
“Oh mio pelo e miei baffi! Sono in ritardo, sono in ritardo, sono in ritardo!”. (da https://commons.wikimedia.org/wiki/File:The_White_Rabbit_(Tenniel)_-_Il_Nursery_Alice_(1890)_-_BL.jpg, Creative Commons CC0 1.0 Pubblico Dominio Universale Dedicato)
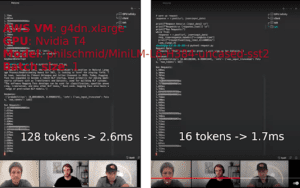
Recentemente, 🤗 Hugging Face (la startup dietro la libreria dei transformers) ha rilasciato un nuovo prodotto chiamato “Infinity”. Viene descritto come un server per eseguire inferenze su “scala aziendale”. Una demo pubblica è disponibile su YouTube (di seguito trovate gli screenshot con i tempi e la configurazione utilizzata durante la demo).
Se, però, non sapete bene di cosa stiamo parlando né cosa sia HuggingFace, nel nostro corso di Natural Language Processing Hands-On (1) potrete sicuramente imparare di più sull’argomento 😉
La comunicazione riguarda la promessa che il prodotto può eseguire l’inferenza Transformer con una latenza di 1 millisecondo sulla GPU. Secondo il presentatore della demo, il server Hugging Face Infinity costa almeno 💰20 000$/anno per un singolo modello distribuito su una singola macchina (non sono disponibili informazioni pubbliche sulla scalabilità dei prezzi).
Mi è venuta la curiosità di scavare un po’ e verificare se fosse possibile raggiungere quelle prestazioni con la stessa macchina virtuale/modello/ingresso AWS utilizzata nella demo (vedi screenshot sotto per i dettagli), utilizzando strumenti open source di Microsoft e Nvidia? Spoiler: sì, e con questo tutorial è facile da riprodurre e adattare ai vostri progetti REAL LIFE.
💻 Il codice sorgente del progetto è disponibile a questo indirizzo:
https://github.com/ELS-RD/transformer-deploy
Il README fornisce istruzioni su come eseguire il codice ed è stato testato sia su una macchina viruale AWS con la versione 44 dell’immagine di deep learning sia su un server bare metal con una GPU Nvidia 3090 (le misure pubblicate nell’articolo provengono dalla macchina AWS).
Lavoro presso Lefebvre Sarrut R&D, uno dei principali editori giuridici europei, e il mio team ha messo in produzione un bel po’ di modelli, tra cui diversi trasformatori, da piccoli modelli distillati a modelli di grandi dimensioni, per eseguire una serie di compiti su documenti legali. Alcuni di questi lavori sono stati descritti qui e là.
In questo articolo vedremo come implementare un modello NLP moderno in un contesto industriale. Esistono decine di tutorial sull’argomento, ma, per quanto ne so, non sono rivolti alla produzione e non trattano le prestazioni, la scalabilità, il disaccoppiamento dei compiti della CPU e della GPU o il monitoraggio della GPU. Alcuni di essi sono simili a: 1/ prendere il server HTTP FastAPI, 2/ aggiungere Pytorch e voilà 🤪
Se avete contenuti interessanti che volete che vi linki, postateli nei commenti…
Lo scopo di questo tutorial è spiegare come ottimizzare pesantemente un trasformatore di Hugging Face e distribuirlo su un server di inferenza pronto per la produzione, da capo a fondo. Potete trovare alcuni contenuti interessanti e tecnici di Nvidia e Microsoft su alcune parti specifiche di questo processo.
L’articolo più simile e di ispirazione per me è questo. Mancano ancora due punti critici: un’ottimizzazione significativa e la tokenizzazione sul lato del server di inferenza (altrimenti non è possibile chiamare facilmente il server di inferenza al di fuori di Python). Ci occuperemo di questi due punti.
Il miglioramento delle prestazioni apportato da questo processo si applica a tutti gli scenari, dalle sequenze brevi a quelle lunghe, da un batch di dimensione 1 a batch di grandi dimensioni. Quando l’architettura è conforme alle aspettative degli strumenti, il processo porta sempre un significativo aumento delle prestazioni rispetto a PyTorch puro.
