
Il computer quantistico si aspetta che i dati vengano elaborati in uno stato quantico. I dispositivi NISQ (Noisy Intermediate Scale Quantum) contengono una quantità limitata di qubit, che sono stabili per un periodo di tempo limitato. Il primo passo nell’apprendimento di macchine quantistiche consiste nel caricare i dati classici codificandoli nello stato dei qubit. Questo processo è noto anche come codifica o incorporazione dei dati quantistici ed è un passo importante nella preparazione dello stato quantistico. La codifica dei dati classici per la computazione quantistica gioca un ruolo fondamentale nella progettazione complessiva e nelle prestazioni dell’algoritmo di apprendimento della macchina quantistica (QML). Non sapete cosa sono i qubit o, più in generale, di cosa si sta parlando? Potete sicuramente approfondire questi argomenti nel corso di Quantum Computing!
La rappresentazione deve essere compatta e utilizzare solo pochi qubit e poche porte quantistiche per utilizzare gli attuali dispositivi NISQ. I qubit non decadono solo velocemente e anche le porte quantistiche sono soggette a errori, limitando il numero di operazioni per preparare lo stato quantico, che deve essere piccolo.
La codifica può essere classificata in due categorie:
- la codifica digitale è la rappresentazione dei dati sotto forma di stringhe di qubit
- la codifica analogica rappresenta i dati nelle ampiezze di uno stato.
Se i dati devono essere elaborati mediante calcoli aritmetici, è preferibile una codifica digitale. Per gli algoritmi di apprendimento automatico, invece, è preferibile una codifica analogica, in quanto è necessario mappare i dati nell’ampio spazio di Hilbert del dispositivo quantistico.
I tempi di esecuzione logaritmici o lineari sono considerati quando si preparano i dati classici per l’elaborazione quantistica. Ogni codifica è essenzialmente un compromesso tra tre forze principali.
1) il numero di qubit deve essere minimo
2) il numero di operazioni parallele deve essere minimo per ridurre al minimo l’ampiezza del circuito quantistico
3) i dati devono essere rappresentati in modo appropriato per i calcoli successivi.
L’apprendimento tipico di una macchina quantistica prevede 3 fasi.
- Codifica: Questo articolo è dedicato a questa fase in cui i dati classici vengono caricati in uno stato quantistico.
- Elaborazione: È la fase in cui il dispositivo quantistico elabora l’input incorporato, che può essere un circuito variazionale o una routine quantistica.
- Misurazione: In questa fase viene misurato il risultato atteso, che diventa poi la previsione per il QML.

Se ci addentriamo nel processo di codifica complessivo, per preparare l’input per un algoritmo quantistico come stato quantistico, è necessario eseguire un circuito quantistico che prepari lo stato corrispondente. Questo circuito può essere generato in fasi classiche di pre-elaborazione e poi generare il circuito per la preparazione dello stato, come mostrato di seguito.

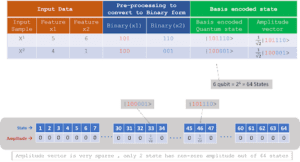
La codifica di base viene utilizzata principalmente quando i numeri reali devono essere manipolati aritmeticamente in un algoritmo quantistico. In poche parole, tale codifica rappresenta i numeri reali come numeri binari e poi li trasforma in uno stato quantistico su base computazionale. Nella codifica Basis di un dato numerico, il suo valore è approssimato dalla sua rappresentazione binaria. La stringa di bit risultante, che dice ABCD, viene quindi codificata dallo stato bitstring |ABCD>. Si veda l’esempio seguente:
Il codice di esempio di Pennylane è riportato di seguito:
Questo non è efficiente in termini di numero di qubit richiesti, ma è buono per le operazioni aritmetiche.

