Articolo in lingua originale di Ravi Kumar
In questo articolo parleremo del modello Word2Vec Gensim e ne vedremo l’implementazione passo passo.

Gensim è una libreria software per Python utilizzata per analizzare e comprendere i dati testuali. È progettata per lavorare bene con grandi raccolte di testo e dispone di algoritmi efficienti per diversi task di natural language processing (NLP), inclusi la modellazione dei topic, analisi di similarità tra documenti e pre-elaborazione dei dati testuali. La libreria è open-source e viene comunemente utilizzata in progetti di NLP e text-mining.

- E’ stata ideata per gestire ampie raccolte di testo e fornisce implementazioni efficenti di algoritmi popolari come Latent Semantic Analysis (LSA) e Latent Dirichlet Allocation (LDA)
- Viene utilizzata anche per pre-elaborare dati testuali come per la tokenizzazione e la lemmatizzazione
- Fornisce anche strumenti per il post-processing di modelli di topic come calcolare il punteggio della coerenza al topic
Il Word2Vec di Gensim è un’implementazione dell’algoritmo word2vec per imparare la rappresentazione vettoriale di parole (Alle parole viene assegnato un certo numero)
L’algoritmo Word2vec è un approccio basato su reti neurali per il natural language processing (NLP) che impara a rappresentare le parole in uno spazio vettoriale ad alta dimensionalità dove le parole con un significato simile sono collocate vicine tra loro.
Queste rappresentazioni vettoriali possono essere utilizzate in diversi task di NLP come la classificazione del testo, il riconoscimento di entità denominate e la traduzione automatica.
- Iniziamo importando tutte le librerie importanti
# imports needed and set up logging import gzip import gensim import logging logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
Il logging ci aiuterà a visualizzare tutte le operazioni che si stanno verificando, per più dettagli leggete qua.
- Estraiamo e leggiamo il dataset (questo è un dataset di recensioni di auto e hotel
data_file="reviews_data.txt.gz" with gzip.open ('reviews_data.txt.gz', 'rb') as f: for i,line in enumerate (f): print(line) break
Così è come appare il dataset - Convertire il dataset in una lista
def read_input_file(input_file): """This method reads the input file which is in gzip format""" logging.info("reading file {0}...this may take a while".format(input_file)) with gzip.open (input_file, 'rb') as f: for i, line in enumerate (f): if (i%10000==0): logging.info ("read {0} reviews".format (i)) # do some pre-processing and return a list of words for each review text yield gensim.utils.simple_preprocess (line) # read the tokenized reviews into a list # each review item becomes a serries of words # so this becomes a list of lists documents = list (read_input_file (data_file)) logging.info ("Done reading data file")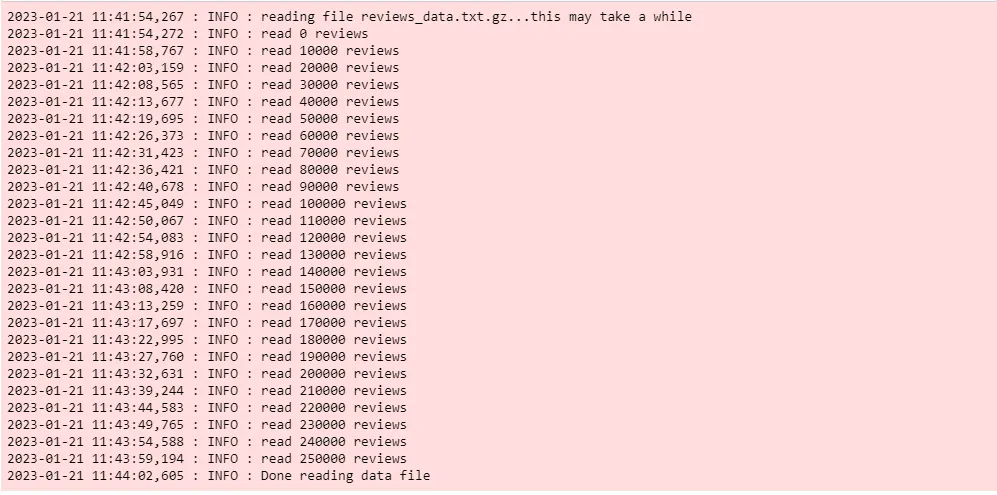
Output del terzo step - Addestrare un modello Word2Vec
model = gensim.models.Word2Vec (documents, vector_size=150, window=10, min_count=2, workers=10) model.train(documents,total_examples=len(documents),epochs=10)
vector_size: La dimensione del vettore denso rappresenta ogni token o parola. Se si dispone di dati molto limitati, allora la dimensione dovrebbe avere un valore molto più piccolo. Se si dispone di molti dati, è bene sperimentare varie dimensioni. Un valore di 100-150 ha funzionato bene per me.
window: La distanza massima tra la parola target e la parola vicina. Se la posizione del vicino è superiore alla larghezza massima della finestra a sinistra e a destra, alcuni vicini non vengono considerati correlati alla parola target. In teoria, una finestra più piccola dovrebbe fornire termini più correlati. Se si dispone di molti dati, la dimensione della finestra non dovrebbe essere troppo importante, purché sia una finestra di dimensioni sufficienti.
min_count: minima frequenza di occorrenza delle parole. Il modello ignorerà le parole che non soddisfano questo minimo. Parole estremamente infrequenti sono solitamente poco importanti, quindi è bene sbarazzarsene. A meno che il dataset non sia veramente esiguo, questo non influisce veramente sul modello.
workers: quanti thread utilizzare?

