
MLOps? Di cosa stiamo parlando?
In Rappi come in molte altre startup ad alto potenziale, è chiaro che una delle chiavi del successo è stata e continua ad essere l’implementazione di analytics e data science, utilizzando modelli di machine learning che forniscono preziosi insight al business. Il suo utilizzo nelle startup e nelle aziende tradizionali che si sono concentrate sulla trasformazione digitale è aumentato in modo esponenziale e oggi, essendo parte del più ampio campo dell’AI, l’apprendimento automatico dovrebbe essere comune come le applicazioni software in generale, ed è proprio qui che gli MLOp trattano gli algoritmi di ML come dispositivi software riutilizzabili, offrendo un’implementazione rapida e ripetibile dei modelli, seguita da un’integrazione continua e monitorata che assicura che ogni modello funzioni in modo ottimale mentre il suo ambiente si evolve nel tempo.
In altre parole, e per concludere, gli MLOps sono l’insieme di pratiche che un’azienda deve mettere in atto per gestire con successo l’AI e il ML.
È davvero importante in una startup?
Certo che sì! Se si dispone di scienza dei dati e IA, è necessario avere quasi per obbligo un team MLOps dedicato, perché i modelli da soli sono impotenti e influenzati solo dai dati con cui sono stati addestrati. Al giorno d’oggi, una start-up deve affrontare grandi sfide in termini di gestione dei propri dati, che sono in costante crescita e cambiamento. I dati ottenuti per addestrare un modello all’inizio di un anno non sono gli stessi che si possono avere qualche mese dopo, e possono persino cambiare drasticamente!
Senza MLOps, i progetti di scienza dei dati diventano effimeri, monouso e senza vita, e sì, ci sarà chi dirà che non c’è da preoccuparsi una volta che hanno svolto la loro funzione e trovato ciò che l’azienda sta cercando, ma andiamo, non è così che funzionano le cose. Se vogliamo contribuire alla nostra attività, soprattutto se questa dipende dalla tecnologia come uno dei suoi pilastri fondamentali, abbiamo bisogno di dinamismo e produttività quando lavoriamo fianco a fianco con la scienza dei dati ed è per questo che lo stato degli MLOps nel 2021 è dominato dalle startup.
Da dove cominciare?
Dobbiamo sapere che lo sviluppo di sistemi di apprendimento automatico inizia tipicamente con un obiettivo o una finalità aziendale. A seconda del livello di ambizione, portarli in produzione è un lavoro duro ed è per questo che ci sono così tanti componenti possibili per costruire un sistema MLOps completo e robusto. Naturalmente dobbiamo partire dai modelli e dai dati che abbiamo, altrimenti che senso avrebbe? Per questo, una piattaforma collaborativa per l’esecuzione di esperimenti di ML e la creazione di modelli di ML da parte dei data scientist dovrebbe essere considerata una parte fondamentale del framework MLOps. Vediamola da vicino.
Siete pronti?
Dopo che gli obiettivi sono stati chiaramente tradotti in problemi di ML. Il passo successivo è iniziare a cercare i dati di input appropriati e il tipo di modelli da provare per quel tipo di dati, e questo è solo l’inizio. Per questo motivo prenderemo in considerazione 7 basi per eseguire con successo la produzione di tutti i nostri modelli di apprendimento automatico e condivideremo gli strumenti più importanti che possono essere davvero utili durante l’esecuzione di ciascuno di essi. Andiamo!

Questa è la fase strutturale più importante a livello di dati ed è generalmente gestita dai team di data engineering e data science; dobbiamo occuparci di attività di pulizia, bilanciamento, outlier, cattiva formattazione e altre sfide presentate dai dati grezzi quando si lavora con essi. D’altra parte, è generalmente raccomandato essere in grado di sviluppare un’analisi esplorativa e le esercitazioni necessarie per conoscere i dati, valutarli e sapere come manipolarli nel modo migliore, per cui condivideremo alcune librerie di visualizzazione dei dati che possono essere molto utili.
-
Seaborn
Si tratta di una libreria abbastanza leggera in cui è possibile ottenere il massimo dall’analisi dei dati; possiamo ottenere diagrammi a violino, boxplot, diagrammi di densità, tra gli altri, che possono aiutarci a vedere come si comportano i nostri dati.

https://seaborn.pydata.org/examples/index.html
-
Plotly e Dash
Raggiunge in gran parte ciò che offre Seaborn, ma è molto più interattivo e dispone di strumenti utili per esportare i grafici, ingrandirli o sovrapporli, ha l’integrazione con il web e i widget, e ha anche una sezione specializzata per realizzare alcune visualizzazioni di intelligenza artificiale, ma naturalmente il suo costo computazionale è molto più alto.

