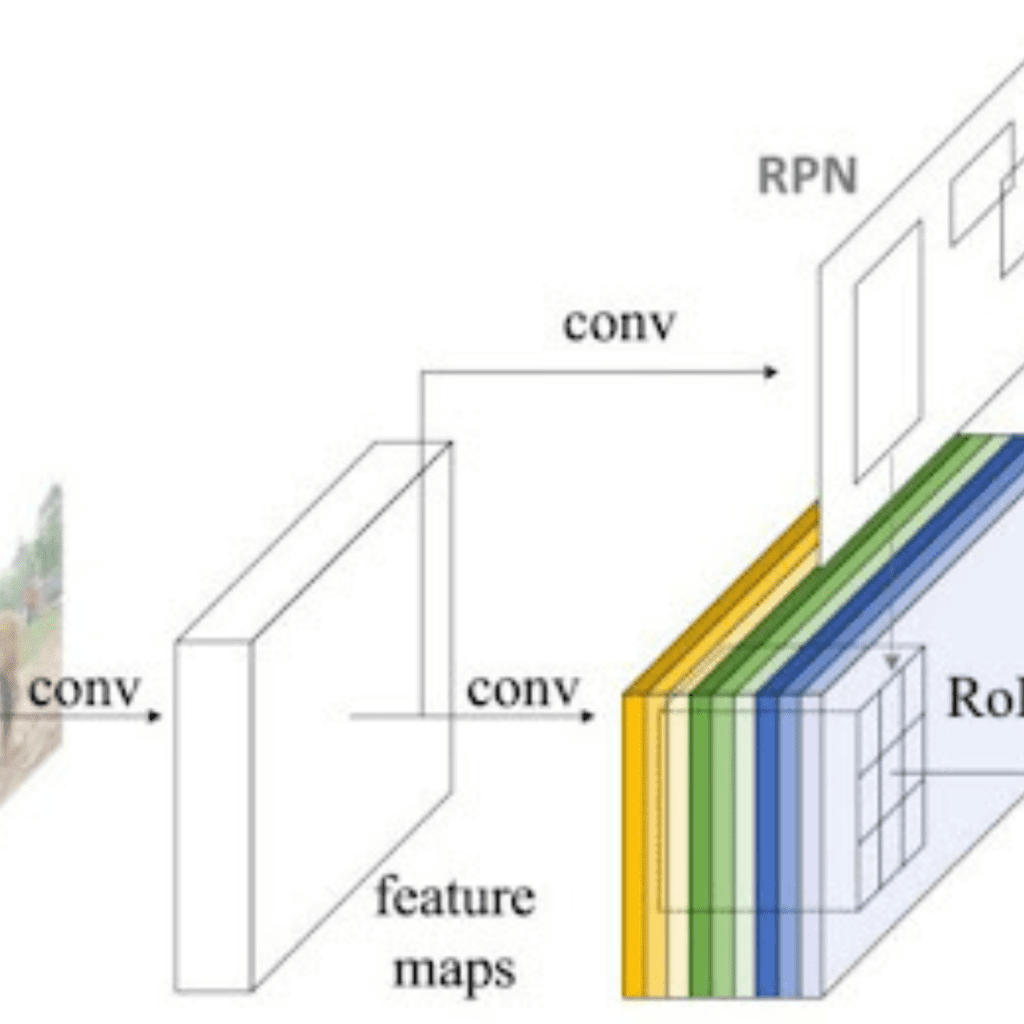
Con l’aumento dei veicoli autonomi, della videosorveglianza intelligente, del rilevamento facciale e di varie applicazioni di conteggio delle persone, i sistemi di rilevamento degli oggetti veloci e accurati sono sempre più richiesti. Questi sistemi prevedono non solo il riconoscimento e la classificazione di ogni oggetto presente in un’immagine, ma anche la localizzazione di ciascuno di essi disegnando il riquadro di delimitazione appropriato intorno ad esso. Ciò rende il rilevamento degli oggetti un compito significativamente più difficile rispetto al suo predecessore tradizionale di computer vision, la classificazione delle immagini.