Il processo si articola in 3 fasi:
– Convertire il modello Pytorch in un grafo
– Ottimizzare il grafo
– Distribuire il grafo su un server di inferenza performante
Alla fine confronteremo le prestazioni del nostro server di inferenza con i numeri mostrati da Hugging Face durante la demo e vedremo che siamo più veloci sia per le sequenze di input a 16 che a 128 tokens con batch size 1 (per quanto ne so, Hugging Face non ha condiviso pubblicamente informazioni su altri scenari).
Ma soprattutto, un maggior numero di professionisti dell’apprendimento automatico sarà in grado di fare qualcosa di molto più affidabile che distribuire un modello Pytorch pronto per l’uso su un server HTTP dedicato senza interferenze.
Probabilmente lo sapete, il grande punto di forza di Pytorch rispetto a Tensorflow 1.X è stata la sua facilità d’uso: invece di costruire un grafico, basta scrivere codice imperativo familiare. Sembra di scrivere codice numpy eseguito alla velocità della GPU.
Rendere felici gli utenti è fantastico, ma ciò che è ancora più fantastico è rendere felici anche gli strumenti di ottimizzazione. A differenza degli esseri umani, questi strumenti amano i grafici per eseguire analisi (a volte offline). È logico, i grafici forniscono una visione statica e completa dell’intero processo, dal punto dati all’output del modello. Inoltre, il grafo fornisce una rappresentazione intermedia che può essere comune a diversi framework di apprendimento automatico.
Abbiamo bisogno di un modo per convertire il nostro codice Pytorch imperativo in un grafo. Esistono diverse opzioni, ma quella che ci interessa si chiama ONNX. “ONNX è un formato aperto costruito per rappresentare modelli di apprendimento automatico. ONNX definisce un insieme comune di operatori – gli elementi costitutivi dei modelli di machine learning e deep learning – e un formato di file comune per consentire agli sviluppatori di AI di utilizzare i modelli con una varietà di framework, strumenti, runtime e compilatori.” (https://onnx.ai/). Il formato è stato inizialmente creato da Facebook e Microsoft per creare un ponte tra Pytorch (ricerca) e Caffee2 (produzione).
Pytorch include uno strumento di esportazione in ONNX. Il principio alla base dello strumento di esportazione è abbastanza semplice, useremo la modalità “tracing”: inviamo alcuni dati (fittizi) al modello e lo strumento li traccerà all’interno del modello, in modo da indovinare l’aspetto del grafico.
La modalità di tracciamento non è magica, per esempio non può vedere le operazioni che si stanno facendo in numpy (se ce ne sono), il grafico sarà statico, alcuni codici if/else saranno fissi per sempre, il ciclo for sarà srotolato, ecc. Non è un grosso problema perché Hugging Face e gli autori dei modelli hanno fatto in modo che la maggior parte dei modelli sia compatibile con la modalità di tracciamento.
Per vostra informazione, esiste un’altra modalità di esportazione chiamata “scripting” che richiede che i modelli siano scritti in un certo modo per funzionare; il suo principale vantaggio è che la logica dinamica viene mantenuta intatta, ma avrebbe aggiunto troppi vincoli nel modo in cui i modelli sono scritti senza alcun evidente guadagno di prestazioni.
Il codice commentato che segue esegue la conversione ONNX:
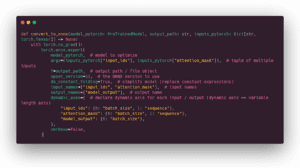
Un punto particolare è che dichiariamo alcuni assi come dinamici. Se non lo facessimo, il grafico accetterebbe solo tensori con la stessa forma di quelli che stiamo usando per costruirlo (i dati fittizi), quindi la lunghezza della sequenza o la dimensione del lotto sarebbero fisse. I nomi che abbiamo dato ai campi di input e output saranno riutilizzati in altri strumenti.
Si noti che l’esportazione di ONNX funziona anche per l’estrazione di caratteristiche come avviene nella libreria sentence-transformers, ma in questo caso richiede alcuni piccoli accorgimenti.
🥳 Félicitations, sapete come avere un grafico pronto per essere ottimizzato!
Ci concentreremo su due strumenti per ottimizzare i modelli Pytorch: ONNX Runtime di Microsoft (open source con licenza MIT) e TensorRT di Nvidia (open source con licenza Apache 2, il motore di ottimizzazione è closed source).
Possono funzionare da soli o insieme. Nel nostro caso, li utilizzeremo insieme, cioè usando TensorRT attraverso l’API ONNX Runtime.
