Il primo punto che vorrei sottolineare prima di tuffarmi nella spiegazione della bioinformatica è che la biologia è ad alta intensità di dati. Facciamo un passo indietro e guardiamo al quadro generale.
L’umanità è sempre stata curiosa del mondo che ci circonda. Le spedizioni mondiali di Colombo, Vespucci e Magellano hanno permesso di scoprire parti del mondo prima sconosciute. Nel XX secolo, la ricerca di vita extraterrestre e la comprensione del nostro pianeta e della nostra galassia hanno portato al lancio di satelliti e spedizioni spaziali nello spazio.
Negli ultimi anni, la robotica e l’automazione delle attrezzature di laboratorio hanno portato a un aumento esponenziale e alla generazione di “grandi” dati OMICS. Questo ci ha permesso di capire di più sulla vita e su come migliorarne la qualità. Ma come possono questi dati OMICS contribuire al miglioramento della vita? La risposta sta nell’utilizzo dell’apprendimento automatico per dare un senso a questi dati biologici, in particolare svelando modelli nascosti nei dati.
Biologia significa letteralmente studio della vita e degli organismi viventi. Il termine deriva dalle parole greche bios e logia, che significano rispettivamente vita e studio. In poche parole, la biologia studia i processi biologici che sostengono la vita.
Per studiare la vita, gli scienziati formulano delle ipotesi (un’ipotesi fondata) per le quali eseguono degli esperimenti per convalidare le loro ipotesi; questo processo porta alla generazione di risultati sperimentali che equivalgono letteralmente ai big data.
Storicamente, la genomica rappresenta la prima OMICS a decollare, in quanto gli sforzi iniziali erano rivolti a un progetto ambizioso chiamato Progetto Genoma Umano, il cui obiettivo era quello di svelare i segreti della vita sequenziando tutti i geni umani. Sebbene il completamento del progetto abbia prodotto informazioni utili, non è stato sufficiente a spiegare da solo tutti i segreti biologici della vita. Di conseguenza, ciò ha portato naturalmente alla continua ricerca di risposte esplorando altre OMICS come la proteomica, la glicomica, la lipidomica, ecc.

I recenti progressi nella tecnologia high-throughput, nella robotica e nell’automazione hanno continuato ad alimentare l’impegno di OMICS, affamato di risorse. L’attenzione diffusa per la bioinformatica è stata generata da diverse parole d’ordine come biotecnologia, medicina personalizzata, medicina di precisione e CRISPR-Cas9, solo per citarne alcune.
Vediamo ora alcuni dei compiti comuni della bioinformatica. Nell’illustrazione che segue si può notare che ci sono essenzialmente 4 compiti comuni.
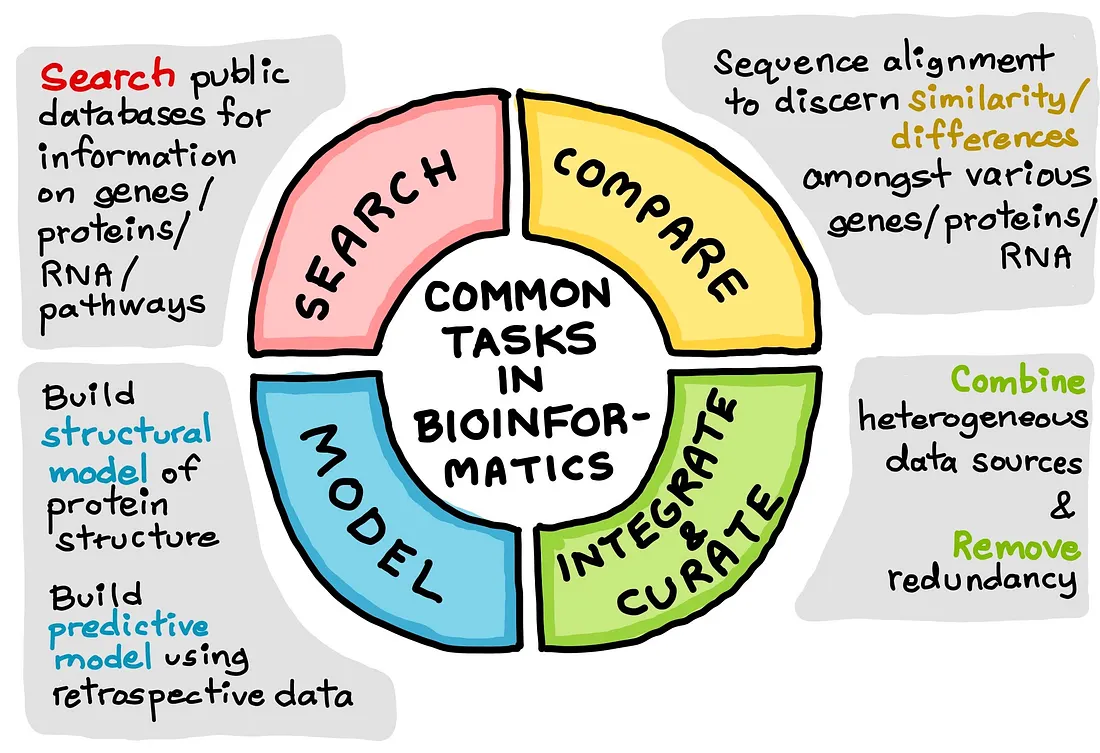