output dello step 4 - Vediamo alcuni risultati
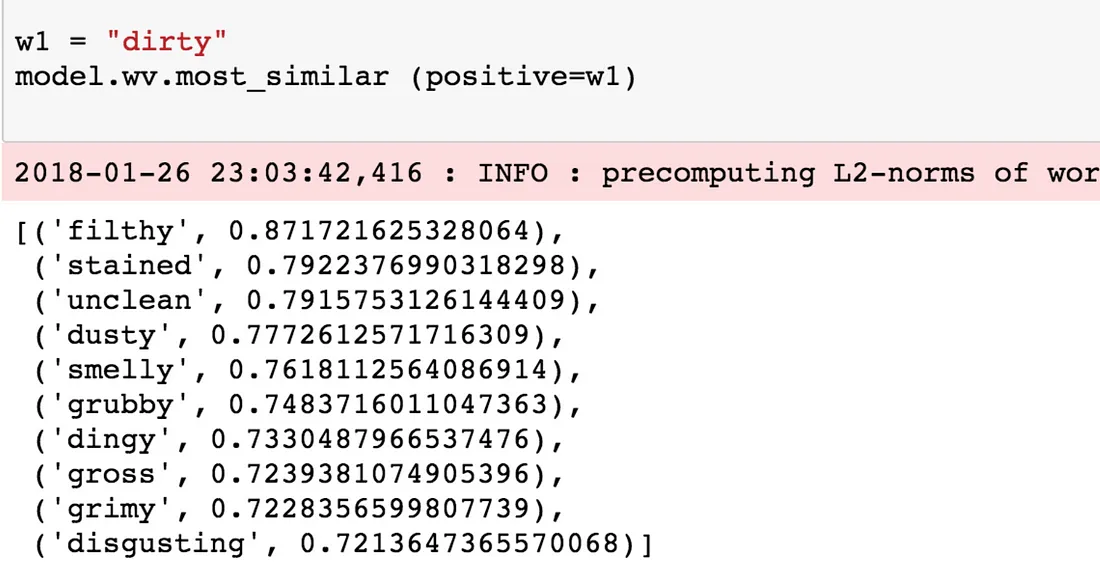
• Cercando parole simili a dirty. Tutto quello che dobbiamo fare qui è richiamare la funzione most_similar e passargli la parola dirty. Questo ritornerà le 10 migliori parole simili.w1 = "dirty" model.wv.most_similar (positive=w1)
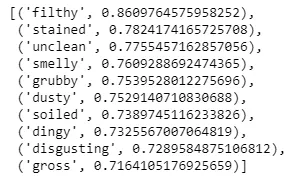
Output della parola ‘dirty’ Provate a trovare le parole simili a polite, france and shocked.
- Si possono anche specificare diversi esempi positivi per ottenere cose che sono correlate nel contesto fornito e fornire esempi negativi per dire cosa non dovrebbe essere considerato correlato.
# get everything related to stuff on the bed w1 = ["bed",'sheet','pillow'] w2 = ['couch'] model.wv.most_similar (positive=w1,negative=w2,topn=10)
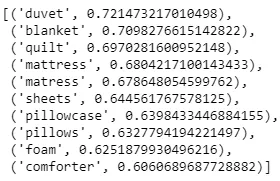
Output esempio 2 - Si può trovare la somiglianza tra due parole nel vocabolario utilizzando similarity
# similarity between two different words model.wv.similarity(w1="dirty",w2="smelly")

Output esempio 3 - Trovare la parola più strana in un elenco dato di parole usando “doesnt_match”
# Which one is the odd one out in this list? model.wv.doesnt_match(["cat","dog","france"]) output: ‘france’
- Si possono anche specificare diversi esempi positivi per ottenere cose che sono correlate nel contesto fornito e fornire esempi negativi per dire cosa non dovrebbe essere considerato correlato.