> #consiglio: se volete sembrare un MLOps, non dite ONNX Runtime / TensorRT, ma ORT e TRT. Inoltre, è possibile trovare questi nomi in Github issues/PR.
Entrambi gli strumenti eseguono lo stesso tipo di operazioni per ottimizzare il modello ONNX:
– trovare e rimuovere le operazioni ridondanti: ad esempio, il dropout non ha alcuna utilità al di fuori del ciclo di addestramento e può essere rimosso senza alcun impatto sull’inferenza;
– eseguire il folding delle costanti: significa trovare alcune parti del grafo costituite da espressioni costanti e calcolare i risultati a tempo di compilazione invece che a tempo di esecuzione (in modo simile alla maggior parte dei compilatori di linguaggi di programmazione);
– unire alcune operazioni insieme: per evitare 1/ tempi di caricamento e 2/ condividere la memoria per evitare trasferimenti avanti e indietro con la memoria globale. Ovviamente, ciò andrà a vantaggio soprattutto delle operazioni legate alla memoria (come le operazioni di moltiplicazione e di addizione, uno schema molto comune nel deep learning), si chiama “kernel fusion”;
Possono opzionalmente convertire i pesi del modello in rappresentazioni più leggere una volta per tutte (da float a 32 bit a float a 16 bit o persino a interi a 8 bit in caso di quantizzazione).
Netron può produrre una visualizzazione del grafico ONNX prima e dopo l’ottimizzazione:
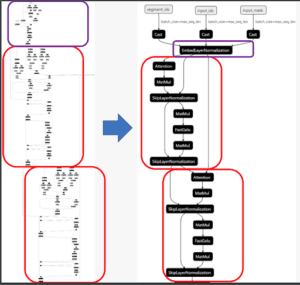
Entrambi gli strumenti presentano alcune differenze fondamentali, le principali delle quali sono:
– Facilità d’uso: TensorRT è stato costruito per utenti avanzati, i dettagli dell’implementazione non sono nascosti dalla sua API che è principalmente orientata al C++ (compreso il wrapper Python che funziona esattamente come l’API C++, il che può essere sorprendente se non si è esperti di C++). D’altra parte, la documentazione di ONNX Runtime è facile da capire anche se non si è esperti di hardware per l’apprendimento automatico, offre un’API Pythonic e molti esempi in questo linguaggio, e si possono trovare più esempi e strumenti dedicati all’NLP.
– Portata delle ottimizzazioni: TensorRT di solito fornisce le migliori prestazioni. Il processo è un po’ complicato, non fornirò dettagli in questa sede, ma fondamentalmente si costruiscono “profili” per diverse associazioni di hardware, modelli e forme di dati. TensorRT esegue alcuni benchmark sull’hardware per trovare la migliore combinazione di ottimizzazioni (un modello è quindi collegato a un hardware specifico). A volte è un po’ troppo aggressivo, in particolare in caso di precisione mista, e l’accuratezza del modello del trasformatore può diminuire. Per finire, aggiungiamo che il processo è non deterministico perché dipende dal tempo di esecuzione del kernel. Per farla breve, possiamo dire che le prestazioni aggiunte da TensorRT hanno un costo in termini di curva di apprendimento. ONNX Runtime dispone di due tipi di ottimizzazioni, quelle dette “on-line” che vengono applicate automaticamente subito dopo il caricamento del modello (basta usare un flag), e quelle “offline” che sono specifiche per alcuni modelli, in particolare per quelli basati su trasformatori. Le utilizzeremo in questo articolo. A seconda del modello, dei dati e dell’hardware, ONNX Runtime + le ottimizzazioni offline sono a volte alla pari con TensorRT, altre volte ho visto TensorRT fino al 33% più veloce su scenari reali. L’API di TensorRT è più completa di quella esposta da ONNX Runtime, ad esempio è possibile indicare la forma ottimale del tensore e fissare alcuni limiti sulle dimensioni, quindi genererà tutti i profili necessari. Se avete davvero bisogno delle migliori prestazioni, dovete imparare l’API TensorRT.
– Più backend: ONNX Runtime ha i propri motori di inferenza CUDA e CPU, ma può anche delegare l’inferenza a backend di terze parti… inclusi TensorRT, TVM o openVINO! In questi casi, ONNX Runtime è un’API piacevole e ben documentata per sfruttare uno strumento più complesso. Sapete cosa vi dico? Lo testeremo di seguito!
