}' and tag.DBR_RUN_ID = ‘{run_id}’
)[0].version
ModelsArtifactRepository(
f"models:/{project_name}/{model_version}"
).download_artifacts(artifact_path="", dst_path=download_path)
Step5: Utilizzare API su Kubernetes con gli attributi
Gli attributi salvati nel registro dei modelli sono inclusi anche nell’immagine docker come variabili d’ambiente: git_sha, run_id. Per una tracciabilità completa, ogni corpo di risposta viene salvato nel sistema di logging con gli attributi disponibili nell’ambiente git_sha, run_id.
Codice di esempio: git_sha e run_id sono passati come variabili d’ambiente tramite il manifesto di distribuzione
apiVersion: apps/v1 kind: Deployment metadata: name: "amazon-recommender" spec: containers: - name: amazon-recommender-api image: <ACR_URL>/amazon-recommender:<GIT_SHA>-<RUN_ID> env: - name: git_sha value: <GIT_SHA> - name: run_id value: <RUN_ID>
Codice di esempio: variabili d’ambiente sono poi accessibili in una FastAPI app
app = FastAPI()
@app.get("/predict/{query}")
def read_item (basket: List[str] = Query(None)):
return {
"recommended_items": model.predict(basket),
"run_id": os.environ["run_id"],
"git_sha": os.environ["git_sha"]
}
Per distribuire nuovamente la versione precedente o una versione specifica per la distribuzione delle API, eseguiamo manualmente una pipeline di CD-rollback con un nome di immagine specifico.
Ogni immagine docker salvata in ACR (Azure Container Registry) è denominata con un identificatore univoco, che è il Databricks run_id del lavoro di formazione corrispondente. Se desideriamo distribuire nuovamente un modello specifico, attiviamo manualmente la pipeline di distribuzione per il rollback (azione GitHub) fornendo il run_id specifico. Se non viene fornito alcun run_id, viene distribuita nuovamente l’immagine precedente.