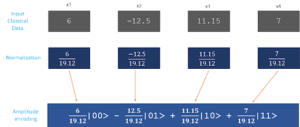
In questa tecnica, i dati sono codificati nelle ampiezze di uno stato quantistico. Se la manipolazione aritmetica dei dati da parte degli algoritmi quantistici non è in primo piano, si utilizzano rappresentazioni dei dati più compatte. In particolare, l’ampio spazio di Hilbert di un dispositivo quantistico viene adeguatamente sfruttato in tali codifiche. Questa codifica richiede log2 (n) qubit per rappresentare un punto di dati n-dimensionale. Si veda l’esempio seguente, in cui i punti di dati a 4 dimensioni sono codificati in 2 qubit.
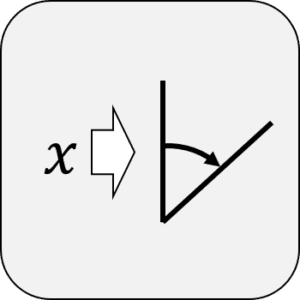
La codifica angolare è essenzialmente la forma più elementare di codifica dei dati classici in uno stato quantistico. Le n caratteristiche classiche sono codificate nell’angolo di rotazione degli n qubit. La codifica angolare, nota anche come codifica del prodotto tensoriale, richiede n qubit per rappresentare dati n-dimensionali, ma è più economica in termini di complessità: richiede una rotazione su ogni qubit. Questa codifica è direttamente utile per l’elaborazione dei dati nelle reti neurali quantistiche. La codifica angolare viene eseguita applicando una rotazione del gate intorno all’asse x 𝑅𝑥(v) o all’asse y 𝑅𝑦(v), dove 𝑣 è il valore da codificare. Se utilizziamo lo stesso esempio come ingresso per la codifica dell’ampiezza, la codifica dell’angolo (in questo caso utilizziamo la rotazione dell’asse y) sarà la seguente dopo la preparazione dello stato.
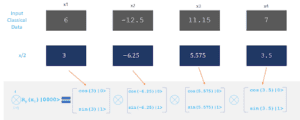
Codice Pennylane come segue:
Il vantaggio principale di questa codifica è che è molto efficiente in termini di operazioni: È necessario solo un numero costante di operazioni parallele, indipendentemente dal numero di valori di dati da codificare. Questo non è ottimale dal punto di vista dei qubit, poiché ogni componente del vettore di ingresso richiede un qubit.
Un’altra codifica correlata, chiamata codifica angolare densa, sfrutta un’ulteriore proprietà dei qubit (fase relativa) per utilizzare i soli n/2 qubit per codificare n punti di dati.

Questa codifica si basa sulla sovrapposizione per codificare una serie di punti di dati in un registro di qubit della stessa lunghezza. Ciò richiede una rappresentazione binaria di tutti i valori di uguale lunghezza, oppure dobbiamo riempire di zeri. Utilizzare una memoria associativa quantistica (QuAM) per preparare una sovrapposizione di valori codificati in base nello stesso formato di registro di qubit. Si noti che il registro quantistico è una sovrapposizione equamente pesata dei valori codificati in base. Si veda il seguente esempio di codifica QuAM.

La codifica QuAM risultante è una codifica digitale ed è quindi adatta per i calcoli aritmetici.
La QRAM viene utilizzata per accedere a una sovrapposizione di valori di dati in una sola volta. Una RAM classica che riceve un indirizzo con un indice di memoria carica i dati memorizzati a questo indirizzo in un registro di uscita. La QRAM offre la stessa funzionalità, ma l’indirizzo e il registro di uscita sono registri quantistici. Di conseguenza, sia l’indirizzo che il registro di uscita possono essere la sovrapposizione di più valori. Per questa codifica, sono necessari l qubit per codificare i valori dei dati utilizzando la codifica Basis. Il registro degli indirizzi richiede log(n) qubit aggiuntivi per un massimo di n indirizzi. Le proprietà computazionali sono simili a quelle delle codifiche Basis e QuAM: Poiché viene preparata una sovrapposizione dei valori dei dati codificati, i dati possono essere elaborati in parallelo (parallelismo quantistico) e si possono utilizzare operazioni aritmetiche come l’addizione o la moltiplicazione.
Poche altre codifiche devono ancora essere dimostrate utili in QML, ma questo è un campo giovane e le opportunità sono immense:
- a) Incorporazione di spostamento:
Questa tecnica codifica N caratteristiche in ampiezze di spostamento r o fase ϕ dei campioni di dati.
- b) Incorporamento IQP:
Codifica N caratteristiche in N qubit utilizzando le porte diagonali del circuito IQP.
- c) Codifica QAOA:
Codifica N caratteristiche in n > N qubit, utilizzando un circuito quantistico addestrabile a strati ispirato all’ansatz QAOA.
- d) Incorporazione di compressione:
Codifica N caratteristiche nelle ampiezze di compressione r ≥ 0 o fase ϕ (0 ~ 360) dei campioni di dati.