– Obiettivi hardware multipli: TensorRT è dedicato all’hardware Nvidia (molte GPU e Jetson), ONNX Runtime si rivolge alle GPU (Nvidia CUDA e AMD RocM), alle CPU, all’edge computing, compresa la distribuzione via browser, ecc.
Nel caso in cui non l’abbiate capito, ONNX Runtime è un’API sufficiente per la maggior parte dei lavori di inferenza.
Per quanto riguarda le architetture di trasformazione supportate, potete avere un’idea di base di ciò che ONNX Runtime è in grado di fare consultando questa pagina. Include Bert, Roberta, GPT-2, XLM, layoutlm, Bart, T5, ecc. Per quanto riguarda TensorRT, ho provato molte architetture senza alcun problema, ma per quanto ne so, non esiste un elenco di modelli testati. Almeno si possono trovare notebook T5 e GPT-2, con un’inferenza fino a X5 più veloce rispetto a Pytorch vanilla.
Secondo questo README, Nvidia sta lavorando duramente per facilitare l’accelerazione dei trasformatori sul suo framework e questa è un’ottima notizia per tutti noi!
Come detto in precedenza, alcune ottimizzazioni vengono applicate subito dopo il caricamento del modello in memoria. Esiste anche la possibilità di applicare alcune ottimizzazioni più profonde durante l’analisi statica del grafo, in modo che sia più facile gestire l’asse della dinamica o eliminare alcuni nodi di fusione non necessari. Inoltre, per cambiare la precisione del modello (da FP32 a FP16) è necessario essere offline. Consultate questa guida per saperne di più su queste ottimizzazioni.
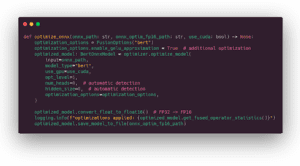
ONNX Runtime offre queste possibilità nella sua cartella degli strumenti. Sono supportate la maggior parte delle architetture classiche dei trasformatori e include miniLM. È possibile eseguire le ottimizzazioni tramite la riga di comando:
python -m onnxruntime.transformers.optimizer …
Nel nostro caso, le eseguiremo nel codice Python per avere un unico comando da eseguire. Nel codice che segue, abilitiamo tutte le ottimizzazioni possibili ed eseguiamo una conversione a 16 precisione float.
Una parte del miglioramento delle prestazioni deriva da alcune approssimazioni eseguite a livello CUDA: sul livello di attivazione (GELU) e sul livello della maschera di attenzione. Queste approssimazioni possono avere un piccolo impatto sui risultati del modello. Secondo la mia esperienza, l’effetto sull’accuratezza del modello è minore rispetto all’uso di un seme diverso durante l’addestramento.
Per quanto riguarda TensorRT, non ci sono ottimizzazioni offline, ma nella documentazione di ONNX Runtime si consiglia di eseguire l’inferenza simbolica della forma sul modello ONNX di base. Questo è utile perché può accadere che ONNX Runtime divida il grafo in diversi sottografi e per questo motivo le informazioni sulla forma (tensoriale) vanno perse per TensorRT. L’inferenza simbolica della forma restituirà le informazioni ovunque siano necessarie. E se, come me, vi state chiedendo perché si chiama simbolica, è perché eseguirà davvero il calcolo simbolico con una lib di Python chiamata sympy dedicata al… calcolo simbolico in generale.
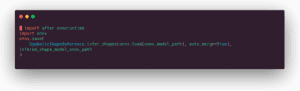
Ok, ora è il momento di fare un benchmark. A tale scopo utilizzeremo una semplice funzione decoratrice per memorizzare ogni temporizzazione. Il resto del codice è abbastanza semplice. Le misure alla fine dello script vengono eseguite con 16 token in ingresso (come una delle misure della demo Infinity).
Results below:

💨 0,64 ms per TensorRT (prima riga) e 0,63 ms per ONNX Runtime ottimizzato (terza riga), è quasi 10 volte più veloce di Pytorch vanilla! Siamo ben al di sotto dei limiti di 1 ms.
È interessante notare che su Pytorch la precisione a 16 bit (5,9 ms) è più lenta della precisione completa (5 ms). Ciò è dovuto al nostro input: non c’è batching, la sequenza è molto breve e, in fin dei conti, il casting da FP32 a FP16 aggiunge più overhead rispetto alla semplificazione del calcolo che comporta.
