
Sappiamo tutti che la moderna elaborazione del linguaggio naturale (NLP) ha fatto passi da gigante negli ultimi due anni grazie allo sviluppo delle reti di attenzione e dei trasformatori. Ciò ha aperto la strada a una pletora di nuovi algoritmi che hanno raggiunto lo stato dell’arte (SOTA) per i diversi compiti dell’NLP.
OpenAI è stato uno dei leader nel fornire il proprio modello linguistico (ora rilasciato GPT-3), addestrato su un enorme corpus di dati internet. Dato che il GPT-3 è un fenomeno recente, al momento in lingua inglese, ed è accessibile solo tramite le API fornite da OpenAI, ci concentreremo sulla versione precedente, cioè il GPT-2. Per conoscere i dettagli interni di GPT-2, vi suggerisco di consultare questo link. Per approfondire il tema dell’attenzione e dei trasformatori, ecco alcuni link eccellenti:
– Il trasformatore illustrato di Jay Alammar
– Il Trasformatore commentato di Harvard NLP
Il GPT-2 è stato rilasciato anche per l’inglese, il che rende difficile per chi cerca di generare testo in una lingua diversa.
Allora perché non addestrare il proprio modello GPT-2 sulla propria lingua preferita per la generazione di testi? Questo è esattamente ciò che faremo. Quindi, senza ulteriori indugi, iniziamo.
Per la dimostrazione, ho preso in considerazione una scrittura con alfabeto non latino (il bengalese), perché no! Per il modello ho utilizzato l’implementazione di Huggingface.
Se non sapete di cosa sto parlando, vi consigliamo il nostro corso livello 1 di NLP 😉
La raccolta di dati di buona qualità è una delle fasi più importanti, come concordano tutti i Data Scientist. Pertanto, si presuppone che si disponga già di una cartella contenente file .txt con tutti i dati puliti e memorizzati. Per semplicità, si possono usare i dati degli articoli di Wikipedia, che sono disponibili e possono essere scaricati con il seguente codice.
In questo modo verrà creata una cartella contenente tutti i file di Wikipedia dall’aspetto simile:
Nota: a causa della scarsità di risorse e poiché è a scopo dimostrativo, ho addestrato il modello su un piccolo sottoinsieme di libri di Satyajit Ray, in particolare la serie del detective Feluda.
Per predire, è sufficiente codificare il testo in ingresso e passarlo al modello
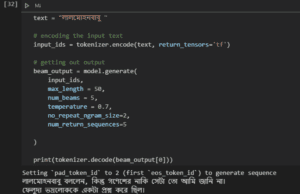
Ora, se siete bengalesi, potete far notare che l’output, sebbene la frase sia sintatticamente corretta, non sembra coeso. È vero, ma per questa dimostrazione l’ho ridotta al minimo.
