Sono sufficienti alcune righe di codice per implementare le tecniche di NLP con Python.

L’elaborazione del linguaggio naturale (NLP) si occupa di consentire ai computer di comprendere ed elaborare il linguaggio umano. I computer sono bravissimi a lavorare con dati strutturati come i fogli di calcolo; tuttavia, molte informazioni che scriviamo o parliamo sono non strutturate.
L’obiettivo della NLP è far sì che i computer comprendano i testi non strutturati e ne ricavino informazioni significative. Grazie a librerie open-source come spaCy e NLTK, è possibile implementare molte tecniche di NLP con poche righe di codice in Python.
In questo articolo, impareremo i concetti fondamentali di 7 tecniche di NLP e come implementarle facilmente in Python.
L’analisi del sentimento è una delle tecniche NLP più popolari che consiste nel prendere un pezzo di testo (ad esempio, un commento, una recensione o un documento) e determinare se i dati sono positivi, negativi o neutrali. Ha molte applicazioni nel settore sanitario, nel servizio clienti, nelle banche, ecc.
Implementazione in Python
Per casi semplici, in Python possiamo utilizzare VADER (Valence Aware Dictionary for Sentiment Reasoning), disponibile nel pacchetto NLTK, che può essere applicato direttamente ai dati di testo non etichettati. A titolo di esempio, vediamo di ottenere tutti i punteggi di sentiment delle battute pronunciate dai personaggi di un programma televisivo.
Per prima cosa, si utilizza un set di dati disponibile su Kaggle o sul mio Github denominato “avatar.csv”, quindi con VADER si calcola il punteggio di ogni battuta pronunciata. Tutto questo viene memorizzato nel dataframe df_character_sentiment.
Nel df_character_sentiment qui sotto, possiamo vedere che ogni frase riceve un punteggio negativo, neutro e positivo.
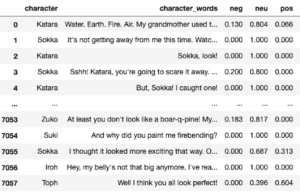
Potremmo anche raggruppare i punteggi per carattere e calcolare la media per ottenere il punteggio di sentiment per un carattere e poi rappresentarlo con diagrammi a barre orizzontali utilizzando la libreria matplotlib (il risultato è mostrato in questo articolo).
Nota: VADER è ottimizzato per i testi dei social media, quindi i risultati vanno presi con le molle. È possibile utilizzare un algoritmo più completo o svilupparne uno proprio con le librerie di apprendimento automatico. Nel link qui sotto, c’è una guida completa su come crearne uno da zero con Python utilizzando la libreria sklearn.
Il Named Entity Recognition è una tecnica utilizzata per individuare e classificare le entità nominate in un testo in categorie quali persone, organizzazioni, luoghi, espressioni di tempo, quantità, valori monetari, percentuali, ecc. È utilizzata per ottimizzare gli algoritmi dei motori di ricerca, i sistemi di raccomandazione, l’assistenza clienti, la classificazione dei contenuti, ecc.
Implementazione in Python
In Python, possiamo utilizzare il riconoscimento di entità denominate di SpaCy che supporta i seguenti tipi di entità.
![]()
Per vederla in azione, importiamo prima spacy e poi creiamo una variabile nlp che memorizzerà la pipelineen_core_web_sm. Si tratta di una piccola pipeline inglese addestrata su testi web scritti (blog, notizie, commenti), che include vocabolario, vettori, sintassi ed entità. Per trovare le entità, applichiamo nlp a una frase.
Vengono stampati i seguenti valori
Spacy ha scoperto che “Biden” è una persona, “Ukranian” è GPE (Paesi, città, Stati), “White House” è un’organizzazione e “this summer” è una data.
Se siete curiosi di vedere altre applicazioni di Spacy e di approfondire l’argomento del NLP, trovate più informazioni nel nostro corso “Natural Language Processing Hands-on (1)”
A differenza del CountVectorizer, il TF-IDF calcola dei “pesi” che rappresentano la rilevanza di una parola per un documento in un insieme di documenti (alias corpus). Il valore TF-IDF aumenta proporzionalmente al numero di volte in cui una parola compare nel documento ed è compensato dal numero di documenti del corpus che la contengono. In parole povere, più alto è il punteggio TF-IDF, più raro o unico o prezioso è il termine e viceversa. Trova applicazione nel reperimento delle informazioni, come i motori di ricerca che mirano a fornire i risultati più pertinenti a ciò che si sta cercando.
Prima di vedere l’implementazione di Python, vediamo un esempio per avere un’idea di come vengono calcolati TF e IDF. Per l’esempio seguente, utilizzeremo le stesse frasi usate per l’esempio di CountVectorizer.
Frase 1: “Amo scrivere codice in Python. Adoro il codice Python”.
Frase 2: “Odio scrivere codice in Java. Odio il codice Java”.
Frequenza dei termini (TF)
Esistono diversi modi per definire la frequenza dei termini. Uno suggerisce il conteggio grezzo (cioè quello che fa il Vettorizzatore di conteggi), ma altri suggeriscono che si tratta della frequenza della parola nella frase divisa per il numero totale di parole nella frase. Per questo semplice esempio, utilizzeremo il primo criterio e la frequenza dei termini è mostrata nella tabella seguente.
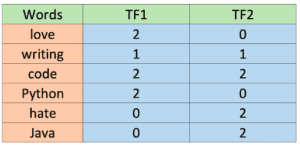
Come si può vedere, i valori sono gli stessi calcolati in precedenza per il CountVectorizer. Inoltre, le parole con 2 o meno lettere non vengono prese in considerazione.
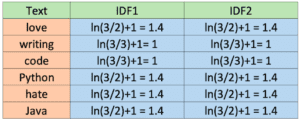
Frequenza inversa del documento (IDF)
Anche l’IDF viene calcolato in modi diversi. Sebbene la notazione standard dei libri di testo definisca l’IDF come idf(t) = log [ n / (df(t) + 1), la libreria sklearn che utilizzeremo in seguito in Python calcola la formula per impostazione predefinita come segue.