Naturalmente abbiamo verificato che tutti i risultati del modello siano simili (non saranno uguali a causa della piccola approssimazione, come spiegato sopra, e in più i diversi backend eseguono l’arrotondamento all’interno del grafico in modo leggermente diverso).
Al di fuori dei benchmark o di casi d’uso particolari, non capita tutti i giorni di eseguire l’inferenza su una singola sequenza di 16 token su un modello molto piccolo su una GPU, perché non sfrutta la forza principale della GPU. Inoltre, anche se le query vengono inviate come singole sequenze, la maggior parte dei server di inferenza seri ha una funzione per combinare le singole richieste di inferenza in batch. Lo scopo è quello di scambiare pochi millisecondi di latenza con un aumento del throughput, che potrebbe essere quello che state cercando quando cercate di ottimizzare il costo totale di proprietà dell’hardware.
A titolo informativo e non in relazione alla demo di Hugging Face, di seguito sono riportate le misure sulla stessa macchina virtuale (GPU T4) per bert-base-uncased, sequenza di 384 token e batch di dimensione 32 (sono parametri comuni che utilizziamo nei nostri casi d’uso presso Lefebvre Sarrut):
prestazioni su bert-base-uncased con batch di dati di grandi dimensioni (Immagine dell’autore)
Come si può notare, la riduzione della latenza apportata da TensorRT e ONNX Runtime è piuttosto significativa: la latenza di ONNX Runtime+TensorRT (4,72 ms) è più di 5 volte inferiore a quella di Pytorch FP32 vanilla (25,9 ms) ⚡️🏃🏻💨💨 ! Con TensorRT, al percentile 99, siamo ancora sotto la soglia dei 5 ms. Come previsto, in questo caso FP16 su Pytorch è circa 2 volte più veloce di FP32 e ONNX Runtime da solo (provider CUDA) svolge un buon lavoro, simile a quello del provider TensorRT.
Questi risultati non dovrebbero sorprenderci, poiché sembra che stiamo utilizzando lo stesso tooling di Hugging Face:
🍎 vs 🍎: 1° tentativo, ORT+FastAPI vs Hugging Face Infinity
Non sarebbe corretto confrontare i tempi della sezione precedente con quelli della demo di Hugging Face: non abbiamo alcuna comunicazione con il server, nessuna tokenizzazione, nessun overhead, eseguiamo solo l’inferenza.
Quindi, lo faremo di nuovo, ma questa volta con un semplice server HTTP: FastAPI (come nelle decine di contenuti di marketing che si possono trovare sui blog di startup di AI).
Si noti che, a prescindere dalle sue prestazioni, FastAPI non è una buona scelta di server di inferenza per la produzione, in quanto manca di cose fondamentali come il monitoraggio delle GPU, gli strumenti avanzati per le prestazioni ML, ecc.
The timing looks like that:

[sarcasm on] Whhhhhhhaaaaaat???? L’esecuzione dell’inferenza all’interno di fastAPI è 10 volte più lenta dell’inferenza locale? Che sorpresa, chi se lo sarebbe aspettato? [sarcasmo off]
Se controlliamo un noto benchmark di framework web, possiamo vedere che FastAPI non è così veloce rispetto ad altre opzioni di altri linguaggi. È persino tra i più lenti per quanto riguarda la latenza della singola query (oltre 38 volte più lento di fasthttp Go server). Questo non lo rende un cattivo software, ovviamente, è davvero un bello strumento da usare con la sua digitazione automatica, ecc. ma non è quello di cui abbiamo bisogno qui.
Hugging Face ha comunicato solo su sequenze molto brevi (16) e corte (128) con batch di dimensioni pari a 1. Il modello è ottimizzabile con strumenti disponibili, ma le prestazioni end-to-end non sono raggiungibili se rimaniamo nel mondo Python. In altri scenari (grandi lotti, lunghe sequenze), la differenza di pochi millisecondi potrebbe essere insignificante.
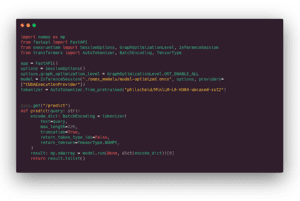
Fare inferenza su Triton è semplice. Fondamentalmente, è necessario preparare una cartella con il file ONNX che abbiamo generato e un file di configurazione come quello che segue, che fornisce una descrizione dei tensori di input e di output. Poi si lancia il contenitore Docker Triton… e il gioco è fatto!