Main page: https://plotly.com/
Python Library: https://plotly.com/python/
-
AmChart4
Amchart è una libreria HTML e javascript in grado di rappresentare quasi tutto ciò che ci viene in mente; il problema è proprio che dobbiamo conoscere le basi dell’HTML e del javascript se vogliamo usarla.

https://www.amcharts.com/demos/
-
Missingno
Questa libreria è molto utile per aiutarci a risolvere un grosso problema che si presenta comunemente durante l’addestramento di un modello di apprendimento automatico, ovvero i dati nulli; con essa possiamo creare una matrice di nullità, un diagramma di correlazione dei dati nulli e altre analisi più avanzate per aiutarci ad affrontarli. Come si usa?

https://www.geeksforgeeks.org/python-visualize-missing-values-nan-values-using-missingno-library/
Un’altra sfida che i data scientist devono affrontare durante l’addestramento dei modelli è la riproducibilità. Questo problema può essere risolto con il versioning dei modelli e dei dati, in modo da aggiungere il controllo di versione a tutti i componenti dei sistemi di ML (principalmente dati e modelli) insieme ai parametri. Vediamo cosa può aiutarci.
-
DVC
DVC, o Data Version Control, è un sistema di controllo delle versioni open-source per progetti di machine learning. è in grado di gestire il versioning e l’organizzazione di grandi quantità di dati e di archiviarli in modo ben organizzato e accessibile. Si consiglia di leggere Come costruire un flusso di lavoro efficiente per i progetti di apprendimento automatico utilizzando il Data Version Control (DVC).

-
Pachyderm
Pachyderm riunisce il controllo di versione per i dati con gli strumenti per costruire pipeline ML/AI end-to-end scalabili, consentendo agli utenti di sviluppare il codice in qualsiasi linguaggio, framework o strumento di loro scelta. È stato scelto più volte come base ideale per i team che vogliono risolvere in modo affidabile i problemi di intelligenza artificiale e di ML del mondo reale, quindi è un’ottima opzione da tenere in considerazione. Andate avanti e date un’occhiata al suo tutorial per principianti.

-
Liquibase
Liquibase è una libreria Open Source (sotto licenza Apache 2.0), totalmente indipendente dal DBMS, che ci permetterà di tracciare, gestire e applicare le modifiche al modello dei dati; è una libreria progettata per funzionare principalmente dalla linea di comando, ma si integra molto facilmente anche con Maven e Spring. Conoscere le basi!

La messa a punto degli iperparametri consiste nella scelta di un insieme di iperparametri ottimali per un algoritmo di apprendimento. Inoltre, l’impostazione della corretta combinazione di iperparametri è l’unico modo per estrarre le massime prestazioni dai modelli.
-
HyperOpt
HyperOpt è una libreria open-source in Python per l’ottimizzazione bayesiana, progettata per l’ottimizzazione su larga scala di modelli con centinaia di parametri e che consente di scalare la procedura di ottimizzazione su più core e più macchine. Questa libreria è stata utilizzata esplicitamente per ottimizzare le pipeline di apprendimento automatico, tra cui la preparazione dei dati, la selezione dei modelli e gli iperparametri dei modelli. Scopritela!
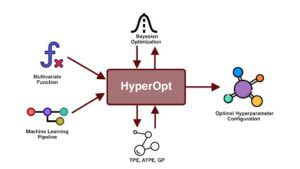
http://hyperopt.github.io/hyperopt/
-
Optuna
Optuna è un framework software per automatizzare il processo di ottimizzazione di questi iperparametri. Trova automaticamente i valori ottimali degli iperparametri utilizzando diversi campionatori come la ricerca a griglia, gli algoritmi casuali, bayesiani ed evolutivi. Come rendere il vostro modello fantastico con Optuna?