- Ricerca: Come cerchiamo su Google informazioni su argomenti che vorremmo approfondire, lo stesso vale quando vogliamo saperne di più su entità biologiche (geni, proteine, DNA, RNA, ecc.), entità chimiche (composti, farmaci, metaboliti, ecc.), percorsi biochimici e malattie. Al posto di Google esistono database specializzati come GenBank per le informazioni sui geni, ChEMBL / PubChem / ChemSpider per le informazioni chimiche, UniProt e Protein Data Bank per le informazioni sulle proteine, KEGG per le vie biochimiche (come geni, proteine e composti interagiscono tra loro per regolare i processi biologici che sostengono la vita).
- Confrontare: Facciamo confronti su quasi tutto nella nostra vita. Ad esempio, per decidere quale scheda grafica acquistare possiamo considerare il prezzo, le specifiche tecniche (numero di core CUDA) e altri fattori (riconoscimento del marchio, fattore di forma, ecc.). In bioinformatica, i geni o le proteine vengono confrontati tra loro per capire quanto siano simili o diversi. Se sono simili, in che modo (la somiglianza è solitamente determinata dai “motivi” comuni che i geni o le proteine simili hanno nella loro composizione di DNA (per i geni) e di aminoacidi (per le proteine).
- Integrare e curare: Nel ciclo di vita della scienza dei dati, siamo consapevoli che la raccolta e la pulizia dei dati rappresentano l’80% del tempo che impiegheremo per passare dai dati grezzi ai dati curati. Prima di intraprendere l’analisi dei dati e la costruzione di modelli di apprendimento automatico, un primo passo essenziale è quello di decidere l’ipotesi o la direzione di ricerca da seguire. Quali domande di ricerca (ipotesi) intendiamo affrontare? Tenendo questo in mente, scegliamo sottoinsiemi di dati dall’intero database che ci aiutino a rispondere all’ipotesi. Poi ripuliamo i dati per poterli riparare in vista della successiva analisi dei dati. Come dice il proverbio, “garbage in, garbage out”, quindi dovremo garantire l’integrità dei dati per aumentare l’affidabilità dell’analisi e del modello risultante.
- Modello: Questa è probabilmente la parte più divertente di tutte: i modelli! I modelli possono essere di diverse forme. Un modello strutturale è letteralmente un modello 2D o 3D di entità biologiche o chimiche composte da atomi virtuali collegati tra loro da legami chimici. Ad esempio, in una struttura chimica 2D, gli atomi (ad esempio carbonio, idrogeno, ossigeno, azoto, fosforo, zolfo, ecc.) sono collegati tra loro tramite legami chimici. Un altro esempio è la struttura 3D delle proteine, composta da aminoacidi collegati tra loro tramite legami peptidici. Questo lungo tratto di amminoacidi è noto come peptide e si ripiega tridimensionalmente per formare “pieghe” uniche che hanno un ruolo strutturale e funzionale. In effetti, il recente AlphaFold 2 sviluppato da DeepMind ha stabilito un record riuscendo a prevedere modelli strutturali di proteine direttamente dalla sequenza di aminoacidi della proteina (cioè la composizione aminoacidica della proteina di interesse).