Fortunatamente, però, gli approcci di maggior successo al rilevamento degli oggetti sono attualmente estensioni dei modelli di classificazione delle immagini. Qualche mese fa, Google ha rilasciato una nuova API di rilevamento degli oggetti per Tensorflow. Con questa release sono state rilasciate le architetture e i pesi precostituiti per alcuni modelli specifici:
– Rilevatore Multibox a colpo singolo (SSD) con MobileNets
– SSD con Inception V2
– Reti completamente convoluzionali basate su regioni (R-FCN) con Resnet 101
– RCNN più veloce con Resnet 101
– RCNN più veloci con Inception Resnet v2
Nel mio ultimo post sul blog, ho illustrato l’intuizione alla base delle tre architetture di rete di base sopra elencate: MobileNets, Inception e ResNet. Questa volta voglio fare lo stesso per i modelli di rilevamento degli oggetti di Tensorflow: Faster R-CNN, R-FCN e SSD. Alla fine di questo post, speriamo di aver compreso come il deep learning viene applicato al rilevamento degli oggetti e come questi modelli di rilevamento degli oggetti si ispirano e si discostano l’uno dall’altro.
R-CNN è il nonno di Faster R-CNN. In altre parole, R-CNN ha dato il via a tutto.
La R-CNN, o Rete neurale convoluzionale basata su regioni, consisteva in 3 semplici passaggi:
- Eseguire una scansione dell’immagine di ingresso alla ricerca di possibili oggetti utilizzando un algoritmo chiamato Ricerca selettiva, generando circa 2000 proposte di regioni.
- Eseguire una rete neurale convoluzionale (CNN) su ciascuna di queste proposte di regione.
- Prendere l’output di ogni CNN e inserirlo a) in un SVM per classificare la regione e b) in un regressore lineare per restringere il rettangolo di gioco dell’oggetto, se questo esiste.
Queste tre fasi sono illustrate nell’immagine seguente:
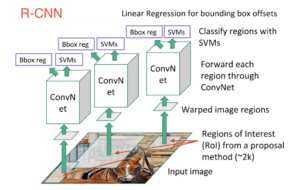
In altre parole, prima proponiamo le regioni, poi estraiamo le caratteristiche e infine classifichiamo le regioni in base alle loro caratteristiche. In sostanza, abbiamo trasformato il rilevamento degli oggetti in un problema di classificazione delle immagini. R-CNN era molto intuitivo, ma molto lento.
Il discendente immediato di R-CNN era Fast-R-CNN. Fast R-CNN assomigliava in molti aspetti all’originale, ma migliorava la sua velocità di rilevamento grazie a due principali miglioramenti:
- Esecuzione dell’estrazione delle caratteristiche sull’immagine prima di proporre le regioni, quindi esecuzione di una sola CNN sull’intera immagine invece di 2000 CNN su 2000 regioni sovrapposte.
- Sostituzione della SVM con uno strato softmax, estendendo così la rete neurale per le previsioni invece di creare un nuovo modello.
Il nuovo modello si presentava come segue:
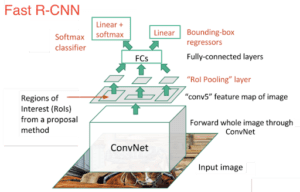
Come si può vedere dall’immagine, ora stiamo generando proposte di regioni basate sull’ultima mappa di caratteristiche della rete, non sull’immagine originale. Di conseguenza, possiamo addestrare una sola CNN per l’intera immagine.
Inoltre, invece di addestrare molti SVM diversi per classificare ogni classe di oggetti, c’è un singolo strato softmax che emette direttamente le probabilità di classe. Ora abbiamo una sola rete neurale da addestrare, invece di una rete neurale e molte SVM.
La R-CNN veloce si è comportata molto meglio in termini di velocità. Rimaneva solo un grosso collo di bottiglia: l’algoritmo di ricerca selettiva per la generazione delle proposte di regioni.
A questo punto, siamo tornati al nostro obiettivo iniziale: R-CNN più veloce. L’intuizione principale di Faster R-CNN è stata quella di sostituire il lento algoritmo di ricerca selettiva con una rete neurale veloce. In particolare, ha introdotto la rete a proposta di regione (RPN).
Ecco come funziona la RPN:
– All’ultimo livello di una CNN iniziale, una finestra scorrevole 3×3 si muove attraverso la mappa delle caratteristiche e la mappa in una dimensione inferiore (ad esempio 256-d).