2 commenti:
– max_batch_size: 0 significa nessun batching dinamico (la funzione avanzata per scambiare la latenza con il throughput descritta sopra).
-1 in forma significa asse dinamico, ovvero questa dimensione può cambiare da una query all’altra
Nel repo associato a questo articolo (link all’inizio), ci sono due script client Python, uno basato sulla libreria tritonclient (performante), uno basato sulla libreria requests (non performante ma utile come bozza se si ha bisogno di chiamare Triton al di fuori di Python) e una semplice chiamata curl (nel README del repository).
Il nostro script basato su tritonclient per interrogare il server di inferenza Triton:
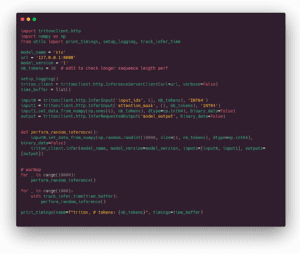
La piccola sottigliezza della libreria client è che prima si dichiarano le variabili di input e output e poi si caricano i dati in esse.
Si noti che il tensore degli id di input viene generato casualmente per ogni richiesta, per evitare qualsiasi effetto di cache (per quanto ne so, non c’è cache di default, ma è sempre bene controllare).
Risultati per una lunghezza di input di 16 (prima misura) e 128 token (seconda misura):

Siamo arrivati a qualcosa: sia per la sequenza di 16 che per quella di 128 token siamo ancora al di sotto della linea di base di Hugging Face. Il margine è piuttosto significativo nel caso di 128 token.
Stiamo ancora eseguendo i calcoli del modello puro sulla GPU, per avere qualcosa da confrontare con Hugging Face Infinity dobbiamo ancora spostare la parte di tokenizzazione sul server.
3/ Aggiungere la tokenizzazione sul lato server
Vi ho già detto che il server Nvidia Triton è fantastico? Lo è. Supporta diversi backend, tra cui uno chiamato “Python”. Nel backend Python possiamo richiamare codice Python libero, ad esempio per preparare i nostri dati (la tokenizzazione nel nostro caso).
Prima di implementare questa parte, è necessario installare i trasformatori nel contenitore Docker Triton. Per ulteriori informazioni, consultare il README del repository associato a questo articolo.
Come si presenta il codice Python:
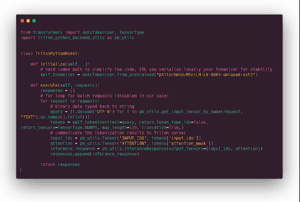
In pratica, c’è una sorta di funzione __init__() in cui si scarica il tokenizer e una executefunction per eseguire la tokenizzazione stessa. Il ciclo for è dovuto alla funzione di batching dinamico. Codice molto breve e semplice.
Abbiamo bisogno di una configurazione per dire a Triton cosa aspettarsi come input e output.

Ora vogliamo collegare il tokenizer al modello, abbiamo bisogno di una terza configurazione.

La prima parte dichiara l’input e l’output dell’intero processo, la seconda collega tutto insieme. In pratica, dice di ricevere una stringa, inviarla al tokenizer, ottenere l’output dal tokenizer e passarlo come input del modello, restituire l’output del modello.
Come già detto, la documentazione del server è ben scritta. È facile usare il tipo sbagliato, la dimensione sbagliata o inserire un errore di battitura nel nome del tensore: i messaggi di errore di Triton vi diranno esattamente cosa correggere e dove.
4/ 👀 benchmark finali!
Infine, è arrivato il momento del benchmark finale. Qui sotto potete vedere il nostro script client finale. La differenza principale rispetto al precedente script client è che ora ci rivolgiamo all’intero processo e non solo al modello. Non inviamo tensori interi ma solo la stringa (memorizzata in un array numpy che è il modo di comunicare con Triton).
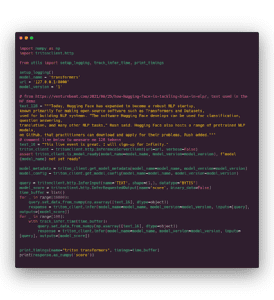
E le misure per 16 (prima misura) e 128 (seconda misura) gettoni:

🎯 Ce l’abbiamo fatta! 1,5 ms per 16 token (contro 1,7 ms su Hugging Face Infinity) e 2 ms per 128 token (contro 2,5 ms su Hugging Face Infinity).