A proposito di AlphaFold 2, date un’occhiata ai miei due video brevi su YouTube:
– Deepmind’s Alphafold2 risolve le strutture proteiche (Parte 1)
– Deepmind’s Alphafold2 risolve le strutture proteiche (Parte 2)
Proseguendo con l’esempio dei modelli proteici, ci si può chiedere:
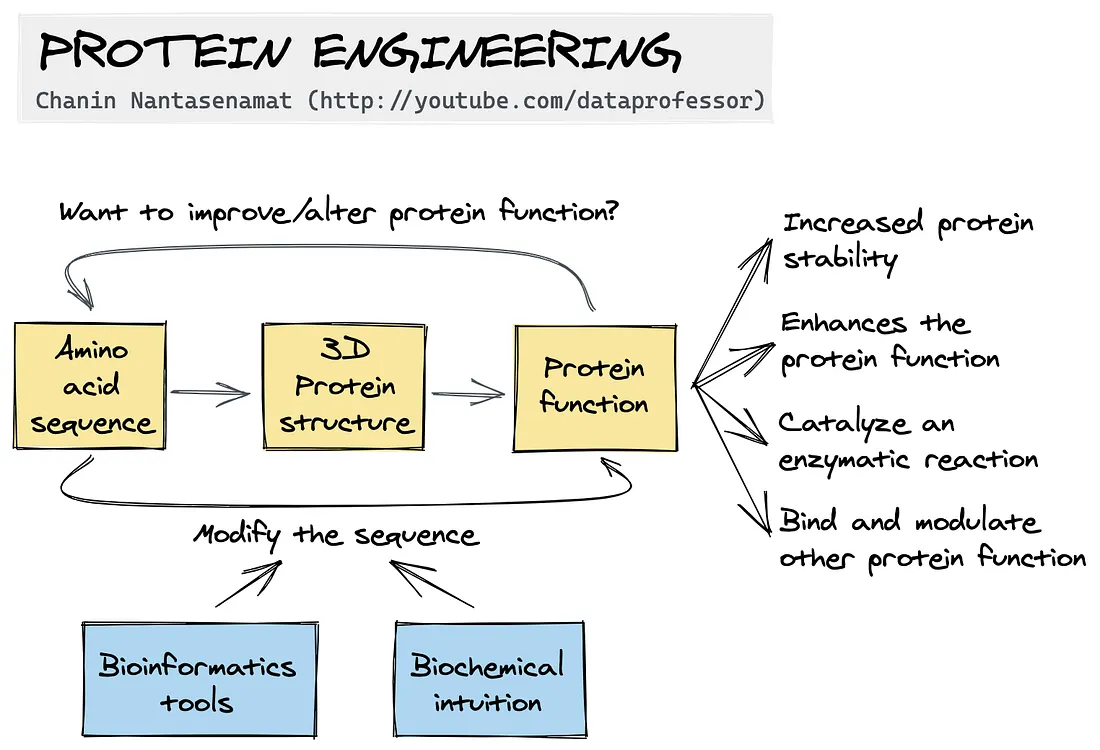
Perché abbiamo bisogno di prevedere le strutture proteiche?
La funzione della proteina è determinata dalla sua struttura proteica 3D, che a sua volta è dettata dalla sua sequenza di amminoacidi. Pertanto, la capacità di prevedere la struttura delle proteine ha un’utilità immensa per aiutare gli scienziati a comprenderne la funzione. In effetti, esiste una disciplina delle scienze della vita nota come ingegneria delle proteine che, come dice il nome, si occupa dell’ingegnerizzazione delle proteine. Come si ingegnerizza una proteina? Ciò avviene attraverso l’uso dell’intuizione biochimica (esperienza e ipotesi) e di strumenti bioinformatici (come PyMOL per visualizzare il modello molecolare della struttura 3D della proteina).