– Per ogni posizione della finestra scorrevole, genera più regioni possibili basate su k caselle di ancoraggio a rapporto fisso (caselle di delimitazione predefinite).
– Ogni proposta di regione consiste in a) un punteggio di “objectness” per quella regione e b) 4 coordinate che rappresentano il riquadro di delimitazione della regione.
In altre parole, consideriamo ogni posizione nella nostra ultima mappa delle caratteristiche e consideriamo k diverse caselle centrate intorno ad essa: una casella alta, una casella larga, una casella grande, ecc. Per ognuna di queste caselle, si indica se si ritiene che contenga o meno un oggetto e quali sono le coordinate di quella casella. Ecco come appare in una posizione della finestra scorrevole:
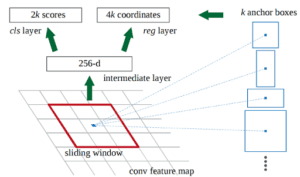
I 2k punteggi rappresentano la probabilità softmax che ciascuna delle k bounding box sia un “oggetto”. Si noti che, sebbene la RPN fornisca le coordinate delle caselle di delimitazione, non cerca di classificare alcun oggetto potenziale: il suo unico compito è ancora quello di proporre regioni di oggetti. Se un riquadro di ancoraggio ha un punteggio di “objectness” superiore a una certa soglia, le coordinate di quel riquadro vengono trasmesse come proposta di regione.
Una volta ottenute le proposte di regioni, le inseriamo direttamente in quella che è essenzialmente una R-CNN veloce. Aggiungiamo uno strato di pooling, alcuni strati completamente connessi e infine uno strato di classificazione softmax e un regressore di bounding box. In un certo senso, Faster R-CNN = RPN + Fast R-CNN.
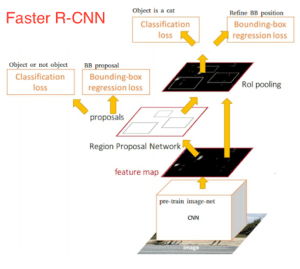
Complessivamente, Faster R-CNN ha raggiunto velocità molto migliori e un’accuratezza all’avanguardia. Vale la pena notare che, sebbene i modelli futuri abbiano fatto molto per aumentare la velocità di rilevamento, pochi modelli sono riusciti a superare Faster R-CNN con un margine significativo. In altre parole, Faster R-CNN può non essere il metodo più semplice o veloce per il rilevamento degli oggetti, ma è comunque uno dei più performanti. Per esempio, Faster R-CNN con Inception ResNet di Tensorflow è il modello più lento ma più accurato.
In fin dei conti, Faster R-CNN può sembrare complicato, ma il suo progetto di base è lo stesso dell’R-CNN originale: ipotizzare le regioni degli oggetti e poi classificarle. Questa è oggi la pipeline predominante per molti modelli di rilevamento degli oggetti, compreso il nostro prossimo.
Ricordate che Fast R-CNN ha migliorato la velocità di rilevamento dell’originale condividendo un singolo calcolo CNN per tutte le proposte di regioni? Questo tipo di pensiero è stato anche la motivazione alla base di R-FCN: aumentare la velocità massimizzando la computazione condivisa.
R-FCN, o Region-based Fully Convolutional Net, condivide il 100% dei calcoli su ogni singola uscita. Essendo completamente convoluzionale, ha incontrato un problema unico nella progettazione del modello.
Da un lato, quando si esegue la classificazione di un oggetto, si vuole apprendere l’invarianza della posizione in un modello: indipendentemente dal punto in cui il gatto appare nell’immagine, vogliamo classificarlo come un gatto. Dall’altro lato, quando si esegue il rilevamento dell’oggetto, si vuole apprendere la varianza di posizione: se il gatto si trova nell’angolo in alto a sinistra, vogliamo disegnare una casella nell’angolo in alto a sinistra. Quindi, se cerchiamo di condividere le computazioni convoluzionali sul 100% della rete, come possiamo trovare un compromesso tra invarianza di posizione e varianza di posizione?
La soluzione di R-FCN: mappe di punteggio sensibili alla posizione.