Abbiamo costruito un server di inferenza veloce, pronto per essere distribuito nei nostri cluster. Ora potremo apprezzare il modo in cui il monitoraggio delle GPU rende più facile l’impostazione dell’autoscaling o il modo in cui strumenti maturi di misurazione delle prestazioni ci aiuteranno a risolvere i colli di bottiglia nelle nostre pipeline. E questo è assolutamente fantastico per i professionisti dell’apprendimento automatico, le startup e le aziende.
Quindi, cosa possiamo aspettarci dal futuro?
Conclusione
A differenza di quanto si legge su alcuni media, molti pensano che la comunità dell’apprendimento automatico sia ancora agli inizi. In particolare, viene ripetuto che la maggior parte dei progetti di machine learning non è mai stata messa in produzione, ma si tratta solo di contenuti di marketing e di post di appassionati di machine learning, come in Why 90 percent of all machine learning models never make into production o Why do 87% of data science projects never make into production? o Why ML Models Rarely Reaches Production and What You Can Do About it, ecc.
Ovviamente qualcuno ha usato GPT-9 per generare questi contenuti. Se sapete dove scaricare i pesi di GPT-9, mandatemi un PM 🙂
Dubito che qualcuno possa davvero misurarlo, ma di sicuro ci sono troppo pochi articoli seri sull’impiego dei modelli di PNL. Spero che questo articolo vi sia piaciuto e che, se ne avete il tempo, possiate condividere la vostra esperienza di ottimizzazione/dispiegamento con la comunità su Medium o altrove. Ci sono così tante altre cose importanti da risolvere in NLP, che l’implementazione di CPU/GPU non dovrebbe essere una sfida nel 2021.
Come comunità, abbiamo anche bisogno di una comunicazione adeguata da parte dei principali attori, anche quando si tratta di vendere prodotti alle aziende. Ad esempio, messaggi come “ci vogliono 2 mesi x 3 ingegneri ML altamente qualificati per implementare e accelerare i modelli BERT con una latenza di 20 ms” non tengono conto di dettagli tecnici fondamentali (modello, dimensioni dell’input, hardware), rendendo impossibile qualsiasi confronto. Inoltre, definire questi ingegneri “altamente qualificati” e non riuscire a raggiungere il loro obiettivo dopo mesi di lavoro implica paura, incertezza e dubbi sulla nostra capacità di fare lo stesso.
E per finire, abbiamo bisogno di più ottimizzazioni dell’inferenza per i modelli NLP negli strumenti open source!
All’epoca di bi-LSTM/GRU & friends, e per alcuni anni, era come se ci fosse un grande cambiamento di architettura ogni mese. Poi è arrivato transformer, che si è mangiato la maggior parte dei compiti di NLP. C’erano ancora alcune variazioni di architettura e la libreria Hugging Face Transformers è stata creata per aiutare i professionisti dell’apprendimento automatico a seguire la moda senza grandi investimenti nella riscrittura del codice.
Ho la sensazione che le architetture dei modelli si siano ormai stabilizzate e che la paura di perdere l’ultima architettura di tendenza stia diminuendo nella comunità.
Per dirla in modo diverso, se avete già nella vostra cassetta degli attrezzi una Roberta, un modello distillato come miniLM e un modello generativo come T5 o Bart, probabilmente siete a posto per la maggior parte dei casi d’uso industriali di NLP per 1 o 2 anni.
È una buona notizia per i professionisti dell’apprendimento automatico, perché questa stabilizzazione apre le porte a un maggiore impegno da parte di Microsoft, Intel, Nvidia e altri per ottimizzare i modelli NLP. La grande riduzione dei tempi di latenza o l’aumento del throughput non si tradurranno solo in un’inferenza a costi inferiori, ma anche in nuovi usi e nuovi prodotti. Possiamo anche sperare che un giorno potremo utilizzare quei modelli linguistici molto grandi (con centinaia di miliardi di parametri) che si suppone siano in grado di fare un sacco di cose fantastiche. Personalmente sono fiducioso che ciò accadrà, poiché è nell’interesse dei costruttori di hardware e dei fornitori di cloud sviluppare usi NLP, e hanno sia le risorse che le conoscenze per fare queste cose.
Articolo originale di Michaël Benesty