-
Scikit-optimize
Scikit-Optimize è una libreria Python open-source per l’esecuzione di compiti di ottimizzazione. Offre algoritmi di ottimizzazione efficienti, come l’ottimizzazione bayesiana, e può essere utilizzata per trovare il minimo o il massimo di funzioni di costo arbitrarie. Tutorial qui!

https://scikit-optimize.github.io/stable/
-
SigOpt
SigOpt offre una soluzione avanzata e scalabile in grado di incidere sulle prestazioni di qualsiasi tipo di modello AI. Aiuta a risparmiare tempo automatizzando i processi, il che lo rende uno strumento adatto alla messa a punto degli iperparametri. Avete bisogno di esempi?

Questo è il luogo degli scienziati dei dati, naturalmente, abbiamo bisogno di uno sviluppo completo dei modelli di ML e qui è dove entrano in azione, possiamo usare molti strumenti qui, dalle basi come un terminale al software che gestisce tutta la gestione del codice. A questo punto, è il momento di creare tutto il codice necessario per costruire un modello di apprendimento automatico e, per questo, daremo un’occhiata ad alcuni degli strumenti più utilizzati per farlo. Controlliamo un foglio di istruzioni per quasi tutti i progetti di ML.
-
Jupyter
Jupyter Notebook è un client-server che consente la creazione e la condivisione di documenti web in formato JSON che seguono uno schema versionato e un elenco ordinato di celle di input e output. Queste celle contengono, tra l’altro, codice, testo e contenuti multimediali. Un vantaggio è che Jupyter può essere eseguito in qualsiasi browser standard e ha una piena integrazione con Python.
-
Spyder
Spyder è un ambiente scientifico gratuito e open-source scritto in Python, per Python, e progettato da e per scienziati, ingegneri e analisti di dati. Offre una combinazione unica di funzionalità avanzate di editing, analisi, debug e profiling di uno strumento di sviluppo completo con l’esplorazione dei dati, l’esecuzione interattiva, l’ispezione approfondita e le capacità di visualizzazione di un pacchetto scientifico.
-
Google Colab
Colab ci permette di collegarci a un server Jupyter già configurato e di eseguire codice python utilizzando l’hardware di Google; ha quasi le stesse funzionalità di Jupyter locale, ma è molto utile quando non si può disporre di una macchina molto potente.
https://colab.research.google.com/notebooks/intro.ipynb
-
Anaconda
Anaconda è una distribuzione libera e gratuita dei linguaggi Python e R, utilizzati nella scienza dei dati e nell’apprendimento automatico. Ha molte librerie scaricate, quindi quasi sempre non dovrete preoccuparvi di installarle, ha Jupyter, spyder e R, senza contare molti altri strumenti utili, ma è più costosa dal punto di vista computazionale.
Quando il nostro flusso di lavoro ha diverse fasi, come la preelaborazione, l’addestramento, la valutazione, i database e così via, che possono essere eseguite separatamente, allora uno strumento di orchestrazione del flusso di lavoro è estremamente importante per questo compito, in quanto ci aiuta a eseguire tutto non solo nell’ordine giusto, ma anche nel momento in cui ne abbiamo bisogno. La maggior parte di essi ci permette di visualizzare la struttura e l’esecuzione della pipeline. Fin qui tutto bene!
-
Airflow
Apache Airflow è un gestore di flussi di lavoro, in altre parole uno strumento per la gestione, il monitoraggio e la pianificazione dei flussi di lavoro, utilizzato come orchestratore di servizi. Utilizza grafi aciclici diretti (DAG) per gestire l’orchestrazione dei flussi di lavoro e può essere collegato a cloud, database e molto altro. Affrontatelo!
-
Polyaxon
Polyaxon è una piattaforma utilizzata per costruire, addestrare e monitorare modelli di ML e applicazioni di deep learning. Supporta l’intero ciclo di vita delle applicazioni, riproducendole, gestendole e includendo l’orchestrazione dell’esecuzione. Potrebbe essere utile!
-
Kedro
Kedro è un framework Python open-source per la creazione di codice riproducibile, manutenibile e modulare per la scienza dei dati. Possiamo creare flussi di lavoro riproducibili, manutenibili e modulari per rendere i nostri processi di ML più semplici e accurati. Vediamo come iniziare a lavorare con Kedro.
https://kedro.readthedocs.io/en/stable/
Possiamo distribuire un modello integrandolo in un ambiente di produzione esistente. Il modello riceverà input e predirà un output per il processo decisionale di un caso d’uso specifico e potrà essere statico o dinamico. Il deployment statico prevede che il modello sia impacchettato in un software applicativo installabile e poi distribuito. D’altra parte, un deployment dinamico consiste nell’utilizzare un framework web con endpoint che rispondono alle richieste degli utenti. Di seguito parleremo del deployment dinamico e di due framework web in python.
-
Flask
Flask è un micro framework web scritto in Python. È in grado di creare un’API REST che consente di inviare dati e di ricevere una previsione come risposta. Proprio quello che ci serve! Potete seguire un semplice tutorial qui