Ogni mappa di punteggio sensibile alla posizione rappresenta una posizione relativa di una classe di oggetti. Ad esempio, una mappa di punteggio potrebbe attivarsi quando rileva la parte superiore destra di un gatto. Un’altra mappa di punteggio potrebbe attivarsi quando vede la parte inferiore sinistra di un’auto. Avete capito bene. In sostanza, queste mappe di punteggio sono mappe di caratteristiche convoluzionali che sono state addestrate per riconoscere determinate parti di ogni oggetto.
Ora, R-FCN funziona come segue:
- Eseguire una CNN (in questo caso, ResNet) sull’immagine di ingresso.
- Aggiunge uno strato completamente convoluzionale per generare un banco di punteggi delle suddette “mappe di punteggio sensibili alla posizione”. Dovrebbero esserci k²(C+1) mappe di punteggio, con k² che rappresenta il numero di posizioni relative in cui dividere un oggetto (ad esempio, 3² per una griglia 3 per 3) e C+1 che rappresenta il numero di classi più lo sfondo.
- Eseguire una rete proposta di regioni completamente convoluzionale (RPN) per generare regioni di interesse (RoI).
- Per ogni RoI, dividerla negli stessi “bins” o sottoregioni k² delle mappe di punteggio.
- Per ogni bin, controllare la banca dei punteggi per vedere se quel bin corrisponde alla posizione corrispondente di qualche oggetto. Ad esempio, se mi trovo nel bin “alto-sinistro”, prenderò le mappe di punteggio che corrispondono all’angolo “alto-sinistro” di un oggetto e farò la media di questi valori nella regione RoI. Questo processo viene ripetuto per ogni classe.
- Una volta che ognuno dei k² bins ha un valore di “corrispondenza dell’oggetto” per ogni classe, si fa la media dei bins per ottenere un singolo punteggio per classe.
- Classificare il RoI con un softmax sul vettore dimensionale C+1 rimanente.
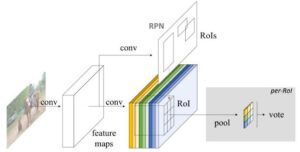
Complessivamente, R-FCN si presenta come segue, con una RPN che genera i RoI:
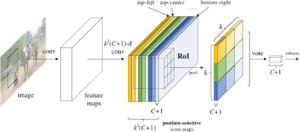
Anche con la spiegazione e l’immagine, potreste essere ancora un po’ confusi sul funzionamento di questo modello. Onestamente, R-FCN è molto più facile da capire quando si può visualizzare ciò che sta facendo. Ecco un esempio pratico di R-FCN che rileva un bambino:

In poche parole, R-FCN considera ogni proposta di regione, la divide in sottoregioni e itera sulle sottoregioni chiedendo: “questa assomiglia alla parte superiore sinistra di un bambino?”, “questa assomiglia alla parte superiore centrale di un bambino?”. “assomiglia alla parte superiore destra di un bambino?”, ecc. Ripete questa operazione per tutte le possibili classi. Se un numero sufficiente di sottoregioni dice “sì, sono compatibile con quella parte di un bambino!”, il RoI viene classificato come bambino dopo un softmax su tutte le classi.
Con questa configurazione, R-FCN è in grado di affrontare contemporaneamente la varianza della posizione proponendo diverse regioni di oggetti e l’invarianza della posizione facendo sì che ogni proposta di regione faccia riferimento alla stessa banca di mappe di punteggio. Queste mappe di punteggio dovrebbero imparare a classificare un gatto come un gatto, indipendentemente dal luogo in cui appare. Inoltre, è completamente convoluzionale, il che significa che tutti i calcoli sono condivisi nella rete.
Di conseguenza, R-FCN è diverse volte più veloce di Faster R-CNN e raggiunge un’accuratezza paragonabile.
Il nostro ultimo modello è SSD, acronimo di Single-Shot Detector. Come R-FCN, offre enormi guadagni di velocità rispetto a Faster R-CNN, ma lo fa in modo nettamente diverso.