Inoltre, sklearn assume il logaritmo naturale ln invece del log e lo smoothing (smooth_idf=True). Calcoliamo i valori IDF per ogni parola come farà sklearn.
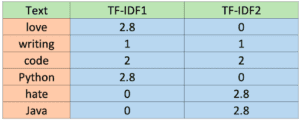
TF-IDF
Una volta ottenuti i valori TF e IDF, possiamo ottenere il TF-IDF moltiplicando entrambi i valori (TF-IDF = TF * IDF). I valori sono riportati nella tabella seguente.
Implementazione in Python
Il calcolo del TF-IDF mostrato nella tabella precedente in Python richiede poche righe di codice grazie alla libreria sklearn.

Nota: per impostazione predefinita, TfidfVectorizer() utilizza la normalizzazione l2, ma per utilizzare le stesse formule mostrate sopra si imposta come parametro norm=None. Per maggiori dettagli sulle formule utilizzate di default in sklearn e su come è possibile personalizzarle, consultare la documentazione.
Wordcloud è una tecnica popolare che ci aiuta a identificare le parole chiave in un testo. In una wordcloud, le parole più frequenti hanno un carattere più grande e più grande, mentre le parole meno frequenti hanno un carattere più piccolo o più sottile. In Python, è possibile creare semplici wordcloud con la libreria wordcloud e wordcloud di bell’aspetto con la libreria stylecloud.
Di seguito è riportato il codice per creare una wordcloud in Python. Sto usando un file di testo di un discorso di Steve Jobs che potete trovare sul mio Github.
Questo è il risultato del codice precedente.

Le nuvole di parole sono così popolari perché sono coinvolgenti, facili da capire e da creare.
È possibile personalizzare ulteriormente il testo cambiando i colori, rimuovendo le stopword, scegliendo l’immagine o addirittura aggiungendo la propria immagine per utilizzarla come maschera della wordcloud. Per maggiori dettagli, consultate la guida qui sotto.
Articolo originale di Frank Andrade