https://flask.palletsprojects.com/en/2.0.x/
-
FastApi
FastAPI ha alcune caratteristiche preziose che rendono questo framework web ideale per la distribuzione di modelli di Machine Learning tramite API. È piuttosto simile a Flask ed entrambi risolvono lo stesso problema, come detto in precedenza: distribuire un modello di ML in un ambiente di produzione esistente. Si può verificare come si può distribuire un modello di ML con FastAPI

https://www.analyticsvidhya.com/blog/2020/11/fastapi-the-right-replacement-for-flask/
Notizia! Ora abbiamo i nostri modelli in produzione! Hanno le loro connessioni, i loro algoritmi e, a questo punto, stanno facendo il loro lavoro meravigliosamente. Passa una settimana e stiamo andando bene… un mese e stiamo andando altrettanto bene?
È qui che entra in gioco il monitoraggio dei modelli ML. Dobbiamo essere consapevoli delle prestazioni e delle metriche di ogni modello; ovviamente, i dati cambiano nel tempo e possiamo anche avere problemi quando ci alleniamo sempre con gli stessi dati. Ma non preoccupatevi: c’è molta matematica e alcuni software e librerie che possono tirarci fuori da questa situazione e ne condivideremo alcuni che possono essere molto utili.
-
Evidently
Evidently aiuta a valutare i modelli di apprendimento automatico durante la validazione e a monitorarli in produzione. Genera report visivi interattivi e profili JSON da dataframe pandas o file CSV. È possibile utilizzare i report visivi per analisi ad hoc, debugging e condivisione in team, e i profili JSON per integrare Evidently in pipeline di predizione o con altri strumenti di visualizzazione. Documentazione utile.
-
Idrosfera
Hydrosphere fornisce un’interpretazione delle previsioni del modello senza la necessità di accedere alla struttura del modello. Inoltre, Hydrosphere fornisce avvisi spiegabili quando si verificano cambiamenti nelle distribuzioni. Possiamo capire cosa è successo ai vostri dati e agire di conseguenza. Passo dopo passo? Naturalmente!

-
Alibi Detect
Alibi Detect è una libreria Python open-source incentrata sul rilevamento di outlier, adversarial e drift. Il pacchetto mira a coprire sia i rilevatori online che offline per dati tabellari, testo, immagini e serie temporali. Per il rilevamento delle derive sono supportati i backend TensorFlow e PyTorch.

https://github.com/SeldonIO/alibi-detect
Aspettate! Prendete contatto con alcuni fatti importanti
È una grande sfida sia in termini di prestazioni grezze che di rigore gestionale. I set di dati sono enormi, in crescita e possono cambiare in tempo reale. I modelli di intelligenza artificiale richiedono un attento monitoraggio attraverso cicli di esperimenti, messa a punto e riqualificazione per mantenere un’elevata precisione.
In media, l’80% dei modelli creati con l’intenzione di essere implementati non viene mai realizzato (Perché l’87% dei progetti di data science non arriva mai in produzione?). Inoltre, l’implementazione di un modello richiede in genere dai sei agli otto mesi. Se si implementa un modello creato sei-otto mesi fa, quel modello potrebbe essere già obsoleto. Non c’è da preoccuparsi: facciamo sempre del nostro meglio come parte di MLOps!
3,2,1 via!

Spero che abbiate ottenuto un’ampia panoramica di quelli che sono gli strumenti fondamentali per implementare le operazioni di machine learning! Con tutto questo, non resta che volare come un razzo pronto a partire!
Rimanete sintonizzati sul nostro post successivo che approfondirà gli strumenti MLOps specifici