I nostri primi due modelli eseguivano la proposta e la classificazione delle regioni in due fasi distinte. In primo luogo, utilizzavano una rete di proposta di regioni per generare regioni di interesse; successivamente, utilizzavano strati completamente connessi o strati convoluzionali sensibili alla posizione per classificare tali regioni. SSD esegue queste due operazioni in un “colpo solo”, prevedendo contemporaneamente il rettangolo di selezione e la classe di appartenenza mentre elabora l’immagine.
Concretamente, data un’immagine di input e un insieme di etichette di verità a terra, SSD esegue le seguenti operazioni:
- Passa l’immagine attraverso una serie di livelli convoluzionali, ottenendo diverse serie di mappe di caratteristiche a diverse scale (ad esempio, 10×10, poi 6×6, poi 3×3, ecc.).
- Per ogni posizione in ciascuna di queste mappe di caratteristiche, utilizzare un filtro convoluzionale 3×3 per valutare un piccolo insieme di rettangoli di selezione predefiniti. Queste caselle di delimitazione predefinite sono essenzialmente equivalenti alle caselle di ancoraggio di Faster R-CNN.
- Per ogni casella, prevedere simultaneamente a) l’offset della casella di delimitazione e b) le probabilità della classe.
- Durante l’addestramento, si fa corrispondere la casella di verità a terra con queste caselle previste in base all’IoU. Il riquadro meglio previsto sarà etichettato come “positivo”, insieme a tutti gli altri riquadri che hanno un IoU con la verità >0,5.
Il modello SSD sembra semplice, ma la sua formazione presenta una sfida unica. Con i due modelli precedenti, la rete di proposte regionali assicurava che tutto ciò che si cercava di classificare avesse una probabilità minima di essere un “oggetto”. Con l’SSD, invece, saltiamo questa fase di filtraggio. Classifichiamo e disegniamo i riquadri di delimitazione da ogni singola posizione nell’immagine, utilizzando più forme diverse, a diverse scale. Di conseguenza, generiamo un numero molto maggiore di riquadri di delimitazione rispetto agli altri modelli, e quasi tutti sono esempi negativi.
Per risolvere questo squilibrio, SSD agisce in due modi. In primo luogo, utilizza la soppressione non massima per raggruppare in un unico riquadro riquadri altamente sovrapposti. In altre parole, se quattro scatole di forma, dimensioni e così via simili contengono lo stesso cane, NMS tiene quella con la fiducia più alta e scarta le altre. In secondo luogo, il modello utilizza una tecnica chiamata hard negative mining per bilanciare le classi durante l’addestramento. Nell’hard negative mining, a ogni iterazione dell’addestramento viene utilizzato solo un sottoinsieme degli esempi negativi con la perdita di addestramento più elevata (cioè i falsi positivi). SSD mantiene un rapporto di 3:1 tra negativi e positivi.
La sua architettura è la seguente:
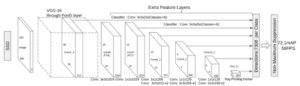
Come ho già detto, alla fine ci sono “livelli di caratteristiche extra” che si riducono di dimensione. Queste mappe di caratteristiche di dimensioni variabili aiutano a catturare oggetti di dimensioni diverse. Ad esempio, ecco l’SSD in azione:
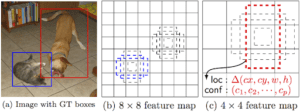
Nelle mappe di caratteristiche più piccole (ad esempio, 4×4), ogni cella copre una regione più ampia dell’immagine, consentendo di rilevare oggetti più grandi. La proposta di regioni e la classificazione vengono eseguite simultaneamente: date p classi di oggetti, ogni casella di delimitazione è associata a un vettore (4+p)-dimensionale che fornisce 4 coordinate di offset della casella e p probabilità di classe. Nell’ultima fase, viene nuovamente utilizzato softmax per classificare l’oggetto.
In definitiva, SSD non è molto diverso dai primi due modelli. Salta semplicemente la fase di “proposta della regione”, considerando invece ogni singola bounding box in ogni posizione dell’immagine contemporaneamente alla sua classificazione. Dato che SSD fa tutto in un colpo solo, è il più veloce dei tre modelli, ma ha comunque prestazioni abbastanza comparabili.
Un altro modello one-shot oltre a SSD è YOLO. Lo trattiamo anche nel nostro corso sulla Computer Vision, insieme alle altre reti per Object Detection.